 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA multi-agent system for spine MRI report generation from multi-sequence imaging
Jun 08, 2026Spinal pathology is a leading cause of pain and disability worldwide. Spine MRI is central to clinical evaluation, yet its interpretation remains complex and time-consuming, requiring integration of information across multiple imaging sequences and anatomical regions. Despite recent advances in automated MRI analysis, effectively combining multi-sequence data while preserving sequence-specific diagnostic information remains an open challenge. Here we present SpineAgent, a multi-agent framework for spine MRI report generation built upon a multi-sequence foundation model trained on routine clinical data from 32,047 patients and 453,683 MRI series, comprising a total of 13,441,191 MRI slices. To accommodate diverse modalities of sequences, we first pre-train two DINOv3-based encoders separately on T1- and T2-weighted sequences. We then introduce a continual training strategy that learns a synthesizer to embed images of other sequences using the T1 and T2 encoders, producing patient-level embedding that integrates various signals across MRI sequences. Using these embeddings, SpineAgent achieves state-of-the-art performance, and demonstrates strong generalizability under cross-manufacturer and cross-cohort evaluation. Beyond classification, SpineAgent enables pathology localization by identifying findings-relevant slices and segmenting pathological regions. It also supports multimodal image-report retrieval, providing a solid foundation for scalable and explainable MRI report generation. We further integrate these validated capabilities of SpineAgent into 37 specialized agents. Finally, we incorporate their outputs as structured tokens within a Medical Report Agent trained end-to-end for report generation. Through both automated metrics and expert evaluation by five radiologists, SpineAgent achieves leading performance in spine MRI report generation.
LLM Agents Enable User-Governed Personalization Beyond Platform Boundaries
May 10, 2026Personalization today is fundamentally platform-centric: services build user representations from the behavioral fragments they observe. Yet no platform can construct a complete picture of the user, as competitive incentives, legal constraints, user privacy concerns, and epistemic limits create persistent data barriers. This paper argues for a shift from platform-centric personalization to user-governed personalization, where only the user can integrate fragmented contexts across platforms and the offline world. The key asymmetry lies in data access: only users can aggregate their own cross-platform and offline information. Large language model (LLM) agents make such integration practically feasible for the first time by enabling reasoning over heterogeneous personal data and transforming users' cross-context information into actionable personalization capabilities. We provide proof-of-concept evidence that users equipped with cross-platform data exports and an off-the-shelf LLM agent can outperform single-platform personalization baselines. We conclude by outlining a research agenda for building scalable user-governed personalization systems.
Adaptation of Agentic AI
Dec 22, 2025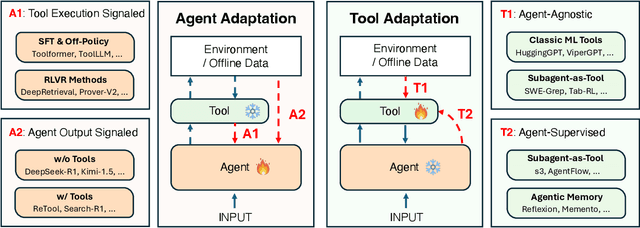
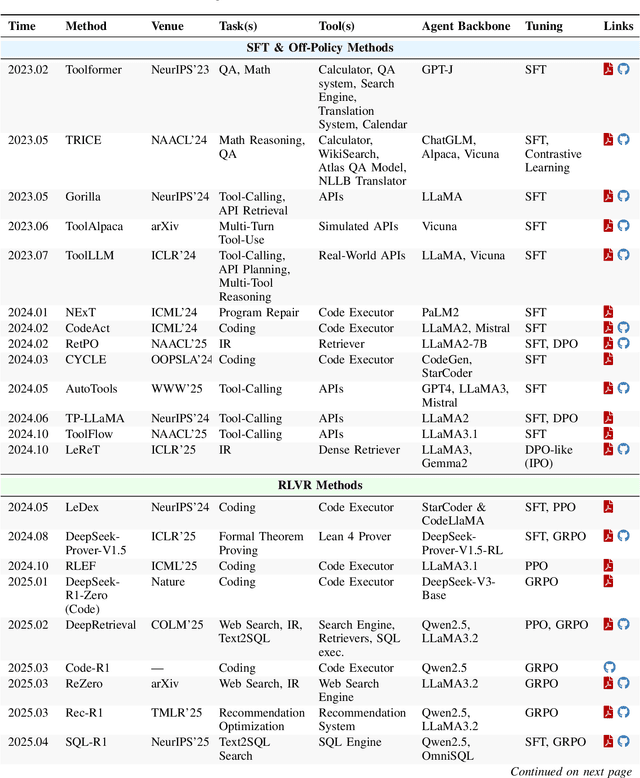
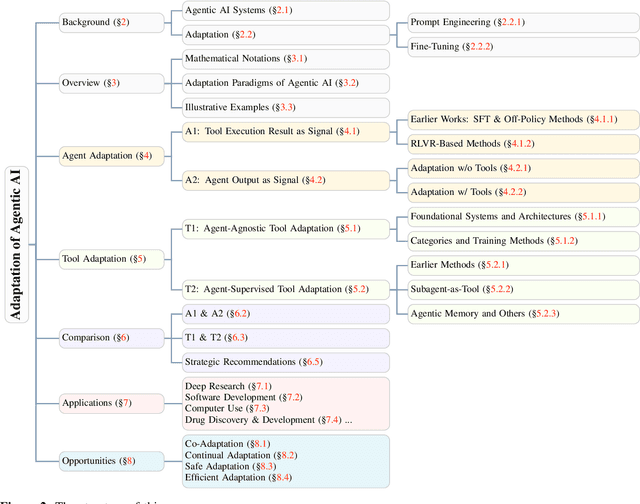
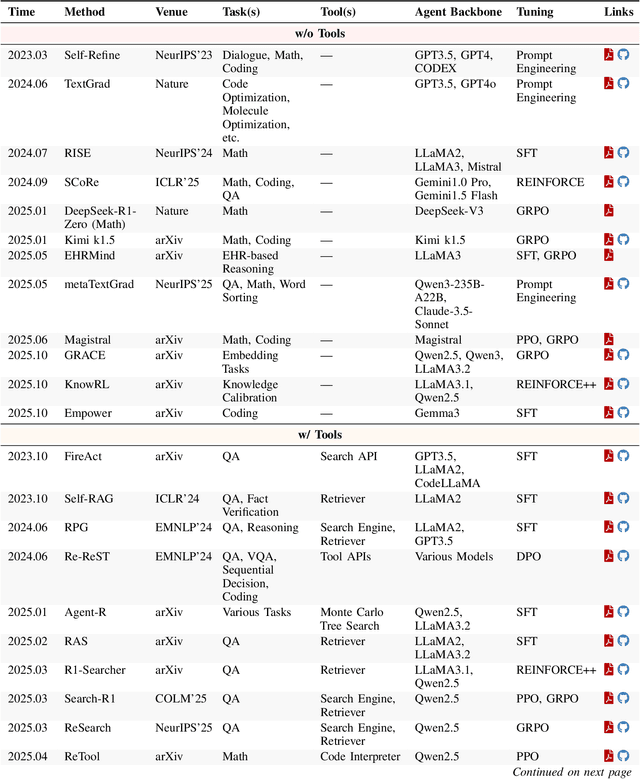
Cutting-edge agentic AI systems are built on foundation models that can be adapted to plan, reason, and interact with external tools to perform increasingly complex and specialized tasks. As these systems grow in capability and scope, adaptation becomes a central mechanism for improving performance, reliability, and generalization. In this paper, we unify the rapidly expanding research landscape into a systematic framework that spans both agent adaptations and tool adaptations. We further decompose these into tool-execution-signaled and agent-output-signaled forms of agent adaptation, as well as agent-agnostic and agent-supervised forms of tool adaptation. We demonstrate that this framework helps clarify the design space of adaptation strategies in agentic AI, makes their trade-offs explicit, and provides practical guidance for selecting or switching among strategies during system design. We then review the representative approaches in each category, analyze their strengths and limitations, and highlight key open challenges and future opportunities. Overall, this paper aims to offer a conceptual foundation and practical roadmap for researchers and practitioners seeking to build more capable, efficient, and reliable agentic AI systems.
Which Data Attributes Stimulate Math and Code Reasoning? An Investigation via Influence Functions
May 26, 2025Large language models (LLMs) have demonstrated remarkable reasoning capabilities in math and coding, often bolstered by post-training on the chain-of-thoughts (CoTs) generated by stronger models. However, existing strategies for curating such training data predominantly rely on heuristics, limiting generalizability and failing to capture subtleties underlying in data. To address these limitations, we leverage influence functions to systematically attribute LLMs' reasoning ability on math and coding to individual training examples, sequences, and tokens, enabling deeper insights into effective data characteristics. Our Influence-based Reasoning Attribution (Infra) uncovers nontrivial cross-domain effects across math and coding tasks: high-difficulty math examples improve both math and code reasoning, while low-difficulty code tasks most effectively benefit code reasoning. Based on these findings, we introduce a simple yet effective dataset reweighting strategy by flipping task difficulty, which doubles AIME24 accuracy from 10\% to 20\% and boosts LiveCodeBench accuracy from 33.8\% to 35.3\% for Qwen2.5-7B-Instruct. Moreover, our fine-grained attribution reveals that the sequence-level exploratory behaviors enhance reasoning performance in both math and code, and the token-level influence patterns are distinct for math and code reasoning: the former prefers natural language logic connectors and the latter emphasizes structural syntax.
OCTCube: A 3D foundation model for optical coherence tomography that improves cross-dataset, cross-disease, cross-device and cross-modality analysis
Aug 20, 2024Optical coherence tomography (OCT) has become critical for diagnosing retinal diseases as it enables 3D images of the retina and optic nerve. OCT acquisition is fast, non-invasive, affordable, and scalable. Due to its broad applicability, massive numbers of OCT images have been accumulated in routine exams, making it possible to train large-scale foundation models that can generalize to various diagnostic tasks using OCT images. Nevertheless, existing foundation models for OCT only consider 2D image slices, overlooking the rich 3D structure. Here, we present OCTCube, a 3D foundation model pre-trained on 26,605 3D OCT volumes encompassing 1.62 million 2D OCT images. OCTCube is developed based on 3D masked autoencoders and exploits FlashAttention to reduce the larger GPU memory usage caused by modeling 3D volumes. OCTCube outperforms 2D models when predicting 8 retinal diseases in both inductive and cross-dataset settings, indicating that utilizing the 3D structure in the model instead of 2D data results in significant improvement. OCTCube further shows superior performance on cross-device prediction and when predicting systemic diseases, such as diabetes and hypertension, further demonstrating its strong generalizability. Finally, we propose a contrastive-self-supervised-learning-based OCT-IR pre-training framework (COIP) for cross-modality analysis on OCT and infrared retinal (IR) images, where the OCT volumes are embedded using OCTCube. We demonstrate that COIP enables accurate alignment between OCT and IR en face images. Collectively, OCTCube, a 3D OCT foundation model, demonstrates significantly better performance against 2D models on 27 out of 29 tasks and comparable performance on the other two tasks, paving the way for AI-based retinal disease diagnosis.
Training Small Multimodal Models to Bridge Biomedical Competency Gap: A Case Study in Radiology Imaging
Mar 20, 2024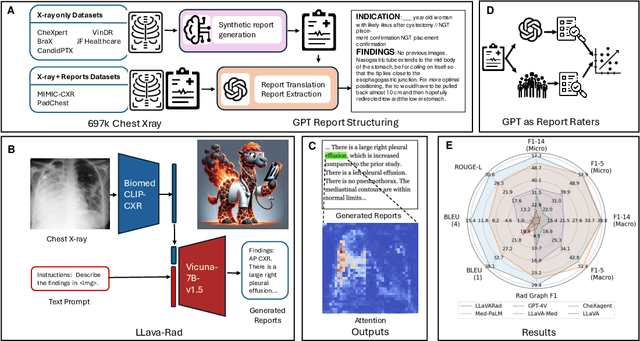
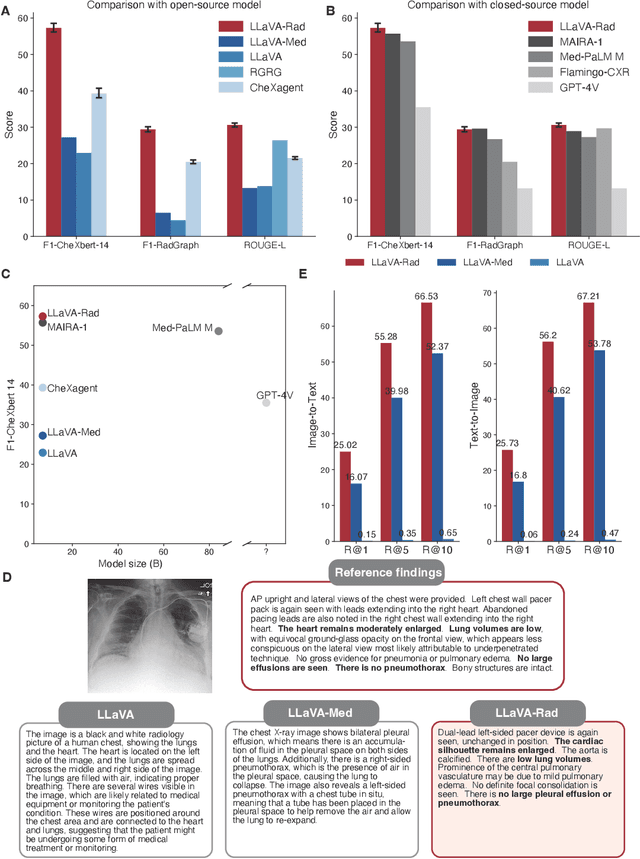
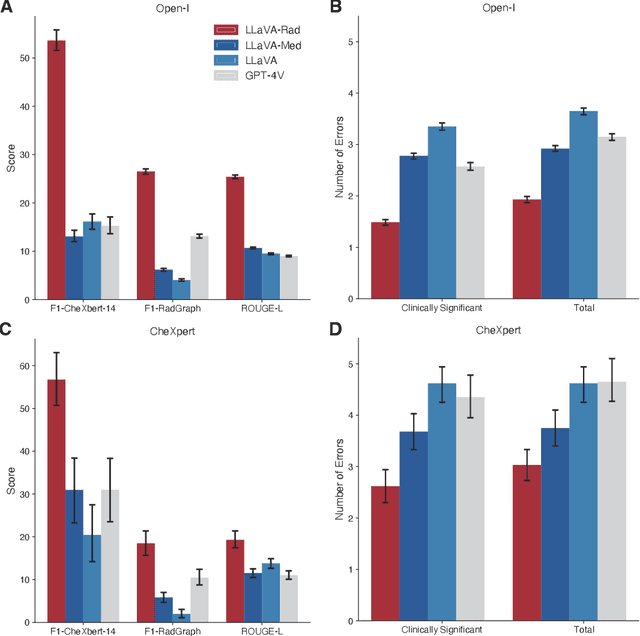
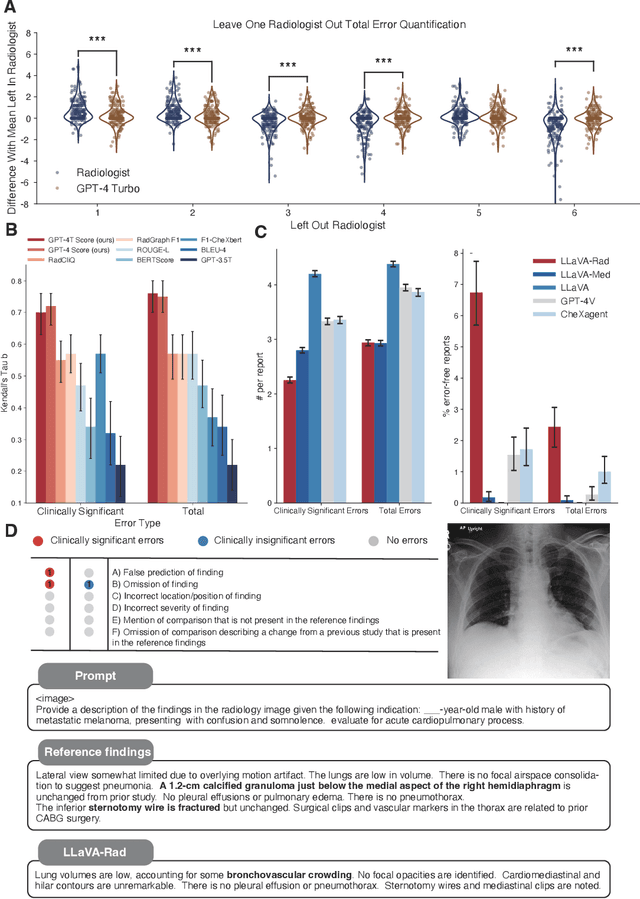
The scaling laws and extraordinary performance of large foundation models motivate the development and utilization of such large models in biomedicine. However, despite early promising results on some biomedical benchmarks, there are still major challenges that need to be addressed before these models can be used in real-world applications. Frontier models such as GPT-4V still have major competency gaps in multimodal capabilities for biomedical applications. Moreover, pragmatic issues such as access, cost, latency, and compliance make it hard for clinicians to use privately-hosted state-of-the-art large models directly on private patient data. In this paper, we explore training open-source small multimodal models (SMMs) to bridge biomedical competency gaps for unmet clinical needs. To maximize data efficiency, we adopt a modular approach by incorporating state-of-the-art pre-trained models for image and text modalities, and focusing on training a lightweight adapter to ground each modality to the text embedding space. We conduct a comprehensive study of this approach on radiology imaging. For training, we assemble a large dataset with over 1 million image-text pairs. For evaluation, we propose a clinically driven novel approach using GPT-4 and demonstrate its parity with expert evaluation. We also study grounding qualitatively using attention. For best practice, we conduct a systematic ablation study on various choices in data engineering and multimodal training. The resulting LLaVA-Rad (7B) model attains state-of-the-art results on radiology tasks such as report generation and cross-modal retrieval, even outperforming much larger models such as GPT-4V and Med-PaLM M (84B). LLaVA-Rad is fast and can be run on a single V100 GPU in private settings, offering a promising state-of-the-art tool for real-world clinical applications.
T-Rex: Text-assisted Retrosynthesis Prediction
Jan 26, 2024As a fundamental task in computational chemistry, retrosynthesis prediction aims to identify a set of reactants to synthesize a target molecule. Existing template-free approaches only consider the graph structures of the target molecule, which often cannot generalize well to rare reaction types and large molecules. Here, we propose T-Rex, a text-assisted retrosynthesis prediction approach that exploits pre-trained text language models, such as ChatGPT, to assist the generation of reactants. T-Rex first exploits ChatGPT to generate a description for the target molecule and rank candidate reaction centers based both the description and the molecular graph. It then re-ranks these candidates by querying the descriptions for each reactants and examines which group of reactants can best synthesize the target molecule. We observed that T-Rex substantially outperformed graph-based state-of-the-art approaches on two datasets, indicating the effectiveness of considering text information. We further found that T-Rex outperformed the variant that only use ChatGPT-based description without the re-ranking step, demonstrate how our framework outperformed a straightforward integration of ChatGPT and graph information. Collectively, we show that text generated by pre-trained language models can substantially improve retrosynthesis prediction, opening up new avenues for exploiting ChatGPT to advance computational chemistry. And the codes can be found at https://github.com/lauyikfung/T-Rex.
When an Image is Worth 1,024 x 1,024 Words: A Case Study in Computational Pathology
Dec 06, 2023This technical report presents LongViT, a vision Transformer that can process gigapixel images in an end-to-end manner. Specifically, we split the gigapixel image into a sequence of millions of patches and project them linearly into embeddings. LongNet is then employed to model the extremely long sequence, generating representations that capture both short-range and long-range dependencies. The linear computation complexity of LongNet, along with its distributed algorithm, enables us to overcome the constraints of both computation and memory. We apply LongViT in the field of computational pathology, aiming for cancer diagnosis and prognosis within gigapixel whole-slide images. Experimental results demonstrate that LongViT effectively encodes gigapixel images and outperforms previous state-of-the-art methods on cancer subtyping and survival prediction. Code and models will be available at https://aka.ms/LongViT.
Towards Large-scale Single-shot Millimeter-wave Imaging for Low-cost Security Inspection
May 25, 2023Millimeter-wave (MMW) imaging is emerging as a promising technique for safe security inspection. It achieves a delicate balance between imaging resolution, penetrability and human safety, resulting in higher resolution compared to low-frequency microwave, stronger penetrability compared to visible light, and stronger safety compared to X ray. Despite of recent advance in the last decades, the high cost of requisite large-scale antenna array hinders widespread adoption of MMW imaging in practice. To tackle this challenge, we report a large-scale single-shot MMW imaging framework using sparse antenna array, achieving low-cost but high-fidelity security inspection under an interpretable learning scheme. We first collected extensive full-sampled MMW echoes to study the statistical ranking of each element in the large-scale array. These elements are then sampled based on the ranking, building the experimentally optimal sparse sampling strategy that reduces the cost of antenna array by up to one order of magnitude. Additionally, we derived an untrained interpretable learning scheme, which realizes robust and accurate image reconstruction from sparsely sampled echoes. Last, we developed a neural network for automatic object detection, and experimentally demonstrated successful detection of concealed centimeter-sized targets using 10% sparse array, whereas all the other contemporary approaches failed at the same sample sampling ratio. The performance of the reported technique presents higher than 50% superiority over the existing MMW imaging schemes on various metrics including precision, recall, and mAP50. With such strong detection ability and order-of-magnitude cost reduction, we anticipate that this technique provides a practical way for large-scale single-shot MMW imaging, and could advocate its further practical applications.
Large-scale Global Low-rank Optimization for Computational Compressed Imaging
Jan 08, 2023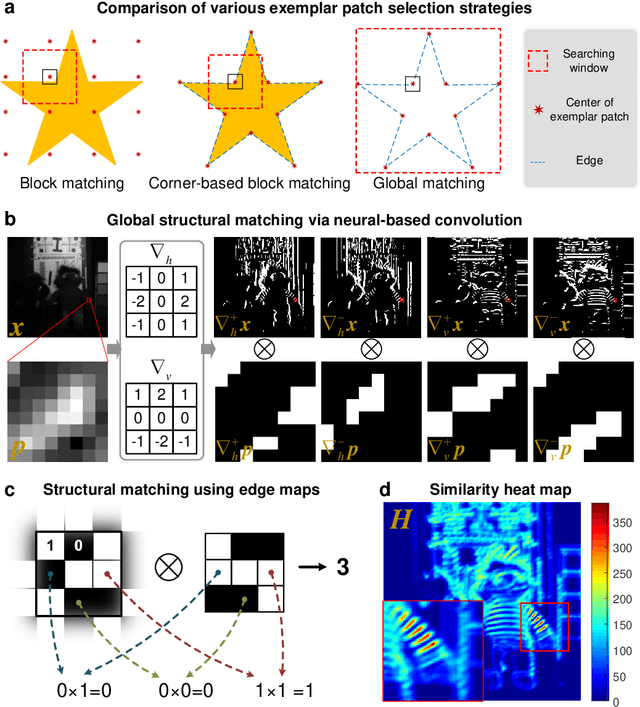
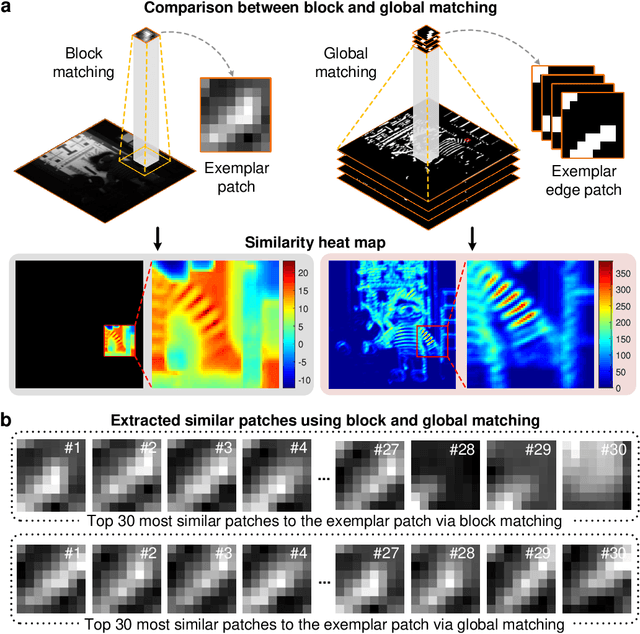
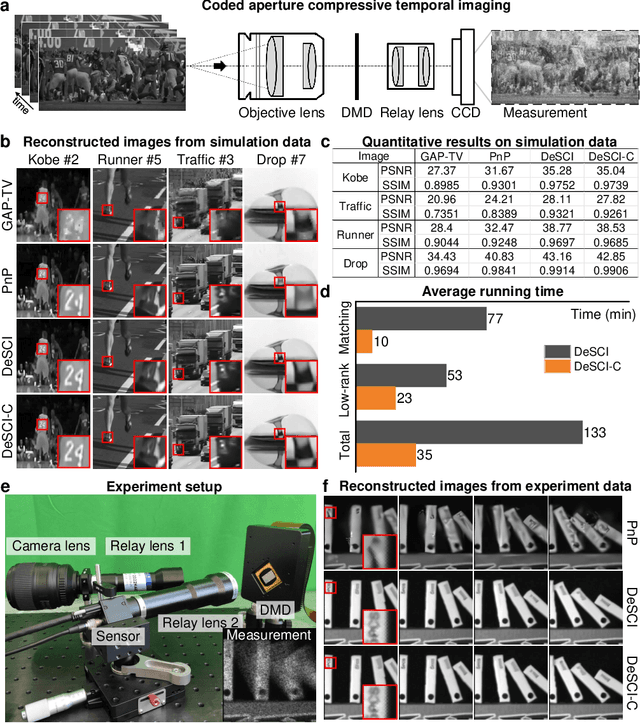
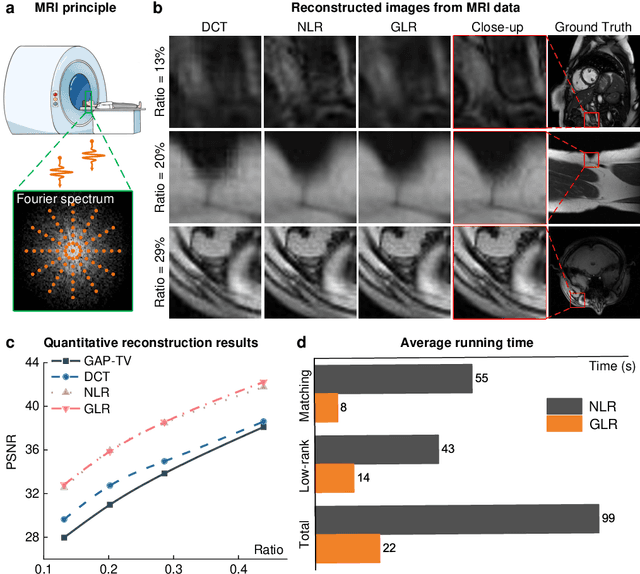
Computational reconstruction plays a vital role in computer vision and computational photography. Most of the conventional optimization and deep learning techniques explore local information for reconstruction. Recently, nonlocal low-rank (NLR) reconstruction has achieved remarkable success in improving accuracy and generalization. However, the computational cost has inhibited NLR from seeking global structural similarity, which consequentially keeps it trapped in the tradeoff between accuracy and efficiency and prevents it from high-dimensional large-scale tasks. To address this challenge, we report here the global low-rank (GLR) optimization technique, realizing highly-efficient large-scale reconstruction with global self-similarity. Inspired by the self-attention mechanism in deep learning, GLR extracts exemplar image patches by feature detection instead of conventional uniform selection. This directly produces key patches using structural features to avoid burdensome computational redundancy. Further, it performs patch matching across the entire image via neural-based convolution, which produces the global similarity heat map in parallel, rather than conventional sequential block-wise matching. As such, GLR improves patch grouping efficiency by more than one order of magnitude. We experimentally demonstrate GLR's effectiveness on temporal, frequency, and spectral dimensions, including different computational imaging modalities of compressive temporal imaging, magnetic resonance imaging, and multispectral filter array demosaicing. This work presents the superiority of inherent fusion of deep learning strategies and iterative optimization, and breaks the persistent dilemma of the tradeoff between accuracy and efficiency for various large-scale reconstruction tasks.