 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Training of Mixture-of-Experts Models with Megatron Core
Mar 10, 2026Scaling Mixture-of-Experts (MoE) training introduces systems challenges absent in dense models. Because each token activates only a subset of experts, this sparsity allows total parameters to grow much faster than per-token computation, creating coupled constraints across memory, communication, and computation. Optimizing one dimension often shifts pressure to another, demanding co-design across the full system stack. We address these challenges for MoE training through integrated optimizations spanning memory (fine-grained recomputation, offloading, etc.), communication (optimized dispatchers, overlapping, etc.), and computation (Grouped GEMM, fusions, CUDA Graphs, etc.). The framework also provides Parallel Folding for flexible multi-dimensional parallelism, low-precision training support for FP8 and NVFP4, and efficient long-context training. On NVIDIA GB300 and GB200, it achieves 1,233/1,048 TFLOPS/GPU for DeepSeek-V3-685B and 974/919 TFLOPS/GPU for Qwen3-235B. As a performant, scalable, and production-ready open-source solution, it has been used across academia and industry for training MoE models ranging from billions to trillions of parameters on clusters scaling up to thousands of GPUs. This report explains how these techniques work, their trade-offs, and their interactions at the systems level, providing practical guidance for scaling MoE models with Megatron Core.
ExpertFlow: Optimized Expert Activation and Token Allocation for Efficient Mixture-of-Experts Inference
Oct 23, 2024



Sparse Mixture of Experts (MoE) models, while outperforming dense Large Language Models (LLMs) in terms of performance, face significant deployment challenges during inference due to their high memory demands. Existing offloading techniques, which involve swapping activated and idle experts between the GPU and CPU, often suffer from rigid expert caching mechanisms. These mechanisms fail to adapt to dynamic routing, leading to inefficient cache utilization, or incur prohibitive costs for prediction training. To tackle these inference-specific challenges, we introduce ExpertFlow, a comprehensive system specifically designed to enhance inference efficiency by accommodating flexible routing and enabling efficient expert scheduling between CPU and GPU. This reduces overhead and boosts system performance. Central to our approach is a predictive routing path-based offloading mechanism that utilizes a lightweight predictor to accurately forecast routing paths before computation begins. This proactive strategy allows for real-time error correction in expert caching, significantly increasing cache hit ratios and reducing the frequency of expert transfers, thereby minimizing I/O overhead. Additionally, we implement a dynamic token scheduling strategy that optimizes MoE inference by rearranging input tokens across different batches. This method not only reduces the number of activated experts per batch but also improves computational efficiency. Our extensive experiments demonstrate that ExpertFlow achieves up to 93.72\% GPU memory savings and enhances inference speed by 2 to 10 times compared to baseline methods, highlighting its effectiveness and utility as a robust solution for resource-constrained inference scenarios.
Kimad: Adaptive Gradient Compression with Bandwidth Awareness
Dec 13, 2023



In distributed training, communication often emerges as a bottleneck. In response, we introduce Kimad, a solution that offers adaptive gradient compression. By consistently monitoring bandwidth, Kimad refines compression ratios to match specific neural network layer requirements. Our exhaustive tests and proofs confirm Kimad's outstanding performance, establishing it as a benchmark in adaptive compression for distributed deep learning.
Wasserstein-Wasserstein Auto-Encoders
Feb 25, 2019
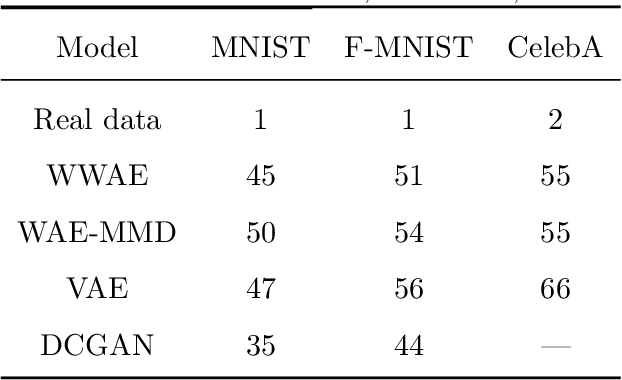
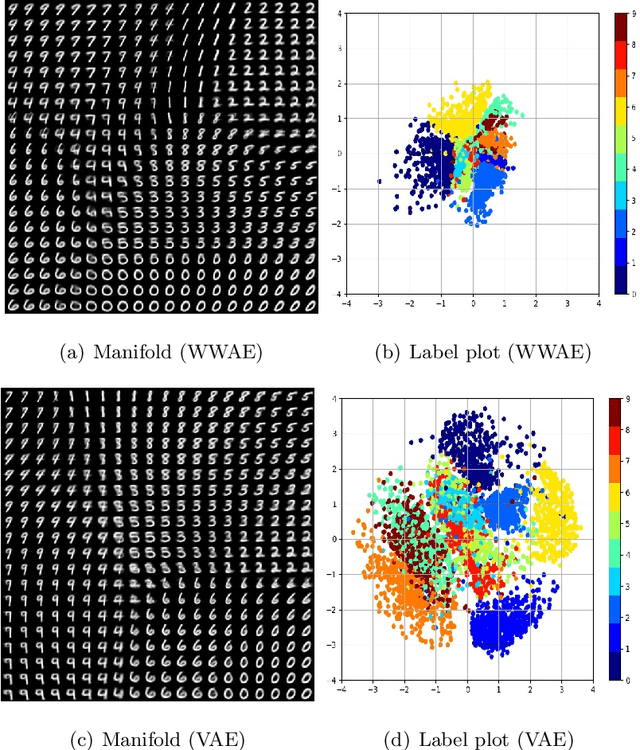

To address the challenges in learning deep generative models (e.g.,the blurriness of variational auto-encoder and the instability of training generative adversarial networks, we propose a novel deep generative model, named Wasserstein-Wasserstein auto-encoders (WWAE). We formulate WWAE as minimization of the penalized optimal transport between the target distribution and the generated distribution. By noticing that both the prior $P_Z$ and the aggregated posterior $Q_Z$ of the latent code Z can be well captured by Gaussians, the proposed WWAE utilizes the closed-form of the squared Wasserstein-2 distance for two Gaussians in the optimization process. As a result, WWAE does not suffer from the sampling burden and it is computationally efficient by leveraging the reparameterization trick. Numerical results evaluated on multiple benchmark datasets including MNIST, fashion- MNIST and CelebA show that WWAE learns better latent structures than VAEs and generates samples of better visual quality and higher FID scores than VAEs and GANs.
Deep Generative Learning via Variational Gradient Flow
Feb 07, 2019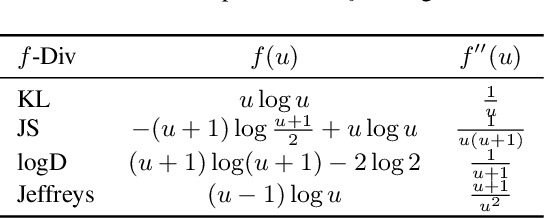
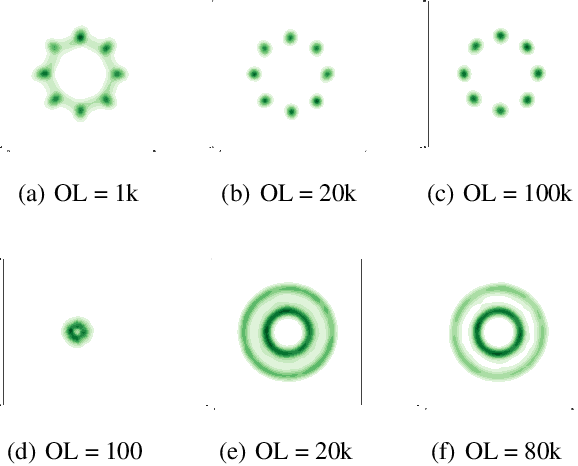
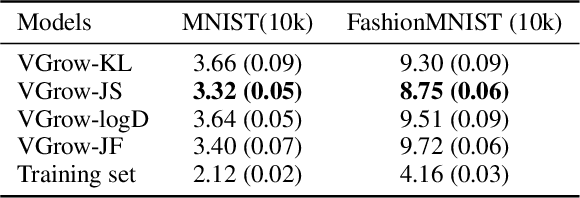
We propose a general framework to learn deep generative models via \textbf{V}ariational \textbf{Gr}adient Fl\textbf{ow} (VGrow) on probability spaces. The evolving distribution that asymptotically converges to the target distribution is governed by a vector field, which is the negative gradient of the first variation of the $f$-divergence between them. We prove that the evolving distribution coincides with the pushforward distribution through the infinitesimal time composition of residual maps that are perturbations of the identity map along the vector field. The vector field depends on the density ratio of the pushforward distribution and the target distribution, which can be consistently learned from a binary classification problem. Connections of our proposed VGrow method with other popular methods, such as VAE, GAN and flow-based methods, have been established in this framework, gaining new insights of deep generative learning. We also evaluated several commonly used divergences, including Kullback-Leibler, Jensen-Shannon, Jeffrey divergences as well as our newly discovered `logD' divergence which serves as the objective function of the logD-trick GAN. Experimental results on benchmark datasets demonstrate that VGrow can generate high-fidelity images in a stable and efficient manner, achieving competitive performance with state-of-the-art GANs.