 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-branch Graph Domain Adaptation for Cross-scenario Multi-modal Emotion Recognition
Mar 27, 2026Multimodal Emotion Recognition in Conversations (MERC) aims to predict speakers' emotional states in multi-turn dialogues through text, audio, and visual cues. In real-world settings, conversation scenarios differ significantly in speakers, topics, styles, and noise levels. Existing MERC methods generally neglect these cross-scenario variations, limiting their ability to transfer models trained on a source domain to unseen target domains. To address this issue, we propose a Dual-branch Graph Domain Adaptation framework (DGDA) for multimodal emotion recognition under cross-scenario conditions. We first construct an emotion interaction graph to characterize complex emotional dependencies among utterances. A dual-branch encoder, consisting of a hypergraph neural network (HGNN) and a path neural network (PathNN), is then designed to explicitly model multivariate relationships and implicitly capture global dependencies. To enable out-of-domain generalization, a domain adversarial discriminator is introduced to learn invariant representations across domains. Furthermore, a regularization loss is incorporated to suppress the negative influence of noisy labels. To the best of our knowledge, DGDA is the first MERC framework that jointly addresses domain shift and label noise. Theoretical analysis provides tighter generalization bounds, and extensive experiments on IEMOCAP and MELD demonstrate that DGDA consistently outperforms strong baselines and better adapts to cross-scenario conversations. Our code is available at https://github.com/Xudmm1239439/DGDA-Net.
Relational graph-driven differential denoising and diffusion attention fusion for multimodal conversation emotion recognition
Mar 22, 2026In real-world scenarios, audio and video signals are often subject to environmental noise and limited acquisition conditions, resulting in extracted features containing excessive noise. Furthermore, there is an imbalance in data quality and information carrying capacity between different modalities. These two issues together lead to information distortion and weight bias during the fusion phase, impairing overall recognition performance. Most existing methods neglect the impact of noisy modalities and rely on implicit weighting to model modality importance, thereby failing to explicitly account for the predominant contribution of the textual modality in emotion understanding. To address these issues, we propose a relation-aware denoising and diffusion attention fusion model for MCER. Specifically, we first design a differential Transformer that explicitly computes the differences between two attention maps, thereby enhancing temporally consistent information while suppressing time-irrelevant noise, which leads to effective denoising in both audio and video modalities. Second, we construct modality-specific and cross-modality relation subgraphs to capture speaker-dependent emotional dependencies, enabling fine-grained modeling of intra- and inter-modal relationships. Finally, we introduce a text-guided cross-modal diffusion mechanism that leverages self-attention to model intra-modal dependencies and adaptively diffuses audiovisual information into the textual stream, ensuring more robust and semantically aligned multimodal fusion.
* 19 pages
Dynamic Fusion-Aware Graph Convolutional Neural Network for Multimodal Emotion Recognition in Conversations
Mar 22, 2026Multimodal emotion recognition in conversations (MERC) aims to identify and understand the emotions expressed by speakers during utterance interaction from multiple modalities (e.g., text, audio, images, etc.). Existing studies have shown that GCN can improve the performance of MERC by modeling dependencies between speakers. However, existing methods usually use fixed parameters to process multimodal features for different emotion types, ignoring the dynamics of fusion between different modalities, which forces the model to balance performance between multiple emotion categories, thus limiting the model's performance on some specific emotions. To this end, we propose a dynamic fusion-aware graph convolutional neural network (DF-GCN) for robust recognition of multimodal emotion features in conversations. Specifically, DF-GCN integrates ordinary differential equations into graph convolutional networks (GCNs) to {capture} the dynamic nature of emotional dependencies within utterance interaction networks and leverages the prompts generated by the global information vector (GIV) of the utterance to guide the dynamic fusion of multimodal features. This allows our model to dynamically change parameters when processing each utterance feature, so that different network parameters can be equipped for different emotion categories in the inference stage, thereby achieving more flexible emotion classification and enhancing the generalization ability of the model. Comprehensive experiments conducted on two public multimodal conversational datasets {confirm} that the proposed DF-GCN model delivers superior performance, benefiting significantly from the dynamic fusion mechanism introduced.
Layout-Guided Controllable Pathology Image Generation with In-Context Diffusion Transformers
Mar 11, 2026Controllable pathology image synthesis requires reliable regulation of spatial layout, tissue morphology, and semantic detail. However, existing text-guided diffusion models offer only coarse global control and lack the ability to enforce fine-grained structural constraints. Progress is further limited by the absence of large datasets that pair patch-level spatial layouts with detailed diagnostic descriptions, since generating such annotations for gigapixel whole-slide images is prohibitively time-consuming for human experts. To overcome these challenges, we first develop a scalable multi-agent LVLM annotation framework that integrates image description, diagnostic step extraction, and automatic quality judgment into a coordinated pipeline, and we evaluate the reliability of the system through a human verification process. This framework enables efficient construction of fine-grained and clinically aligned supervision at scale. Building on the curated data, we propose In-Context Diffusion Transformer (IC-DiT), a layout-aware generative model that incorporates spatial layouts, textual descriptions, and visual embeddings into a unified diffusion transformer. Through hierarchical multimodal attention, IC-DiT maintains global semantic coherence while accurately preserving structural and morphological details. Extensive experiments on five histopathology datasets show that IC-DiT achieves higher fidelity, stronger spatial controllability, and better diagnostic consistency than existing methods. In addition, the generated images serve as effective data augmentation resources for downstream tasks such as cancer classification and survival analysis.
The Paradigm Shift: A Comprehensive Survey on Large Vision Language Models for Multimodal Fake News Detection
Jan 16, 2026In recent years, the rapid evolution of large vision-language models (LVLMs) has driven a paradigm shift in multimodal fake news detection (MFND), transforming it from traditional feature-engineering approaches to unified, end-to-end multimodal reasoning frameworks. Early methods primarily relied on shallow fusion techniques to capture correlations between text and images, but they struggled with high-level semantic understanding and complex cross-modal interactions. The emergence of LVLMs has fundamentally changed this landscape by enabling joint modeling of vision and language with powerful representation learning, thereby enhancing the ability to detect misinformation that leverages both textual narratives and visual content. Despite these advances, the field lacks a systematic survey that traces this transition and consolidates recent developments. To address this gap, this paper provides a comprehensive review of MFND through the lens of LVLMs. We first present a historical perspective, mapping the evolution from conventional multimodal detection pipelines to foundation model-driven paradigms. Next, we establish a structured taxonomy covering model architectures, datasets, and performance benchmarks. Furthermore, we analyze the remaining technical challenges, including interpretability, temporal reasoning, and domain generalization. Finally, we outline future research directions to guide the next stage of this paradigm shift. To the best of our knowledge, this is the first comprehensive survey to systematically document and analyze the transformative role of LVLMs in combating multimodal fake news. The summary of existing methods mentioned is in our Github: \href{https://github.com/Tan-YiLong/Overview-of-Fake-News-Detection}{https://github.com/Tan-YiLong/Overview-of-Fake-News-Detection}.
GSDNet: Revisiting Incomplete Multimodal-Diffusion from Graph Spectrum Perspective for Conversation Emotion Recognition
Jun 14, 2025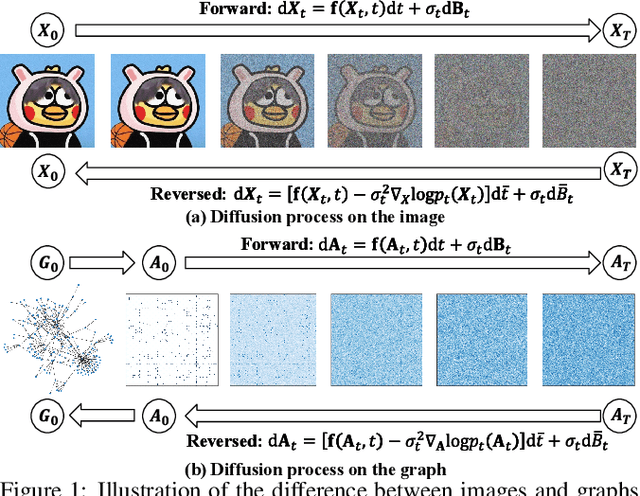
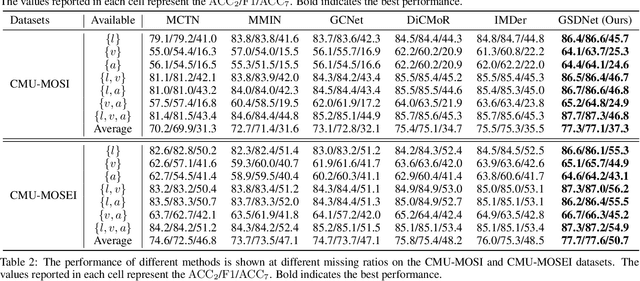
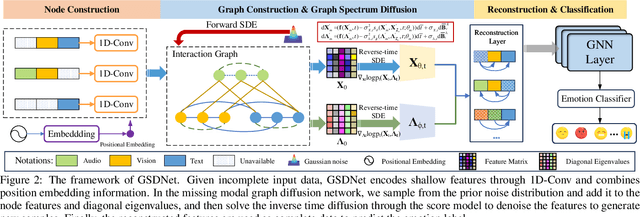
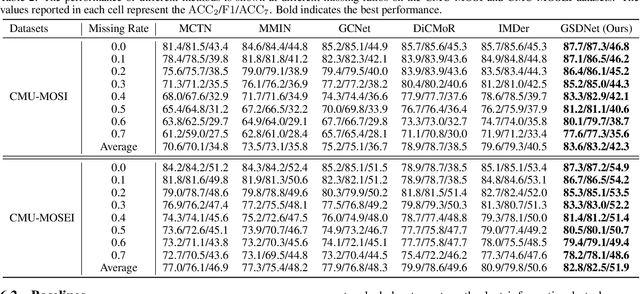
Multimodal emotion recognition in conversations (MERC) aims to infer the speaker's emotional state by analyzing utterance information from multiple sources (i.e., video, audio, and text). Compared with unimodality, a more robust utterance representation can be obtained by fusing complementary semantic information from different modalities. However, the modality missing problem severely limits the performance of MERC in practical scenarios. Recent work has achieved impressive performance on modality completion using graph neural networks and diffusion models, respectively. This inspires us to combine these two dimensions through the graph diffusion model to obtain more powerful modal recovery capabilities. Unfortunately, existing graph diffusion models may destroy the connectivity and local structure of the graph by directly adding Gaussian noise to the adjacency matrix, resulting in the generated graph data being unable to retain the semantic and topological information of the original graph. To this end, we propose a novel Graph Spectral Diffusion Network (GSDNet), which maps Gaussian noise to the graph spectral space of missing modalities and recovers the missing data according to its original distribution. Compared with previous graph diffusion methods, GSDNet only affects the eigenvalues of the adjacency matrix instead of destroying the adjacency matrix directly, which can maintain the global topological information and important spectral features during the diffusion process. Extensive experiments have demonstrated that GSDNet achieves state-of-the-art emotion recognition performance in various modality loss scenarios.
SE-GNN: Seed Expanded-Aware Graph Neural Network with Iterative Optimization for Semi-supervised Entity Alignment
Mar 24, 2025Entity alignment aims to use pre-aligned seed pairs to find other equivalent entities from different knowledge graphs (KGs) and is widely used in graph fusion-related fields. However, as the scale of KGs increases, manually annotating pre-aligned seed pairs becomes difficult. Existing research utilizes entity embeddings obtained by aggregating single structural information to identify potential seed pairs, thus reducing the reliance on pre-aligned seed pairs. However, due to the structural heterogeneity of KGs, the quality of potential seed pairs obtained using only a single structural information is not ideal. In addition, although existing research improves the quality of potential seed pairs through semi-supervised iteration, they underestimate the impact of embedding distortion produced by noisy seed pairs on the alignment effect. In order to solve the above problems, we propose a seed expanded-aware graph neural network with iterative optimization for semi-supervised entity alignment, named SE-GNN. First, we utilize the semantic attributes and structural features of entities, combined with a conditional filtering mechanism, to obtain high-quality initial potential seed pairs. Next, we designed a local and global awareness mechanism. It introduces initial potential seed pairs and combines local and global information to obtain a more comprehensive entity embedding representation, which alleviates the impact of KGs structural heterogeneity and lays the foundation for the optimization of initial potential seed pairs. Then, we designed the threshold nearest neighbor embedding correction strategy. It combines the similarity threshold and the bidirectional nearest neighbor method as a filtering mechanism to select iterative potential seed pairs and also uses an embedding correction strategy to eliminate the embedding distortion.
LRA-GNN: Latent Relation-Aware Graph Neural Network with Initial and Dynamic Residual for Facial Age Estimation
Feb 08, 2025Face information is mainly concentrated among facial key points, and frontier research has begun to use graph neural networks to segment faces into patches as nodes to model complex face representations. However, these methods construct node-to-node relations based on similarity thresholds, so there is a problem that some latent relations are missing. These latent relations are crucial for deep semantic representation of face aging. In this novel, we propose a new Latent Relation-Aware Graph Neural Network with Initial and Dynamic Residual (LRA-GNN) to achieve robust and comprehensive facial representation. Specifically, we first construct an initial graph utilizing facial key points as prior knowledge, and then a random walk strategy is employed to the initial graph for obtaining the global structure, both of which together guide the subsequent effective exploration and comprehensive representation. Then LRA-GNN leverages the multi-attention mechanism to capture the latent relations and generates a set of fully connected graphs containing rich facial information and complete structure based on the aforementioned guidance. To avoid over-smoothing issues for deep feature extraction on the fully connected graphs, the deep residual graph convolutional networks are carefully designed, which fuse adaptive initial residuals and dynamic developmental residuals to ensure the consistency and diversity of information. Finally, to improve the estimation accuracy and generalization ability, progressive reinforcement learning is proposed to optimize the ensemble classification regressor. Our proposed framework surpasses the state-of-the-art baselines on several age estimation benchmarks, demonstrating its strength and effectiveness.
SE-GCL: An Event-Based Simple and Effective Graph Contrastive Learning for Text Representation
Dec 16, 2024



Text representation learning is significant as the cornerstone of natural language processing. In recent years, graph contrastive learning (GCL) has been widely used in text representation learning due to its ability to represent and capture complex text information in a self-supervised setting. However, current mainstream graph contrastive learning methods often require the incorporation of domain knowledge or cumbersome computations to guide the data augmentation process, which significantly limits the application efficiency and scope of GCL. Additionally, many methods learn text representations only by constructing word-document relationships, which overlooks the rich contextual semantic information in the text. To address these issues and exploit representative textual semantics, we present an event-based, simple, and effective graph contrastive learning (SE-GCL) for text representation. Precisely, we extract event blocks from text and construct internal relation graphs to represent inter-semantic interconnections, which can ensure that the most critical semantic information is preserved. Then, we devise a streamlined, unsupervised graph contrastive learning framework to leverage the complementary nature of the event semantic and structural information for intricate feature data capture. In particular, we introduce the concept of an event skeleton for core representation semantics and simplify the typically complex data augmentation techniques found in existing graph contrastive learning to boost algorithmic efficiency. We employ multiple loss functions to prompt diverse embeddings to converge or diverge within a confined distance in the vector space, ultimately achieving a harmonious equilibrium. We conducted experiments on the proposed SE-GCL on four standard data sets (AG News, 20NG, SougouNews, and THUCNews) to verify its effectiveness in text representation learning.
GroupFace: Imbalanced Age Estimation Based on Multi-hop Attention Graph Convolutional Network and Group-aware Margin Optimization
Dec 16, 2024

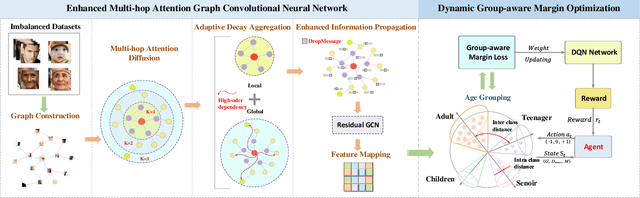
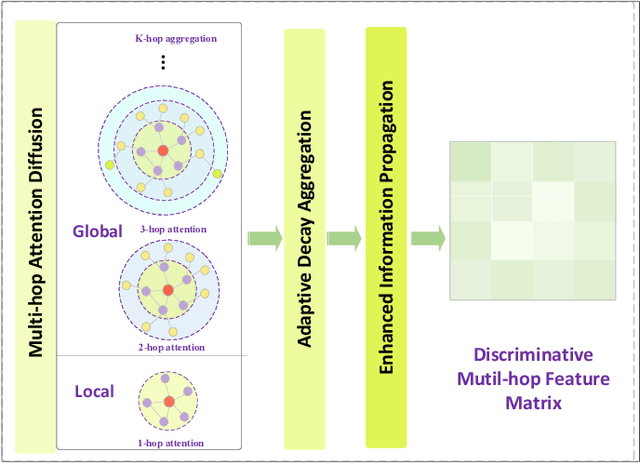
With the recent advances in computer vision, age estimation has significantly improved in overall accuracy. However, owing to the most common methods do not take into account the class imbalance problem in age estimation datasets, they suffer from a large bias in recognizing long-tailed groups. To achieve high-quality imbalanced learning in long-tailed groups, the dominant solution lies in that the feature extractor learns the discriminative features of different groups and the classifier is able to provide appropriate and unbiased margins for different groups by the discriminative features. Therefore, in this novel, we propose an innovative collaborative learning framework (GroupFace) that integrates a multi-hop attention graph convolutional network and a dynamic group-aware margin strategy based on reinforcement learning. Specifically, to extract the discriminative features of different groups, we design an enhanced multi-hop attention graph convolutional network. This network is capable of capturing the interactions of neighboring nodes at different distances, fusing local and global information to model facial deep aging, and exploring diverse representations of different groups. In addition, to further address the class imbalance problem, we design a dynamic group-aware margin strategy based on reinforcement learning to provide appropriate and unbiased margins for different groups. The strategy divides the sample into four age groups and considers identifying the optimum margins for various age groups by employing a Markov decision process. Under the guidance of the agent, the feature representation bias and the classification margin deviation between different groups can be reduced simultaneously, balancing inter-class separability and intra-class proximity. After joint optimization, our architecture achieves excellent performance on several age estimation benchmark datasets.