 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Graph Learning with Recurrent Alignment for Multimodal Emotion Recognition in Conversation
Jul 23, 2024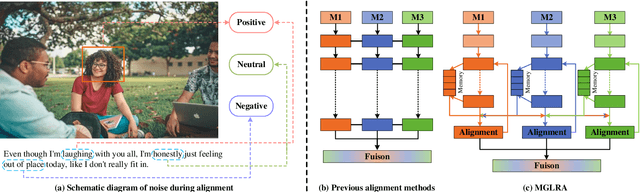



Since Multimodal Emotion Recognition in Conversation (MERC) can be applied to public opinion monitoring, intelligent dialogue robots, and other fields, it has received extensive research attention in recent years. Unlike traditional unimodal emotion recognition, MERC can fuse complementary semantic information between multiple modalities (e.g., text, audio, and vision) to improve emotion recognition. However, previous work ignored the inter-modal alignment process and the intra-modal noise information before multimodal fusion but directly fuses multimodal features, which will hinder the model for representation learning. In this study, we have developed a novel approach called Masked Graph Learning with Recursive Alignment (MGLRA) to tackle this problem, which uses a recurrent iterative module with memory to align multimodal features, and then uses the masked GCN for multimodal feature fusion. First, we employ LSTM to capture contextual information and use a graph attention-filtering mechanism to eliminate noise effectively within the modality. Second, we build a recurrent iteration module with a memory function, which can use communication between different modalities to eliminate the gap between modalities and achieve the preliminary alignment of features between modalities. Then, a cross-modal multi-head attention mechanism is introduced to achieve feature alignment between modalities and construct a masked GCN for multimodal feature fusion, which can perform random mask reconstruction on the nodes in the graph to obtain better node feature representation. Finally, we utilize a multilayer perceptron (MLP) for emotion recognition. Extensive experiments on two benchmark datasets (i.e., IEMOCAP and MELD) demonstrate that {MGLRA} outperforms state-of-the-art methods.
Revisiting Multi-modal Emotion Learning with Broad State Space Models and Probability-guidance Fusion
Apr 27, 2024Multi-modal Emotion Recognition in Conversation (MERC) has received considerable attention in various fields, e.g., human-computer interaction and recommendation systems. Most existing works perform feature disentanglement and fusion to extract emotional contextual information from multi-modal features and emotion classification. After revisiting the characteristic of MERC, we argue that long-range contextual semantic information should be extracted in the feature disentanglement stage and the inter-modal semantic information consistency should be maximized in the feature fusion stage. Inspired by recent State Space Models (SSMs), Mamba can efficiently model long-distance dependencies. Therefore, in this work, we fully consider the above insights to further improve the performance of MERC. Specifically, on the one hand, in the feature disentanglement stage, we propose a Broad Mamba, which does not rely on a self-attention mechanism for sequence modeling, but uses state space models to compress emotional representation, and utilizes broad learning systems to explore the potential data distribution in broad space. Different from previous SSMs, we design a bidirectional SSM convolution to extract global context information. On the other hand, we design a multi-modal fusion strategy based on probability guidance to maximize the consistency of information between modalities. Experimental results show that the proposed method can overcome the computational and memory limitations of Transformer when modeling long-distance contexts, and has great potential to become a next-generation general architecture in MERC.
Revisiting Multimodal Emotion Recognition in Conversation from the Perspective of Graph Spectrum
Apr 27, 2024Efficiently capturing consistent and complementary semantic features in a multimodal conversation context is crucial for Multimodal Emotion Recognition in Conversation (MERC). Existing methods mainly use graph structures to model dialogue context semantic dependencies and employ Graph Neural Networks (GNN) to capture multimodal semantic features for emotion recognition. However, these methods are limited by some inherent characteristics of GNN, such as over-smoothing and low-pass filtering, resulting in the inability to learn long-distance consistency information and complementary information efficiently. Since consistency and complementarity information correspond to low-frequency and high-frequency information, respectively, this paper revisits the problem of multimodal emotion recognition in conversation from the perspective of the graph spectrum. Specifically, we propose a Graph-Spectrum-based Multimodal Consistency and Complementary collaborative learning framework GS-MCC. First, GS-MCC uses a sliding window to construct a multimodal interaction graph to model conversational relationships and uses efficient Fourier graph operators to extract long-distance high-frequency and low-frequency information, respectively. Then, GS-MCC uses contrastive learning to construct self-supervised signals that reflect complementarity and consistent semantic collaboration with high and low-frequency signals, thereby improving the ability of high and low-frequency information to reflect real emotions. Finally, GS-MCC inputs the collaborative high and low-frequency information into the MLP network and softmax function for emotion prediction. Extensive experiments have proven the superiority of the GS-MCC architecture proposed in this paper on two benchmark data sets.