 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Dual-domain Learning for Underwater Image Enhancement
Apr 27, 2025Recently, learning-based Underwater Image Enhancement (UIE) methods have demonstrated promising performance. However, existing learning-based methods still face two challenges. 1) They rarely consider the inconsistent degradation levels in different spatial regions and spectral bands simultaneously. 2) They treat all regions equally, ignoring that the regions with high-frequency details are more difficult to reconstruct. To address these challenges, we propose a novel UIE method based on spatial-spectral dual-domain adaptive learning, termed SS-UIE. Specifically, we first introduce a spatial-wise Multi-scale Cycle Selective Scan (MCSS) module and a Spectral-Wise Self-Attention (SWSA) module, both with linear complexity, and combine them in parallel to form a basic Spatial-Spectral block (SS-block). Benefiting from the global receptive field of MCSS and SWSA, SS-block can effectively model the degradation levels of different spatial regions and spectral bands, thereby enabling degradation level-based dual-domain adaptive UIE. By stacking multiple SS-blocks, we build our SS-UIE network. Additionally, a Frequency-Wise Loss (FWL) is introduced to narrow the frequency-wise discrepancy and reinforce the model's attention on the regions with high-frequency details. Extensive experiments validate that the SS-UIE technique outperforms state-of-the-art UIE methods while requiring cheaper computational and memory costs.
Diffusion-based Blind Text Image Super-Resolution
Dec 13, 2023Recovering degraded low-resolution text images is challenging, especially for Chinese text images with complex strokes and severe degradation in real-world scenarios. Ensuring both text fidelity and style realness is crucial for high-quality text image super-resolution. Recently, diffusion models have achieved great success in natural image synthesis and restoration due to their powerful data distribution modeling abilities and data generation capabilities. In this work, we propose an Image Diffusion Model (IDM) to restore text images with realistic styles. For diffusion models, they are not only suitable for modeling realistic image distribution but also appropriate for learning text distribution. Since text prior is important to guarantee the correctness of the restored text structure according to existing arts, we also propose a Text Diffusion Model (TDM) for text recognition which can guide IDM to generate text images with correct structures. We further propose a Mixture of Multi-modality module (MoM) to make these two diffusion models cooperate with each other in all the diffusion steps. Extensive experiments on synthetic and real-world datasets demonstrate that our Diffusion-based Blind Text Image Super-Resolution (DiffTSR) can restore text images with more accurate text structures as well as more realistic appearances simultaneously.
Towards Large-scale Single-shot Millimeter-wave Imaging for Low-cost Security Inspection
May 25, 2023Millimeter-wave (MMW) imaging is emerging as a promising technique for safe security inspection. It achieves a delicate balance between imaging resolution, penetrability and human safety, resulting in higher resolution compared to low-frequency microwave, stronger penetrability compared to visible light, and stronger safety compared to X ray. Despite of recent advance in the last decades, the high cost of requisite large-scale antenna array hinders widespread adoption of MMW imaging in practice. To tackle this challenge, we report a large-scale single-shot MMW imaging framework using sparse antenna array, achieving low-cost but high-fidelity security inspection under an interpretable learning scheme. We first collected extensive full-sampled MMW echoes to study the statistical ranking of each element in the large-scale array. These elements are then sampled based on the ranking, building the experimentally optimal sparse sampling strategy that reduces the cost of antenna array by up to one order of magnitude. Additionally, we derived an untrained interpretable learning scheme, which realizes robust and accurate image reconstruction from sparsely sampled echoes. Last, we developed a neural network for automatic object detection, and experimentally demonstrated successful detection of concealed centimeter-sized targets using 10% sparse array, whereas all the other contemporary approaches failed at the same sample sampling ratio. The performance of the reported technique presents higher than 50% superiority over the existing MMW imaging schemes on various metrics including precision, recall, and mAP50. With such strong detection ability and order-of-magnitude cost reduction, we anticipate that this technique provides a practical way for large-scale single-shot MMW imaging, and could advocate its further practical applications.
Large-scale Global Low-rank Optimization for Computational Compressed Imaging
Jan 08, 2023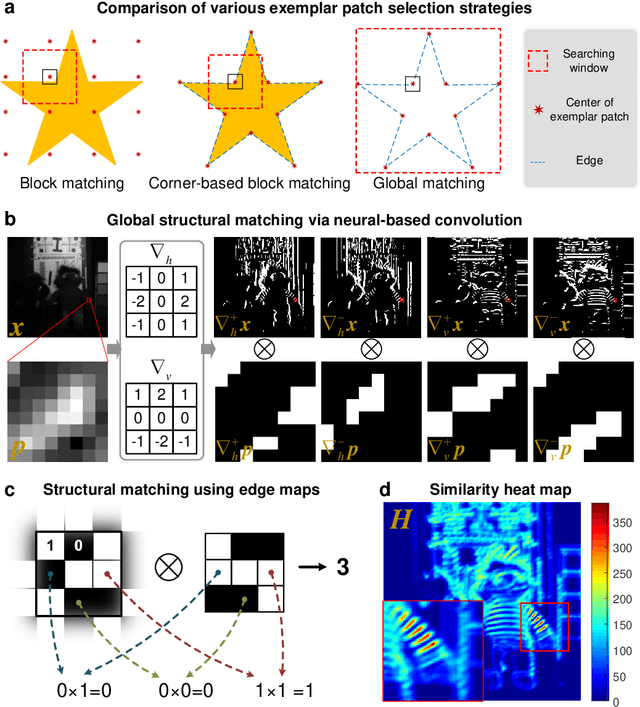
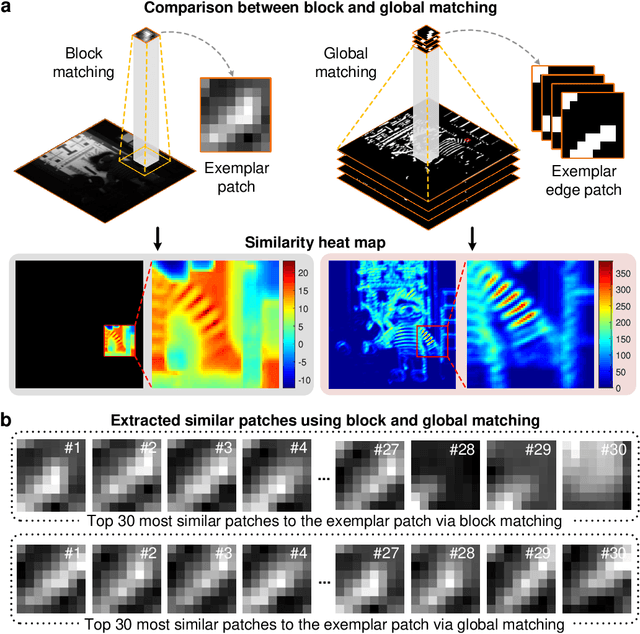
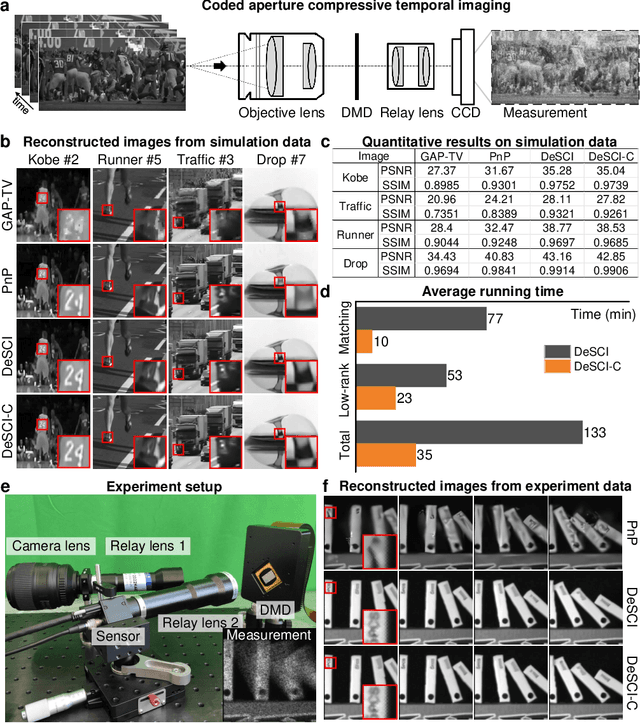
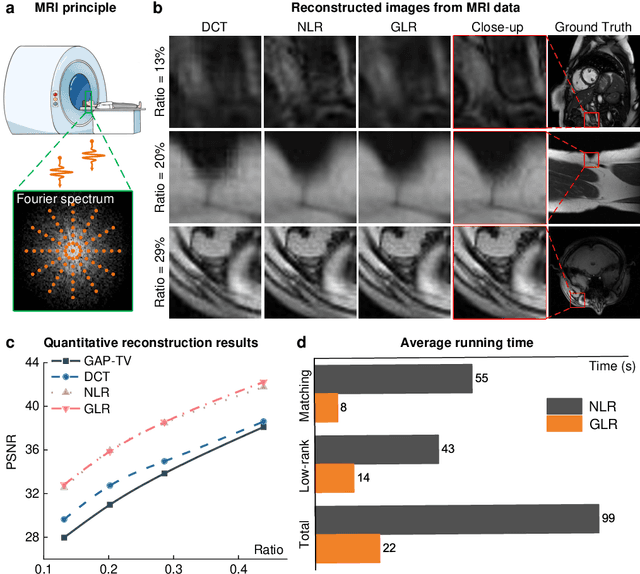
Computational reconstruction plays a vital role in computer vision and computational photography. Most of the conventional optimization and deep learning techniques explore local information for reconstruction. Recently, nonlocal low-rank (NLR) reconstruction has achieved remarkable success in improving accuracy and generalization. However, the computational cost has inhibited NLR from seeking global structural similarity, which consequentially keeps it trapped in the tradeoff between accuracy and efficiency and prevents it from high-dimensional large-scale tasks. To address this challenge, we report here the global low-rank (GLR) optimization technique, realizing highly-efficient large-scale reconstruction with global self-similarity. Inspired by the self-attention mechanism in deep learning, GLR extracts exemplar image patches by feature detection instead of conventional uniform selection. This directly produces key patches using structural features to avoid burdensome computational redundancy. Further, it performs patch matching across the entire image via neural-based convolution, which produces the global similarity heat map in parallel, rather than conventional sequential block-wise matching. As such, GLR improves patch grouping efficiency by more than one order of magnitude. We experimentally demonstrate GLR's effectiveness on temporal, frequency, and spectral dimensions, including different computational imaging modalities of compressive temporal imaging, magnetic resonance imaging, and multispectral filter array demosaicing. This work presents the superiority of inherent fusion of deep learning strategies and iterative optimization, and breaks the persistent dilemma of the tradeoff between accuracy and efficiency for various large-scale reconstruction tasks.
Large-scale single-photon imaging
Dec 28, 2022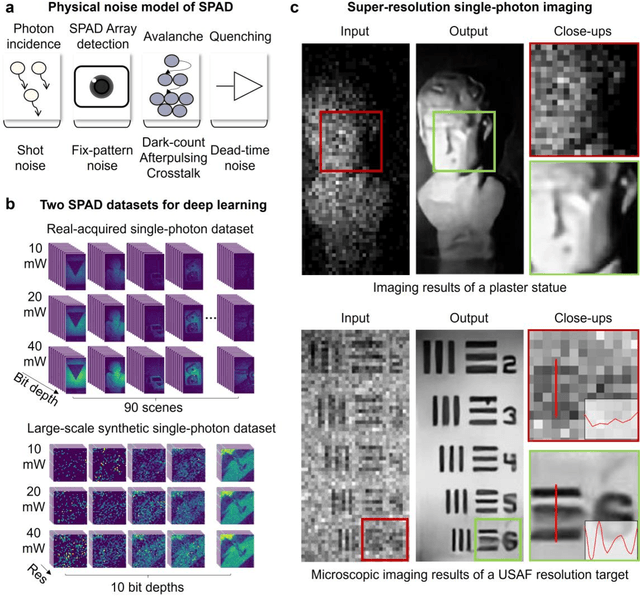
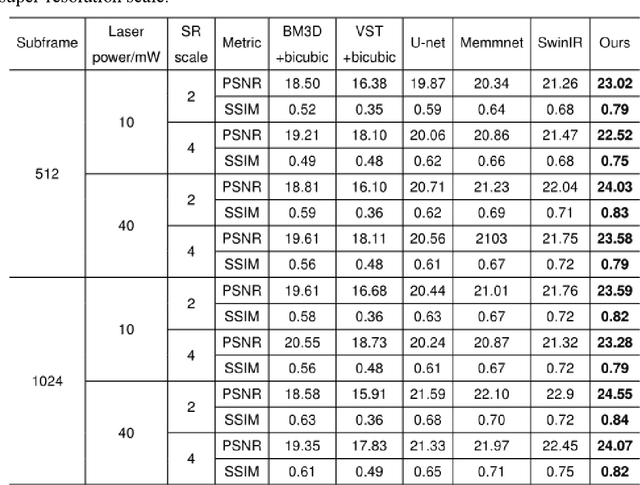

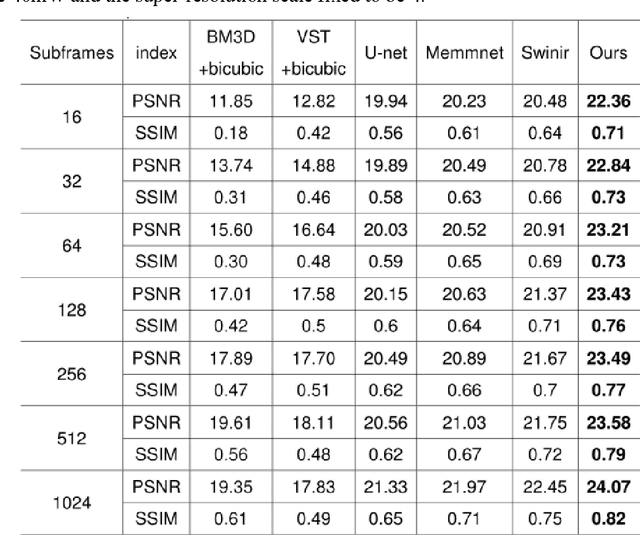
Benefiting from its single-photon sensitivity, single-photon avalanche diode (SPAD) array has been widely applied in various fields such as fluorescence lifetime imaging and quantum computing. However, large-scale high-fidelity single-photon imaging remains a big challenge, due to the complex hardware manufacture craft and heavy noise disturbance of SPAD arrays. In this work, we introduce deep learning into SPAD, enabling super-resolution single-photon imaging over an order of magnitude, with significant enhancement of bit depth and imaging quality. We first studied the complex photon flow model of SPAD electronics to accurately characterize multiple physical noise sources, and collected a real SPAD image dataset (64 $\times$ 32 pixels, 90 scenes, 10 different bit depth, 3 different illumination flux, 2790 images in total) to calibrate noise model parameters. With this real-world physical noise model, we for the first time synthesized a large-scale realistic single-photon image dataset (image pairs of 5 different resolutions with maximum megapixels, 17250 scenes, 10 different bit depth, 3 different illumination flux, 2.6 million images in total) for subsequent network training. To tackle the severe super-resolution challenge of SPAD inputs with low bit depth, low resolution, and heavy noise, we further built a deep transformer network with a content-adaptive self-attention mechanism and gated fusion modules, which can dig global contextual features to remove multi-source noise and extract full-frequency details. We applied the technique on a series of experiments including macroscopic and microscopic imaging, microfluidic inspection, and Fourier ptychography. The experiments validate the technique's state-of-the-art super-resolution SPAD imaging performance, with more than 5 dB superiority on PSNR compared to the existing methods.
INFWIDE: Image and Feature Space Wiener Deconvolution Network for Non-blind Image Deblurring in Low-Light Conditions
Jul 17, 2022
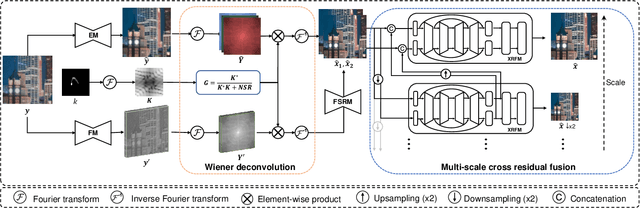

Under low-light environment, handheld photography suffers from severe camera shake under long exposure settings. Although existing deblurring algorithms have shown promising performance on well-exposed blurry images, they still cannot cope with low-light snapshots. Sophisticated noise and saturation regions are two dominating challenges in practical low-light deblurring. In this work, we propose a novel non-blind deblurring method dubbed image and feature space Wiener deconvolution network (INFWIDE) to tackle these problems systematically. In terms of algorithm design, INFWIDE proposes a two-branch architecture, which explicitly removes noise and hallucinates saturated regions in the image space and suppresses ringing artifacts in the feature space, and integrates the two complementary outputs with a subtle multi-scale fusion network for high quality night photograph deblurring. For effective network training, we design a set of loss functions integrating a forward imaging model and backward reconstruction to form a close-loop regularization to secure good convergence of the deep neural network. Further, to optimize INFWIDE's applicability in real low-light conditions, a physical-process-based low-light noise model is employed to synthesize realistic noisy night photographs for model training. Taking advantage of the traditional Wiener deconvolution algorithm's physically driven characteristics and arisen deep neural network's representation ability, INFWIDE can recover fine details while suppressing the unpleasant artifacts during deblurring. Extensive experiments on synthetic data and real data demonstrate the superior performance of the proposed approach.
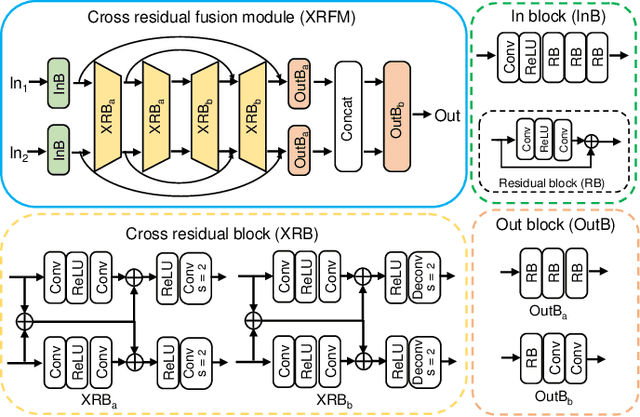
Weighted Encoding Optimization for Dynamic Single-pixel Imaging and Sensing
Jan 08, 2022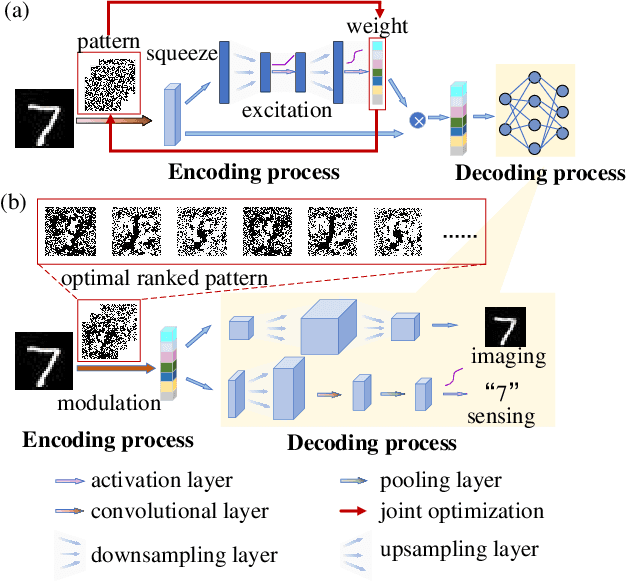
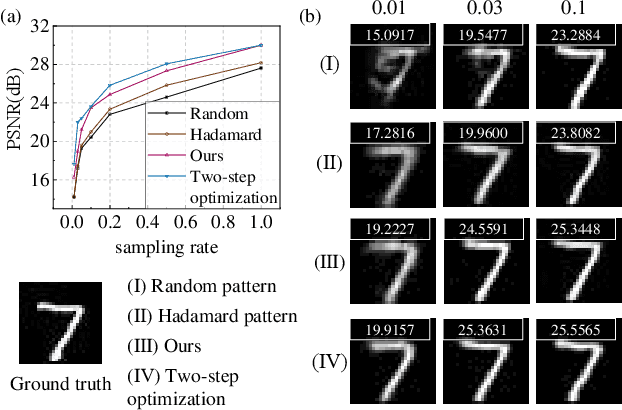
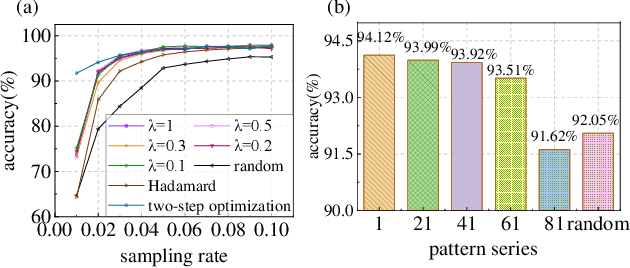

Using single-pixel detection, the end-to-end neural network that jointly optimizes both encoding and decoding enables high-precision imaging and high-level semantic sensing. However, for varied sampling rates, the large-scale network requires retraining that is laboursome and computation-consuming. In this letter, we report a weighted optimization technique for dynamic rate-adaptive single-pixel imaging and sensing, which only needs to train the network for one time that is available for any sampling rates. Specifically, we introduce a novel weighting scheme in the encoding process to characterize different patterns' modulation efficiency. While the network is training at a high sampling rate, the modulation patterns and corresponding weights are updated iteratively, which produces optimal ranked encoding series when converged. In the experimental implementation, the optimal pattern series with the highest weights are employed for light modulation, thus achieving highly-efficient imaging and sensing. The reported strategy saves the additional training of another low-rate network required by the existing dynamic single-pixel networks, which further doubles training efficiency. Experiments on the MNIST dataset validated that once the network is trained with a sampling rate of 1, the average imaging PSNR reaches 23.50 dB at 0.1 sampling rate, and the image-free classification accuracy reaches up to 95.00\% at a sampling rate of 0.03 and 97.91\% at a sampling rate of 0.1.
Image-free multi-character recognition
Dec 20, 2021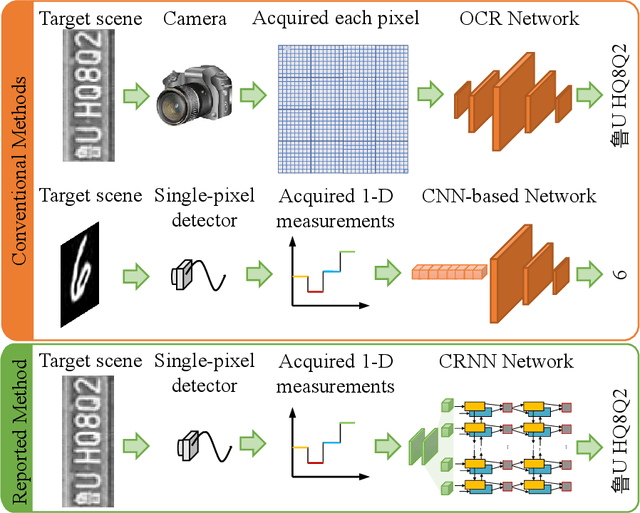
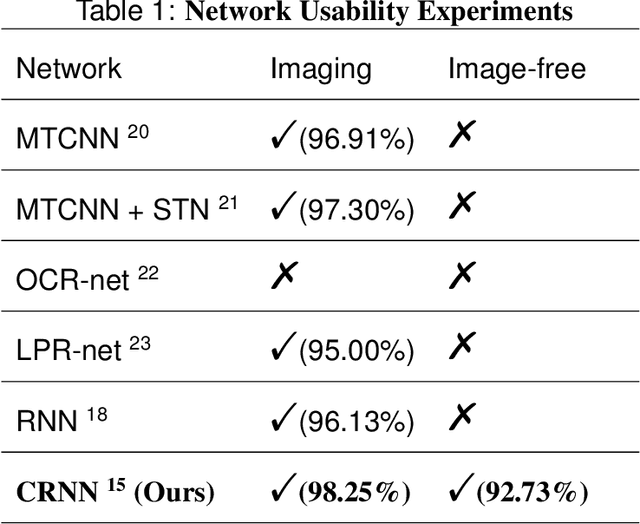
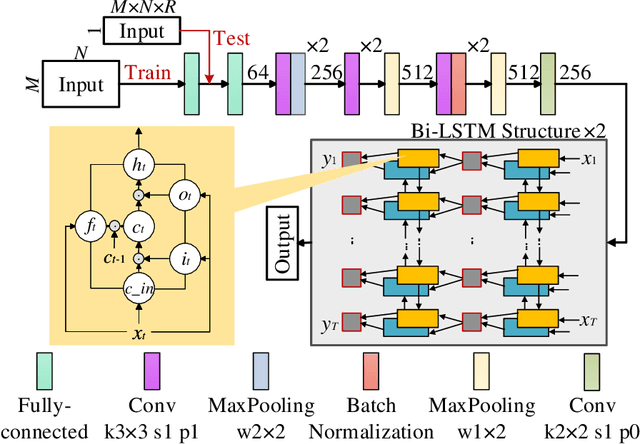
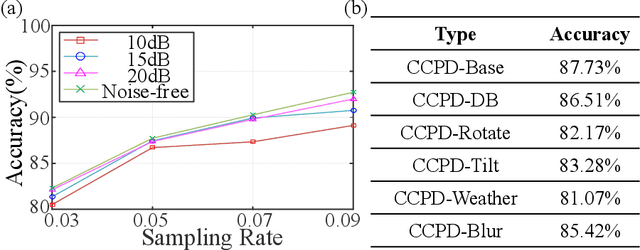
The recently developed image-free sensing technique maintains the advantages of both the light hardware and software, which has been applied in simple target classification and motion tracking. In practical applications, however, there usually exist multiple targets in the field of view, where existing trials fail to produce multi-semantic information. In this letter, we report a novel image-free sensing technique to tackle the multi-target recognition challenge for the first time. Different from the convolutional layer stack of image-free single-pixel networks, the reported CRNN network utilities the bidirectional LSTM architecture to predict the distribution of multiple characters simultaneously. The framework enables to capture the long-range dependencies, providing a high recognition accuracy of multiple characters. We demonstrated the technique's effectiveness in license plate detection, which achieved 87.60% recognition accuracy at a 5% sampling rate with a higher than 100 FPS refresh rate.
U-shape Transformer for Underwater Image Enhancement
Dec 03, 2021
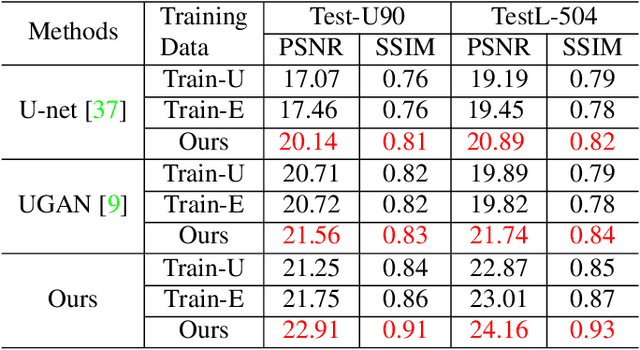
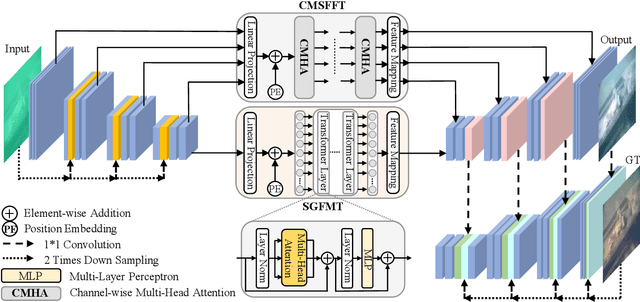
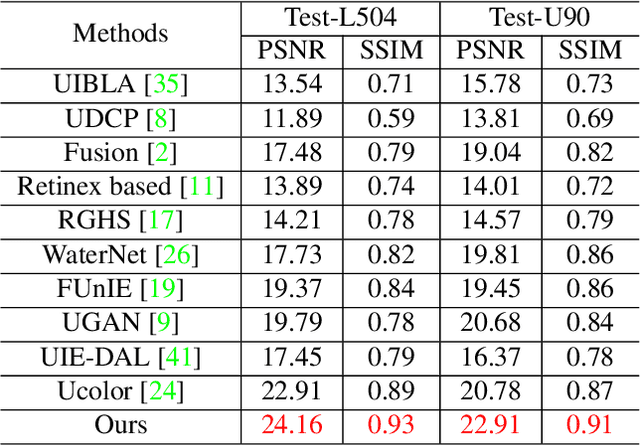
The light absorption and scattering of underwater impurities lead to poor underwater imaging quality. The existing data-driven based underwater image enhancement (UIE) techniques suffer from the lack of a large-scale dataset containing various underwater scenes and high-fidelity reference images. Besides, the inconsistent attenuation in different color channels and space areas is not fully considered for boosted enhancement. In this work, we constructed a large-scale underwater image (LSUI) dataset including 5004 image pairs, and reported an U-shape Transformer network where the transformer model is for the first time introduced to the UIE task. The U-shape Transformer is integrated with a channel-wise multi-scale feature fusion transformer (CMSFFT) module and a spatial-wise global feature modeling transformer (SGFMT) module, which reinforce the network's attention to the color channels and space areas with more serious attenuation. Meanwhile, in order to further improve the contrast and saturation, a novel loss function combining RGB, LAB and LCH color spaces is designed following the human vision principle. The extensive experiments on available datasets validate the state-of-the-art performance of the reported technique with more than 2dB superiority.
Image-free single-pixel segmentation
Aug 24, 2021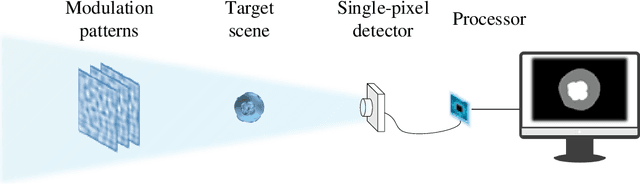
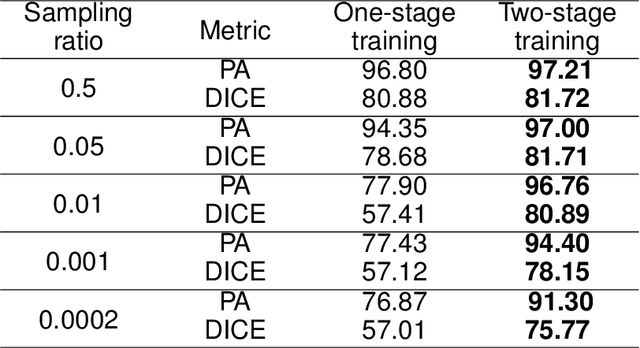
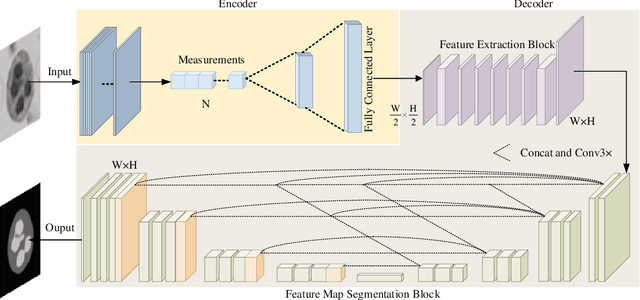

The existing segmentation techniques require high-fidelity images as input to perform semantic segmentation. Since the segmentation results contain most of edge information that is much less than the acquired images, the throughput gap leads to both hardware and software waste. In this letter, we report an image-free single-pixel segmentation technique. The technique combines structured illumination and single-pixel detection together, to efficiently samples and multiplexes scene's segmentation information into compressed one-dimensional measurements. The illumination patterns are optimized together with the subsequent reconstruction neural network, which directly infers segmentation maps from the single-pixel measurements. The end-to-end encoding-and-decoding learning framework enables optimized illumination with corresponding network, which provides both high acquisition and segmentation efficiency. Both simulation and experimental results validate that accurate segmentation can be achieved using two-order-of-magnitude less input data. When the sampling ratio is 1%, the Dice coefficient reaches above 80% and the pixel accuracy reaches above 96%. We envision that this image-free segmentation technique can be widely applied in various resource-limited platforms such as UAV and unmanned vehicle that require real-time sensing.