 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSE-GNN: Seed Expanded-Aware Graph Neural Network with Iterative Optimization for Semi-supervised Entity Alignment
Mar 24, 2025Entity alignment aims to use pre-aligned seed pairs to find other equivalent entities from different knowledge graphs (KGs) and is widely used in graph fusion-related fields. However, as the scale of KGs increases, manually annotating pre-aligned seed pairs becomes difficult. Existing research utilizes entity embeddings obtained by aggregating single structural information to identify potential seed pairs, thus reducing the reliance on pre-aligned seed pairs. However, due to the structural heterogeneity of KGs, the quality of potential seed pairs obtained using only a single structural information is not ideal. In addition, although existing research improves the quality of potential seed pairs through semi-supervised iteration, they underestimate the impact of embedding distortion produced by noisy seed pairs on the alignment effect. In order to solve the above problems, we propose a seed expanded-aware graph neural network with iterative optimization for semi-supervised entity alignment, named SE-GNN. First, we utilize the semantic attributes and structural features of entities, combined with a conditional filtering mechanism, to obtain high-quality initial potential seed pairs. Next, we designed a local and global awareness mechanism. It introduces initial potential seed pairs and combines local and global information to obtain a more comprehensive entity embedding representation, which alleviates the impact of KGs structural heterogeneity and lays the foundation for the optimization of initial potential seed pairs. Then, we designed the threshold nearest neighbor embedding correction strategy. It combines the similarity threshold and the bidirectional nearest neighbor method as a filtering mechanism to select iterative potential seed pairs and also uses an embedding correction strategy to eliminate the embedding distortion.
Masked Graph Learning with Recurrent Alignment for Multimodal Emotion Recognition in Conversation
Jul 23, 2024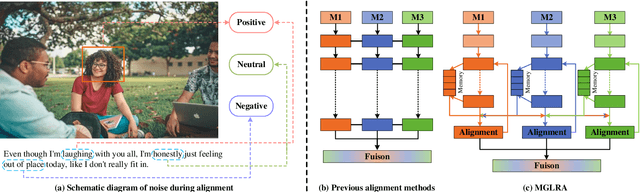



Since Multimodal Emotion Recognition in Conversation (MERC) can be applied to public opinion monitoring, intelligent dialogue robots, and other fields, it has received extensive research attention in recent years. Unlike traditional unimodal emotion recognition, MERC can fuse complementary semantic information between multiple modalities (e.g., text, audio, and vision) to improve emotion recognition. However, previous work ignored the inter-modal alignment process and the intra-modal noise information before multimodal fusion but directly fuses multimodal features, which will hinder the model for representation learning. In this study, we have developed a novel approach called Masked Graph Learning with Recursive Alignment (MGLRA) to tackle this problem, which uses a recurrent iterative module with memory to align multimodal features, and then uses the masked GCN for multimodal feature fusion. First, we employ LSTM to capture contextual information and use a graph attention-filtering mechanism to eliminate noise effectively within the modality. Second, we build a recurrent iteration module with a memory function, which can use communication between different modalities to eliminate the gap between modalities and achieve the preliminary alignment of features between modalities. Then, a cross-modal multi-head attention mechanism is introduced to achieve feature alignment between modalities and construct a masked GCN for multimodal feature fusion, which can perform random mask reconstruction on the nodes in the graph to obtain better node feature representation. Finally, we utilize a multilayer perceptron (MLP) for emotion recognition. Extensive experiments on two benchmark datasets (i.e., IEMOCAP and MELD) demonstrate that {MGLRA} outperforms state-of-the-art methods.