 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDone Is Better than Perfect: Unlocking Efficient Reasoning by Structured Multi-Turn Decomposition
May 26, 2025Large Reasoning Models (LRMs) are criticized for the excessively lengthy Chain-of-Thought (CoT) to derive the final answer, suffering from high first-token and overall latency. Typically, the CoT of LRMs mixes multiple thinking units; each unit attempts to produce a candidate answer to the original query. Hence, a natural idea to improve efficiency is to reduce the unit number. Yet, the fact that the thinking units in vanilla CoT cannot be explicitly managed renders doing so challenging. This paper introduces Multi-Turn Decomposition (MinD) to decode conventional CoT into a sequence of explicit, structured, and turn-wise interactions to bridge the gap. In MinD, the model provides a multi-turn response to the query, where each turn embraces a thinking unit and yields a corresponding answer. The subsequent turns can reflect, verify, revise, or explore alternative approaches to both the thinking and answer parts of earlier ones. This not only makes the answer delivered more swiftly, but also enables explicit controls over the iterative reasoning process (i.e., users may halt or continue at any turn). We follow a supervised fine-tuning (SFT) then reinforcement learning (RL) paradigm to realize MinD. We first rephrase the outputs of an LRM into multi-turn formats by prompting another LLM, and then tune the LRM with such data. Observing that the tuned model tends to consume even more tokens than the original one (probably due to that the multi-turn formats introduce additional answer tokens), we advocate leveraging RL algorithms like GRPO to prioritize correct outputs with fewer turns. Trained on the MATH dataset using R1-Distill models, MinD can achieve up to ~70% reduction in both output token usage and time to first token (TTFT), while maintaining competitive performance on reasoning benchmarks such as MATH-500, AIME24, AMC23, and GPQA-Diamond.
Which Data Attributes Stimulate Math and Code Reasoning? An Investigation via Influence Functions
May 26, 2025Large language models (LLMs) have demonstrated remarkable reasoning capabilities in math and coding, often bolstered by post-training on the chain-of-thoughts (CoTs) generated by stronger models. However, existing strategies for curating such training data predominantly rely on heuristics, limiting generalizability and failing to capture subtleties underlying in data. To address these limitations, we leverage influence functions to systematically attribute LLMs' reasoning ability on math and coding to individual training examples, sequences, and tokens, enabling deeper insights into effective data characteristics. Our Influence-based Reasoning Attribution (Infra) uncovers nontrivial cross-domain effects across math and coding tasks: high-difficulty math examples improve both math and code reasoning, while low-difficulty code tasks most effectively benefit code reasoning. Based on these findings, we introduce a simple yet effective dataset reweighting strategy by flipping task difficulty, which doubles AIME24 accuracy from 10\% to 20\% and boosts LiveCodeBench accuracy from 33.8\% to 35.3\% for Qwen2.5-7B-Instruct. Moreover, our fine-grained attribution reveals that the sequence-level exploratory behaviors enhance reasoning performance in both math and code, and the token-level influence patterns are distinct for math and code reasoning: the former prefers natural language logic connectors and the latter emphasizes structural syntax.
RealSafe-R1: Safety-Aligned DeepSeek-R1 without Compromising Reasoning Capability
Apr 14, 2025



Large Reasoning Models (LRMs), such as OpenAI o1 and DeepSeek-R1, have been rapidly progressing and achieving breakthrough performance on complex reasoning tasks such as mathematics and coding. However, the open-source R1 models have raised safety concerns in wide applications, such as the tendency to comply with malicious queries, which greatly impacts the utility of these powerful models in their applications. In this paper, we introduce RealSafe-R1 as safety-aligned versions of DeepSeek-R1 distilled models. To train these models, we construct a dataset of 15k safety-aware reasoning trajectories generated by DeepSeek-R1, under explicit instructions for expected refusal behavior. Both quantitative experiments and qualitative case studies demonstrate the models' improvements, which are shown in their safety guardrails against both harmful queries and jailbreak attacks. Importantly, unlike prior safety alignment efforts that often compromise reasoning performance, our method preserves the models' reasoning capabilities by maintaining the training data within the original distribution of generation. Model weights of RealSafe-R1 are open-source at https://huggingface.co/RealSafe.
SIFT: Grounding LLM Reasoning in Contexts via Stickers
Feb 19, 2025



This paper identifies the misinterpretation of the context can be a significant issue during the reasoning process of large language models, spanning from smaller models like Llama3.2-3B-Instruct to cutting-edge ones like DeepSeek-R1. For example, in the phrase "10 dollars per kilo," LLMs might not recognize that "per" means "for each," leading to calculation errors. We introduce a novel, post-training approach called **Stick to the Facts (SIFT)** to tackle this. SIFT leverages increasing inference-time compute to ground LLM reasoning in contexts. At the core of SIFT lies the *Sticker*, which is generated by the model itself to explicitly emphasize the key information within the context. Given the curated Sticker, SIFT generates two predictions -- one from the original query and one from the query augmented with the Sticker. If they differ, the Sticker is sequentially refined via *forward* optimization (to better align the extracted facts with the query) and *inverse* generation (to conform with the model's inherent tendencies) for more faithful reasoning outcomes. Studies across diverse models (from 3B to 100B+) and benchmarks (e.g., GSM8K, MATH-500) reveal consistent performance improvements. Notably, SIFT improves the pass@1 accuracy of DeepSeek-R1 on AIME2024 from 78.33% to **85.67**%, establishing a new state-of-the-art in the open-source community. The code is available at https://github.com/zhijie-group/SIFT.
ExpertFlow: Optimized Expert Activation and Token Allocation for Efficient Mixture-of-Experts Inference
Oct 23, 2024



Sparse Mixture of Experts (MoE) models, while outperforming dense Large Language Models (LLMs) in terms of performance, face significant deployment challenges during inference due to their high memory demands. Existing offloading techniques, which involve swapping activated and idle experts between the GPU and CPU, often suffer from rigid expert caching mechanisms. These mechanisms fail to adapt to dynamic routing, leading to inefficient cache utilization, or incur prohibitive costs for prediction training. To tackle these inference-specific challenges, we introduce ExpertFlow, a comprehensive system specifically designed to enhance inference efficiency by accommodating flexible routing and enabling efficient expert scheduling between CPU and GPU. This reduces overhead and boosts system performance. Central to our approach is a predictive routing path-based offloading mechanism that utilizes a lightweight predictor to accurately forecast routing paths before computation begins. This proactive strategy allows for real-time error correction in expert caching, significantly increasing cache hit ratios and reducing the frequency of expert transfers, thereby minimizing I/O overhead. Additionally, we implement a dynamic token scheduling strategy that optimizes MoE inference by rearranging input tokens across different batches. This method not only reduces the number of activated experts per batch but also improves computational efficiency. Our extensive experiments demonstrate that ExpertFlow achieves up to 93.72\% GPU memory savings and enhances inference speed by 2 to 10 times compared to baseline methods, highlighting its effectiveness and utility as a robust solution for resource-constrained inference scenarios.
MatryoshkaKV: Adaptive KV Compression via Trainable Orthogonal Projection
Oct 16, 2024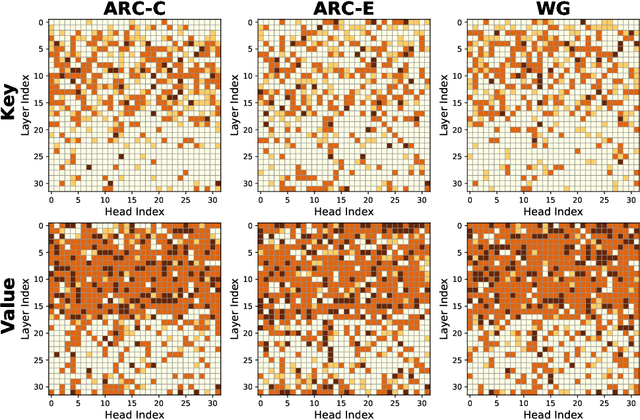



KV cache has become a de facto technique for the inference of large language models (LLMs), where tensors of shape (layer number, head number, sequence length, feature dimension) are introduced to cache historical information for self-attention. As the size of the model and data grows, the KV cache can quickly become a bottleneck within the system in both storage and memory transfer. To address this, prior studies usually focus on the first three axes of the cache tensors for compression. This paper supplements them, focusing on the feature dimension axis, by utilizing low-rank projection matrices to transform the cache features into spaces with reduced dimensions. We begin by investigating the canonical orthogonal projection method for data compression through principal component analysis (PCA). We observe the issue with PCA projection where significant performance degradation is observed at low compression rates. To bridge the gap, we propose to directly tune the orthogonal projection matrices with a distillation objective using an elaborate Matryoshka training strategy. After training, we adaptively search for the optimal compression rates for various layers and heads given varying compression budgets. Compared to previous works, our method can easily embrace pre-trained LLMs and hold a smooth tradeoff between performance and compression rate. We empirically witness the high data efficiency of our training procedure and find that our method can sustain over 90% performance with an average KV cache compression rate of 60% (and up to 75% in certain extreme scenarios) for popular LLMs like LLaMA2-7B-base and Mistral-7B-v0.3-base.
In-context KV-Cache Eviction for LLMs via Attention-Gate
Oct 15, 2024



The KV-Cache technique has become the standard for the inference of large language models (LLMs). It caches states of self-attention to avoid recomputation. Yet, it is widely criticized that KV-Cache can become a bottleneck of the LLM inference system, especially when confronted with ultra-large models and long-context queries. A natural remedy is to discard the KV-Cache for less important tokens, with StreamingLLM as an example, but the used static eviction strategies cannot flexibly adapt to varying contexts. Remedies like H2O leverage accumulative attention scores to perform dynamic eviction but suffer from the attention bias issue in capturing contextual information. This paper bridges this gap by devising a parameterized KV-Cache eviction mechanism, dubbed as Attention-Gate, which accepts the whole context as input and yields eviction flags for each token to realize in-context eviction. The subsequent self-attention module proceeds according to the flags and only the KV states for the remaining tokens need to be cached. The Attention-Gates can vary among different heads and layers and be trivially plugged into pre-trained LLMs, tuned by cost-effective continual pre-training or supervised fine-tuning objectives to acquire what to discard. The computational and memory overhead introduced by Attention-Gates is minimal. Our method is validated across multiple tasks, demonstrating both efficiency and adaptability. After a highly efficient continual pre-training, it achieves higher average accuracy and evicts more tokens compared to traditional training-free methods. In supervised fine-tuning, it not only evicts many tokens but also outperforms LoRA-finetuned LLMs on some datasets, such as RTE, where it improves accuracy by 13.9% while evicting 62.8% of tokens, showing that effective eviction of redundant tokens can even enhance performance.
AdaMoE: Token-Adaptive Routing with Null Experts for Mixture-of-Experts Language Models
Jun 19, 2024



Mixture of experts (MoE) has become the standard for constructing production-level large language models (LLMs) due to its promise to boost model capacity without causing significant overheads. Nevertheless, existing MoE methods usually enforce a constant top-k routing for all tokens, which is arguably restrictive because various tokens (e.g., "<EOS>" vs. "apple") may require various numbers of experts for feature abstraction. Lifting such a constraint can help make the most of limited resources and unleash the potential of the model for downstream tasks. In this sense, we introduce AdaMoE to realize token-adaptive routing for MoE, where different tokens are permitted to select a various number of experts. AdaMoE makes minimal modifications to the vanilla MoE with top-k routing -- it simply introduces a fixed number of null experts, which do not consume any FLOPs, to the expert set and increases the value of k. AdaMoE does not force each token to occupy a fixed number of null experts but ensures the average usage of the null experts with a load-balancing loss, leading to an adaptive number of null/true experts used by each token. AdaMoE exhibits a strong resemblance to MoEs with expert choice routing while allowing for trivial auto-regressive modeling. AdaMoE is easy to implement and can be effectively applied to pre-trained (MoE-)LLMs. Extensive studies show that AdaMoE can reduce average expert load (FLOPs) while achieving superior performance. For example, on the ARC-C dataset, applying our method to fine-tuning Mixtral-8x7B can reduce FLOPs by 14.5% while increasing accuracy by 1.69%.