 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Long-distance Latent Relation-aware Graph Neural Network for Multi-modal Emotion Recognition in Conversations
Jun 27, 2024



The task of multi-modal emotion recognition in conversation (MERC) aims to analyze the genuine emotional state of each utterance based on the multi-modal information in the conversation, which is crucial for conversation understanding. Existing methods focus on using graph neural networks (GNN) to model conversational relationships and capture contextual latent semantic relationships. However, due to the complexity of GNN, existing methods cannot efficiently capture the potential dependencies between long-distance utterances, which limits the performance of MERC. In this paper, we propose an Efficient Long-distance Latent Relation-aware Graph Neural Network (ELR-GNN) for multi-modal emotion recognition in conversations. Specifically, we first use pre-extracted text, video and audio features as input to Bi-LSTM to capture contextual semantic information and obtain low-level utterance features. Then, we use low-level utterance features to construct a conversational emotion interaction graph. To efficiently capture the potential dependencies between long-distance utterances, we use the dilated generalized forward push algorithm to precompute the emotional propagation between global utterances and design an emotional relation-aware operator to capture the potential semantic associations between different utterances. Furthermore, we combine early fusion and adaptive late fusion mechanisms to fuse latent dependency information between speaker relationship information and context. Finally, we obtain high-level discourse features and feed them into MLP for emotion prediction. Extensive experimental results show that ELR-GNN achieves state-of-the-art performance on the benchmark datasets IEMOCAP and MELD, with running times reduced by 52\% and 35\%, respectively.
Image-free single-pixel segmentation
Aug 24, 2021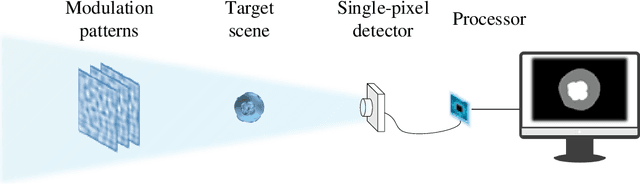
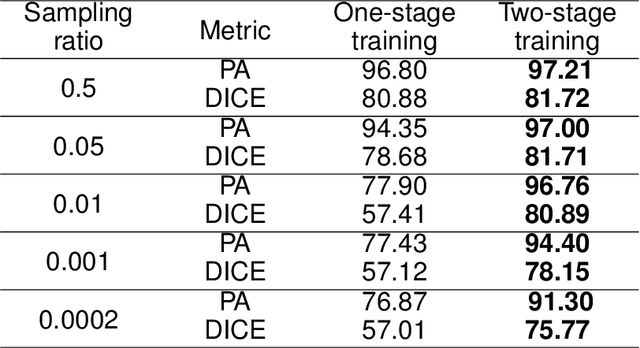
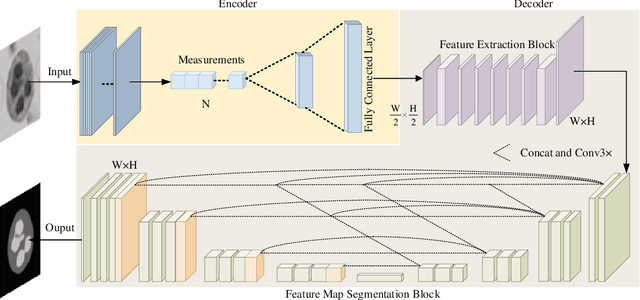

The existing segmentation techniques require high-fidelity images as input to perform semantic segmentation. Since the segmentation results contain most of edge information that is much less than the acquired images, the throughput gap leads to both hardware and software waste. In this letter, we report an image-free single-pixel segmentation technique. The technique combines structured illumination and single-pixel detection together, to efficiently samples and multiplexes scene's segmentation information into compressed one-dimensional measurements. The illumination patterns are optimized together with the subsequent reconstruction neural network, which directly infers segmentation maps from the single-pixel measurements. The end-to-end encoding-and-decoding learning framework enables optimized illumination with corresponding network, which provides both high acquisition and segmentation efficiency. Both simulation and experimental results validate that accurate segmentation can be achieved using two-order-of-magnitude less input data. When the sampling ratio is 1%, the Dice coefficient reaches above 80% and the pixel accuracy reaches above 96%. We envision that this image-free segmentation technique can be widely applied in various resource-limited platforms such as UAV and unmanned vehicle that require real-time sensing.
AMA-GCN: Adaptive Multi-layer Aggregation Graph Convolutional Network for Disease Prediction
Jun 16, 2021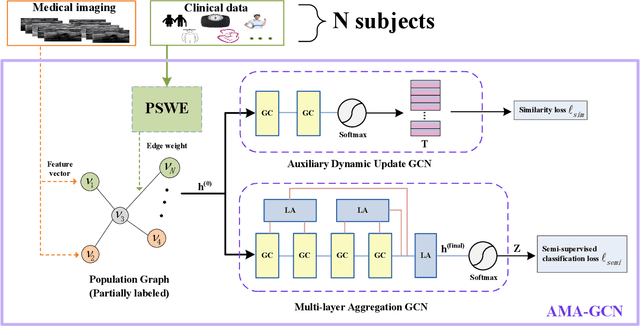
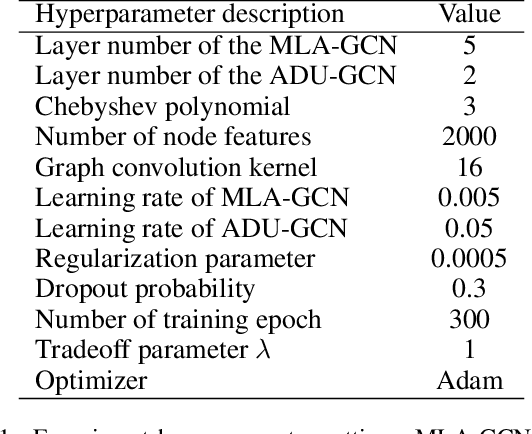
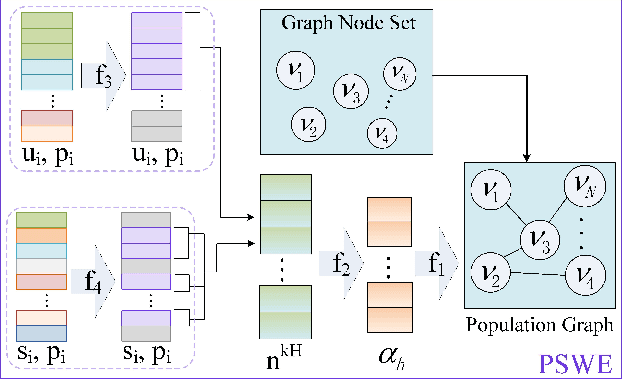
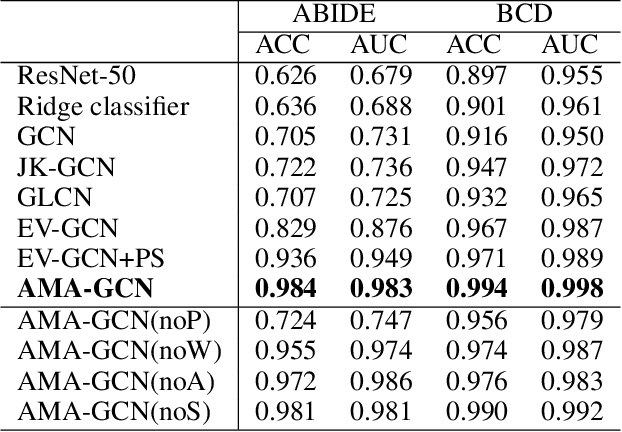
Recently, Graph Convolutional Networks (GCNs) have proven to be a powerful mean for Computer Aided Diagnosis (CADx). This approach requires building a population graph to aggregate structural information, where the graph adjacency matrix represents the relationship between nodes. Until now, this adjacency matrix is usually defined manually based on phenotypic information. In this paper, we propose an encoder that automatically selects the appropriate phenotypic measures according to their spatial distribution, and uses the text similarity awareness mechanism to calculate the edge weights between nodes. The encoder can automatically construct the population graph using phenotypic measures which have a positive impact on the final results, and further realizes the fusion of multimodal information. In addition, a novel graph convolution network architecture using multi-layer aggregation mechanism is proposed. The structure can obtain deep structure information while suppressing over-smooth, and increase the similarity between the same type of nodes. Experimental results on two databases show that our method can significantly improve the diagnostic accuracy for Autism spectrum disorder and breast cancer, indicating its universality in leveraging multimodal data for disease prediction.