 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobileFlow: A Multimodal LLM For Mobile GUI Agent
Jul 05, 2024Currently, the integration of mobile Graphical User Interfaces (GUIs) is ubiquitous in most people's daily lives. And the ongoing evolution of multimodal large-scale models, such as GPT-4v, Qwen-VL-Max, has significantly bolstered the capabilities of GUI comprehension and user action analysis, showcasing the potentiality of intelligent GUI assistants. However, current GUI Agents often need to access page layout information through calling system APIs, which may pose privacy risks. Fixing GUI (such as mobile interfaces) to a certain low resolution might result in the loss of fine-grained image details. At the same time, the multimodal large models built for GUI Agents currently have poor understanding and decision-making abilities for Chinese GUI interfaces, making them difficult to apply to a large number of Chinese apps. This paper introduces MobileFlow, a multimodal large language model meticulously crafted for mobile GUI agents. Transforming from the open-source model Qwen-VL-Chat into GUI domain, MobileFlow contains approximately 21 billion parameters and is equipped with novel hybrid visual encoders, making it possible for variable resolutions of image inputs and good support for multilingual GUI. By incorporating Mixture of Experts (MoE) expansions and pioneering alignment training strategies, MobileFlow has the capacity to fully interpret image data and comprehend user instructions for GUI interaction tasks. Finally, MobileFlow outperforms Qwen-VL-Max and GPT-4v in terms of task execution by GUI agents on both public and our proposed evaluation metrics, and has been successfully deployed in real-world business contexts, proving its effectiveness for practical applications.
MATEval: A Multi-Agent Discussion Framework for Advancing Open-Ended Text Evaluation
Mar 28, 2024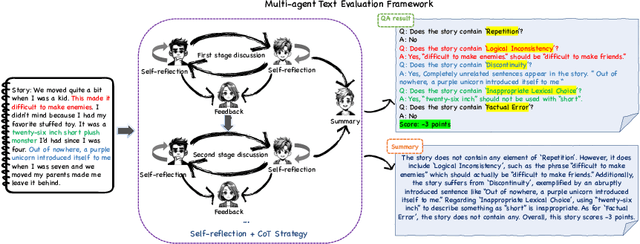


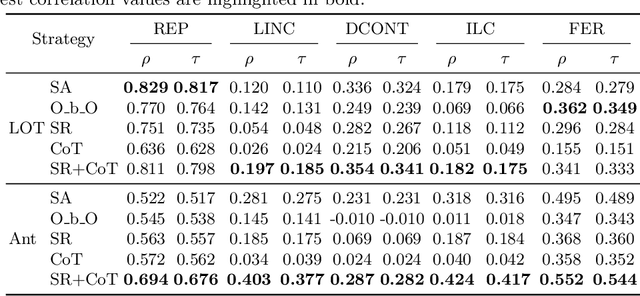
Recent advancements in generative Large Language Models(LLMs) have been remarkable, however, the quality of the text generated by these models often reveals persistent issues. Evaluating the quality of text generated by these models, especially in open-ended text, has consistently presented a significant challenge. Addressing this, recent work has explored the possibility of using LLMs as evaluators. While using a single LLM as an evaluation agent shows potential, it is filled with significant uncertainty and instability. To address these issues, we propose the MATEval: A "Multi-Agent Text Evaluation framework" where all agents are played by LLMs like GPT-4. The MATEval framework emulates human collaborative discussion methods, integrating multiple agents' interactions to evaluate open-ended text. Our framework incorporates self-reflection and Chain-of-Thought (CoT) strategies, along with feedback mechanisms, enhancing the depth and breadth of the evaluation process and guiding discussions towards consensus, while the framework generates comprehensive evaluation reports, including error localization, error types and scoring. Experimental results show that our framework outperforms existing open-ended text evaluation methods and achieves the highest correlation with human evaluation, which confirms the effectiveness and advancement of our framework in addressing the uncertainties and instabilities in evaluating LLMs-generated text. Furthermore, our framework significantly improves the efficiency of text evaluation and model iteration in industrial scenarios.
DEE: Dual-stage Explainable Evaluation Method for Text Generation
Mar 18, 2024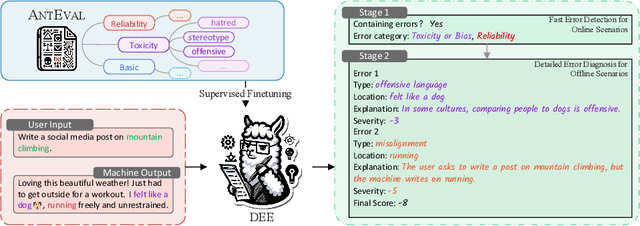
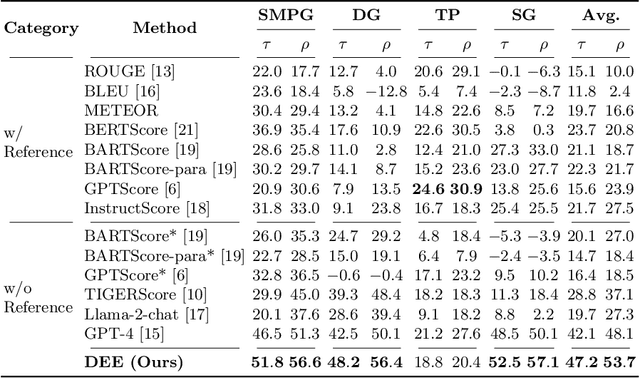
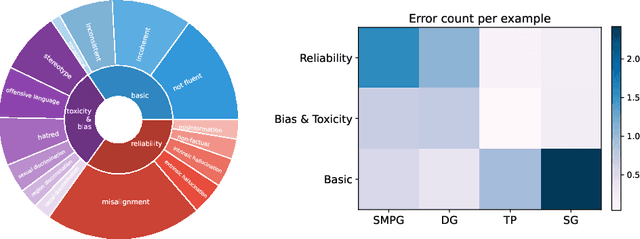

Automatic methods for evaluating machine-generated texts hold significant importance due to the expanding applications of generative systems. Conventional methods tend to grapple with a lack of explainability, issuing a solitary numerical score to signify the assessment outcome. Recent advancements have sought to mitigate this limitation by incorporating large language models (LLMs) to offer more detailed error analyses, yet their applicability remains constrained, particularly in industrial contexts where comprehensive error coverage and swift detection are paramount. To alleviate these challenges, we introduce DEE, a Dual-stage Explainable Evaluation method for estimating the quality of text generation. Built upon Llama 2, DEE follows a dual-stage principle guided by stage-specific instructions to perform efficient identification of errors in generated texts in the initial stage and subsequently delves into providing comprehensive diagnostic reports in the second stage. DEE is fine-tuned on our elaborately assembled dataset AntEval, which encompasses 15K examples from 4 real-world applications of Alipay that employ generative systems. The dataset concerns newly emerged issues like hallucination and toxicity, thereby broadening the scope of DEE's evaluation criteria. Experimental results affirm that DEE's superiority over existing evaluation methods, achieving significant improvements in both human correlation as well as efficiency.