 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Mixture Models and Surrogate Models for Precision Additive Manufacturing
Oct 30, 2025In this study, we leverage a mixture model learning approach to identify defects in laser-based Additive Manufacturing (AM) processes. By incorporating physics based principles, we also ensure that the model is sensitive to meaningful physical parameter variations. The empirical evaluation was conducted by analyzing real-world data from two AM processes: Directed Energy Deposition and Laser Powder Bed Fusion. In addition, we also studied the performance of the developed framework over public datasets with different alloy type and experimental parameter information. The results show the potential of physics-guided mixture models to examine the underlying physical behavior of an AM system.
SE-GNN: Seed Expanded-Aware Graph Neural Network with Iterative Optimization for Semi-supervised Entity Alignment
Mar 24, 2025Entity alignment aims to use pre-aligned seed pairs to find other equivalent entities from different knowledge graphs (KGs) and is widely used in graph fusion-related fields. However, as the scale of KGs increases, manually annotating pre-aligned seed pairs becomes difficult. Existing research utilizes entity embeddings obtained by aggregating single structural information to identify potential seed pairs, thus reducing the reliance on pre-aligned seed pairs. However, due to the structural heterogeneity of KGs, the quality of potential seed pairs obtained using only a single structural information is not ideal. In addition, although existing research improves the quality of potential seed pairs through semi-supervised iteration, they underestimate the impact of embedding distortion produced by noisy seed pairs on the alignment effect. In order to solve the above problems, we propose a seed expanded-aware graph neural network with iterative optimization for semi-supervised entity alignment, named SE-GNN. First, we utilize the semantic attributes and structural features of entities, combined with a conditional filtering mechanism, to obtain high-quality initial potential seed pairs. Next, we designed a local and global awareness mechanism. It introduces initial potential seed pairs and combines local and global information to obtain a more comprehensive entity embedding representation, which alleviates the impact of KGs structural heterogeneity and lays the foundation for the optimization of initial potential seed pairs. Then, we designed the threshold nearest neighbor embedding correction strategy. It combines the similarity threshold and the bidirectional nearest neighbor method as a filtering mechanism to select iterative potential seed pairs and also uses an embedding correction strategy to eliminate the embedding distortion.
MobileFlow: A Multimodal LLM For Mobile GUI Agent
Jul 05, 2024Currently, the integration of mobile Graphical User Interfaces (GUIs) is ubiquitous in most people's daily lives. And the ongoing evolution of multimodal large-scale models, such as GPT-4v, Qwen-VL-Max, has significantly bolstered the capabilities of GUI comprehension and user action analysis, showcasing the potentiality of intelligent GUI assistants. However, current GUI Agents often need to access page layout information through calling system APIs, which may pose privacy risks. Fixing GUI (such as mobile interfaces) to a certain low resolution might result in the loss of fine-grained image details. At the same time, the multimodal large models built for GUI Agents currently have poor understanding and decision-making abilities for Chinese GUI interfaces, making them difficult to apply to a large number of Chinese apps. This paper introduces MobileFlow, a multimodal large language model meticulously crafted for mobile GUI agents. Transforming from the open-source model Qwen-VL-Chat into GUI domain, MobileFlow contains approximately 21 billion parameters and is equipped with novel hybrid visual encoders, making it possible for variable resolutions of image inputs and good support for multilingual GUI. By incorporating Mixture of Experts (MoE) expansions and pioneering alignment training strategies, MobileFlow has the capacity to fully interpret image data and comprehend user instructions for GUI interaction tasks. Finally, MobileFlow outperforms Qwen-VL-Max and GPT-4v in terms of task execution by GUI agents on both public and our proposed evaluation metrics, and has been successfully deployed in real-world business contexts, proving its effectiveness for practical applications.
Kernel Mean Estimation by Marginalized Corrupted Distributions
Jul 10, 2021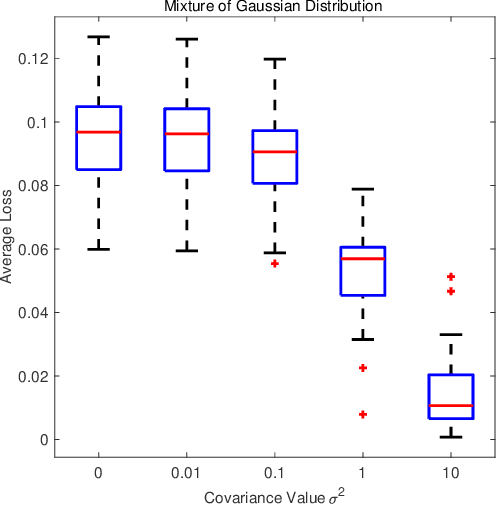
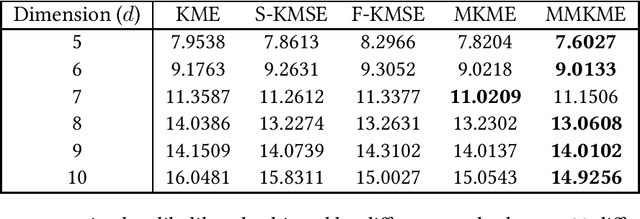
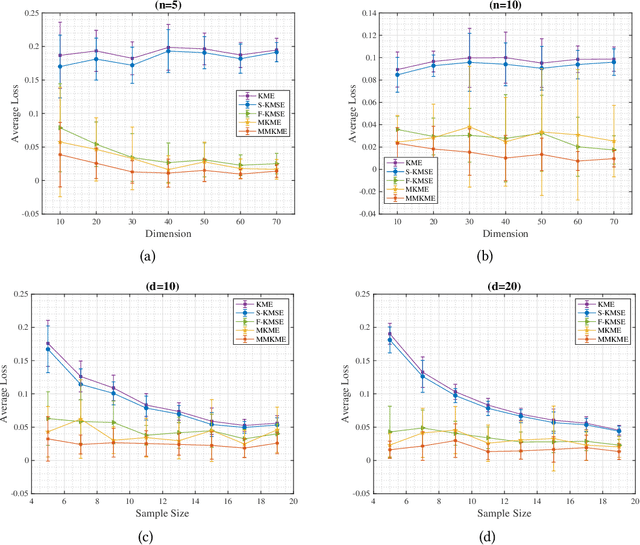
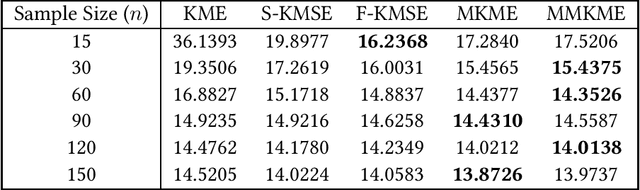
Estimating the kernel mean in a reproducing kernel Hilbert space is a critical component in many kernel learning algorithms. Given a finite sample, the standard estimate of the target kernel mean is the empirical average. Previous works have shown that better estimators can be constructed by shrinkage methods. In this work, we propose to corrupt data examples with noise from known distributions and present a new kernel mean estimator, called the marginalized kernel mean estimator, which estimates kernel mean under the corrupted distribution. Theoretically, we show that the marginalized kernel mean estimator introduces implicit regularization in kernel mean estimation. Empirically, we show on a variety of datasets that the marginalized kernel mean estimator obtains much lower estimation error than the existing estimators.