 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Synthetic and Real Routing Problems via LLM-Guided Instance Generation and Progressive Adaptation
Nov 13, 2025Recent advances in Neural Combinatorial Optimization (NCO) methods have significantly improved the capability of neural solvers to handle synthetic routing instances. Nonetheless, existing neural solvers typically struggle to generalize effectively from synthetic, uniformly-distributed training data to real-world VRP scenarios, including widely recognized benchmark instances from TSPLib and CVRPLib. To bridge this generalization gap, we present Evolutionary Realistic Instance Synthesis (EvoReal), which leverages an evolutionary module guided by large language models (LLMs) to generate synthetic instances characterized by diverse and realistic structural patterns. Specifically, the evolutionary module produces synthetic instances whose structural attributes statistically mimics those observed in authentic real-world instances. Subsequently, pre-trained NCO models are progressively refined, firstly aligning them with these structurally enriched synthetic distributions and then further adapting them through direct fine-tuning on actual benchmark instances. Extensive experimental evaluations demonstrate that EvoReal markedly improves the generalization capabilities of state-of-the-art neural solvers, yielding a notable reduced performance gap compared to the optimal solutions on the TSPLib (1.05%) and CVRPLib (2.71%) benchmarks across a broad spectrum of problem scales.
Evaluating LLMs Without Oracle Feedback: Agentic Annotation Evaluation Through Unsupervised Consistency Signals
Sep 10, 2025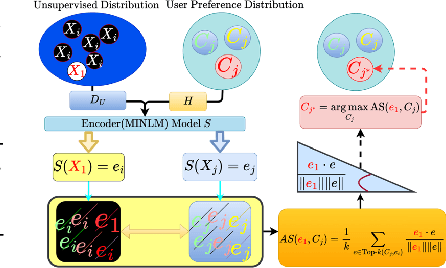
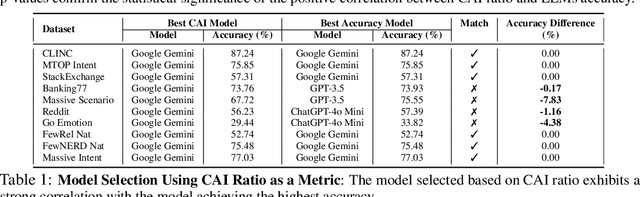
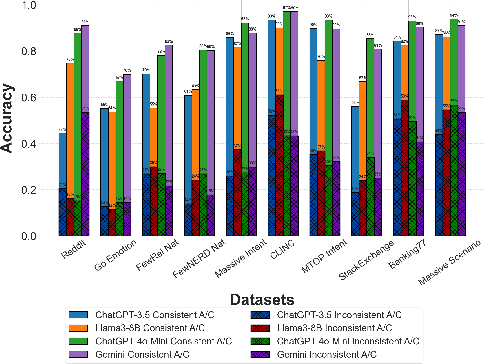

Large Language Models (LLMs), when paired with prompt-based tasks, have significantly reduced data annotation costs and reliance on human annotators. However, evaluating the quality of their annotations remains challenging in dynamic, unsupervised environments where oracle feedback is scarce and conventional methods fail. To address this challenge, we propose a novel agentic annotation paradigm, where a student model collaborates with a noisy teacher (the LLM) to assess and refine annotation quality without relying on oracle feedback. The student model, acting as an unsupervised feedback mechanism, employs a user preference-based majority voting strategy to evaluate the consistency of the LLM outputs. To systematically measure the reliability of LLM-generated annotations, we introduce the Consistent and Inconsistent (CAI) Ratio, a novel unsupervised evaluation metric. The CAI Ratio not only quantifies the annotation quality of the noisy teacher under limited user preferences but also plays a critical role in model selection, enabling the identification of robust LLMs in dynamic, unsupervised environments. Applied to ten open-domain NLP datasets across four LLMs, the CAI Ratio demonstrates a strong positive correlation with LLM accuracy, establishing it as an essential tool for unsupervised evaluation and model selection in real-world settings.
* 11 pages, 10 figures
MermaidFlow: Redefining Agentic Workflow Generation via Safety-Constrained Evolutionary Programming
May 29, 2025Despite the promise of autonomous agentic reasoning, existing workflow generation methods frequently produce fragile, unexecutable plans due to unconstrained LLM-driven construction. We introduce MermaidFlow, a framework that redefines the agentic search space through safety-constrained graph evolution. At its core, MermaidFlow represent workflows as a verifiable intermediate representation using Mermaid, a structured and human-interpretable graph language. We formulate domain-aware evolutionary operators, i.e., crossover, mutation, insertion, and deletion, to preserve semantic correctness while promoting structural diversity, enabling efficient exploration of a high-quality, statically verifiable workflow space. Without modifying task settings or evaluation protocols, MermaidFlow achieves consistent improvements in success rates and faster convergence to executable plans on the agent reasoning benchmark. The experimental results demonstrate that safety-constrained graph evolution offers a scalable, modular foundation for robust and interpretable agentic reasoning systems.
Mastering Continual Reinforcement Learning through Fine-Grained Sparse Network Allocation and Dormant Neuron Exploration
Mar 07, 2025



Continual Reinforcement Learning (CRL) is essential for developing agents that can learn, adapt, and accumulate knowledge over time. However, a fundamental challenge persists as agents must strike a delicate balance between plasticity, which enables rapid skill acquisition, and stability, which ensures long-term knowledge retention while preventing catastrophic forgetting. In this paper, we introduce SSDE, a novel structure-based approach that enhances plasticity through a fine-grained allocation strategy with Structured Sparsity and Dormant-guided Exploration. SSDE decomposes the parameter space into forward-transfer (frozen) parameters and task-specific (trainable) parameters. Crucially, these parameters are allocated by an efficient co-allocation scheme under sparse coding, ensuring sufficient trainable capacity for new tasks while promoting efficient forward transfer through frozen parameters. However, structure-based methods often suffer from rigidity due to the accumulation of non-trainable parameters, limiting exploration and adaptability. To address this, we further introduce a sensitivity-guided neuron reactivation mechanism that systematically identifies and resets dormant neurons, which exhibit minimal influence in the sparse policy network during inference. This approach effectively enhance exploration while preserving structural efficiency. Extensive experiments on the CW10-v1 Continual World benchmark demonstrate that SSDE achieves state-of-the-art performance, reaching a success rate of 95%, surpassing prior methods significantly in both plasticity and stability trade-offs (code is available at: https://github.com/chengqiArchy/SSDE).
ExpertFlow: Optimized Expert Activation and Token Allocation for Efficient Mixture-of-Experts Inference
Oct 23, 2024



Sparse Mixture of Experts (MoE) models, while outperforming dense Large Language Models (LLMs) in terms of performance, face significant deployment challenges during inference due to their high memory demands. Existing offloading techniques, which involve swapping activated and idle experts between the GPU and CPU, often suffer from rigid expert caching mechanisms. These mechanisms fail to adapt to dynamic routing, leading to inefficient cache utilization, or incur prohibitive costs for prediction training. To tackle these inference-specific challenges, we introduce ExpertFlow, a comprehensive system specifically designed to enhance inference efficiency by accommodating flexible routing and enabling efficient expert scheduling between CPU and GPU. This reduces overhead and boosts system performance. Central to our approach is a predictive routing path-based offloading mechanism that utilizes a lightweight predictor to accurately forecast routing paths before computation begins. This proactive strategy allows for real-time error correction in expert caching, significantly increasing cache hit ratios and reducing the frequency of expert transfers, thereby minimizing I/O overhead. Additionally, we implement a dynamic token scheduling strategy that optimizes MoE inference by rearranging input tokens across different batches. This method not only reduces the number of activated experts per batch but also improves computational efficiency. Our extensive experiments demonstrate that ExpertFlow achieves up to 93.72\% GPU memory savings and enhances inference speed by 2 to 10 times compared to baseline methods, highlighting its effectiveness and utility as a robust solution for resource-constrained inference scenarios.
Crowd-level Abnormal Behavior Detection via Multi-scale Motion Consistency Learning
Dec 01, 2022



Detecting abnormal crowd motion emerging from complex interactions of individuals is paramount to ensure the safety of crowds. Crowd-level abnormal behaviors (CABs), e.g., counter flow and crowd turbulence, are proven to be the crucial causes of many crowd disasters. In the recent decade, video anomaly detection (VAD) techniques have achieved remarkable success in detecting individual-level abnormal behaviors (e.g., sudden running, fighting and stealing), but research on VAD for CABs is rather limited. Unlike individual-level anomaly, CABs usually do not exhibit salient difference from the normal behaviors when observed locally, and the scale of CABs could vary from one scenario to another. In this paper, we present a systematic study to tackle the important problem of VAD for CABs with a novel crowd motion learning framework, multi-scale motion consistency network (MSMC-Net). MSMC-Net first captures the spatial and temporal crowd motion consistency information in a graph representation. Then, it simultaneously trains multiple feature graphs constructed at different scales to capture rich crowd patterns. An attention network is used to adaptively fuse the multi-scale features for better CAB detection. For the empirical study, we consider three large-scale crowd event datasets, UMN, Hajj and Love Parade. Experimental results show that MSMC-Net could substantially improve the state-of-the-art performance on all the datasets.
Reinforcement Learning with Efficient Active Feature Acquisition
Nov 02, 2020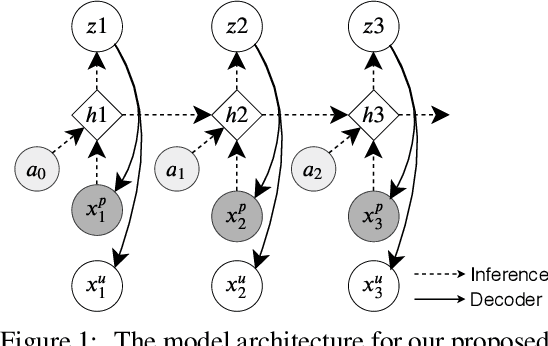
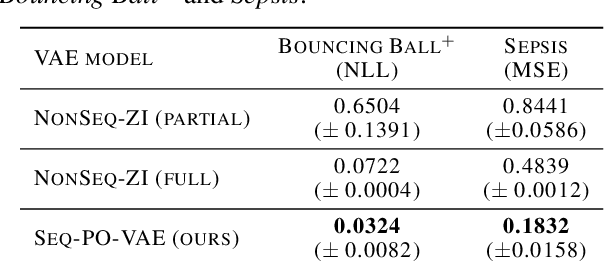
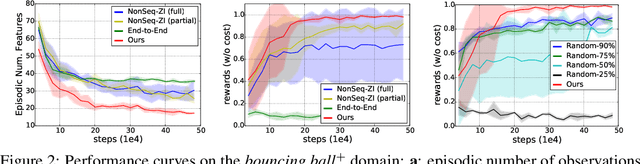

Solving real-life sequential decision making problems under partial observability involves an exploration-exploitation problem. To be successful, an agent needs to efficiently gather valuable information about the state of the world for making rewarding decisions. However, in real-life, acquiring valuable information is often highly costly, e.g., in the medical domain, information acquisition might correspond to performing a medical test on a patient. This poses a significant challenge for the agent to perform optimally for the task while reducing the cost for information acquisition. In this paper, we propose a model-based reinforcement learning framework that learns an active feature acquisition policy to solve the exploration-exploitation problem during its execution. Key to the success is a novel sequential variational auto-encoder that learns high-quality representations from partially observed states, which are then used by the policy to maximize the task reward in a cost efficient manner. We demonstrate the efficacy of our proposed framework in a control domain as well as using a medical simulator. In both tasks, our proposed method outperforms conventional baselines and results in policies with greater cost efficiency.
Meta-CoTGAN: A Meta Cooperative Training Paradigm for Improving Adversarial Text Generation
Mar 12, 2020
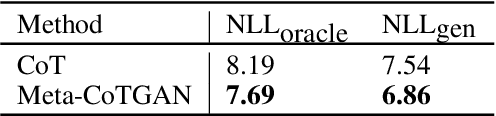
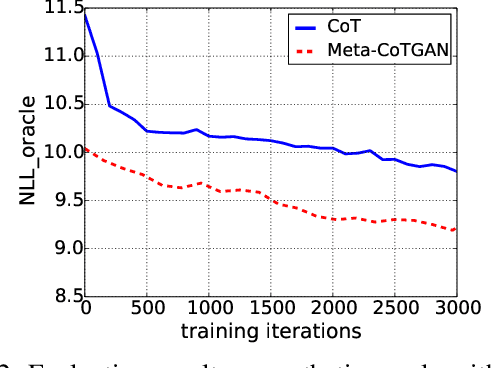
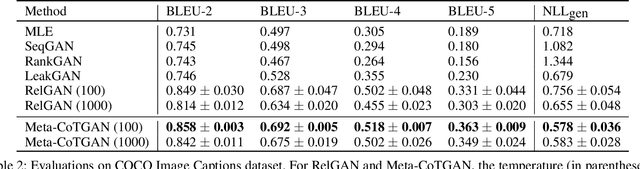
Training generative models that can generate high-quality text with sufficient diversity is an important open problem for Natural Language Generation (NLG) community. Recently, generative adversarial models have been applied extensively on text generation tasks, where the adversarially trained generators alleviate the exposure bias experienced by conventional maximum likelihood approaches and result in promising generation quality. However, due to the notorious defect of mode collapse for adversarial training, the adversarially trained generators face a quality-diversity trade-off, i.e., the generator models tend to sacrifice generation diversity severely for increasing generation quality. In this paper, we propose a novel approach which aims to improve the performance of adversarial text generation via efficiently decelerating mode collapse of the adversarial training. To this end, we introduce a cooperative training paradigm, where a language model is cooperatively trained with the generator and we utilize the language model to efficiently shape the data distribution of the generator against mode collapse. Moreover, instead of engaging the cooperative update for the generator in a principled way, we formulate a meta learning mechanism, where the cooperative update to the generator serves as a high level meta task, with an intuition of ensuring the parameters of the generator after the adversarial update would stay resistant against mode collapse. In the experiment, we demonstrate our proposed approach can efficiently slow down the pace of mode collapse for the adversarial text generators. Overall, our proposed method is able to outperform the baseline approaches with significant margins in terms of both generation quality and diversity in the testified domains.
Hashing over Predicted Future Frames for Informed Exploration of Deep Reinforcement Learning
Apr 27, 2018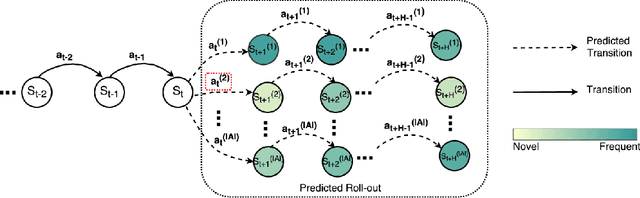

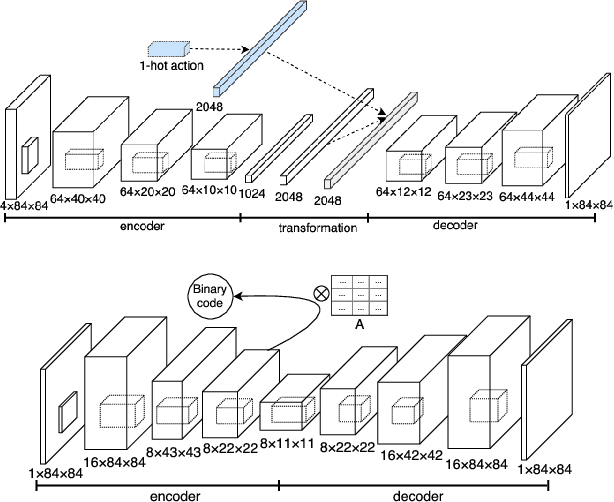
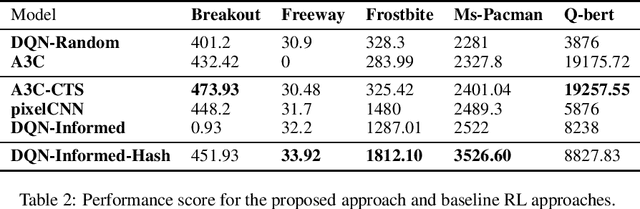
In deep reinforcement learning (RL) tasks, an efficient exploration mechanism should be able to encourage an agent to take actions that lead to less frequent states which may yield higher accumulative future return. However, both knowing about the future and evaluating the frequentness of states are non-trivial tasks, especially for deep RL domains, where a state is represented by high-dimensional image frames. In this paper, we propose a novel informed exploration framework for deep RL, where we build the capability for an RL agent to predict over the future transitions and evaluate the frequentness for the predicted future frames in a meaningful manner. To this end, we train a deep prediction model to predict future frames given a state-action pair, and a convolutional autoencoder model to hash over the seen frames. In addition, to utilize the counts derived from the seen frames to evaluate the frequentness for the predicted frames, we tackle the challenge of matching the predicted future frames and their corresponding seen frames at the latent feature level. In this way, we derive a reliable metric for evaluating the novelty of the future direction pointed by each action, and hence inform the agent to explore the least frequent one.