 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEE: Dual-stage Explainable Evaluation Method for Text Generation
Paper and Code
Mar 18, 2024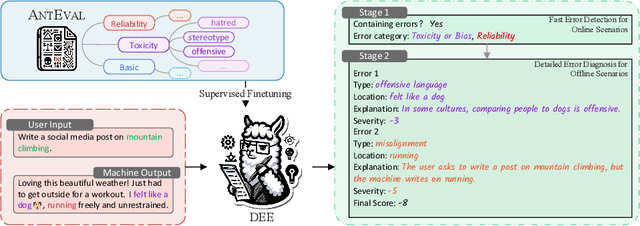
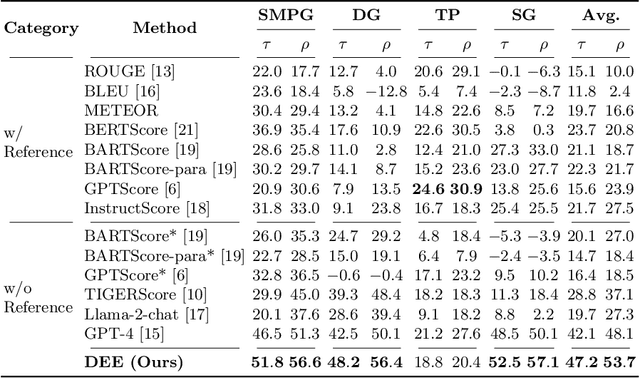
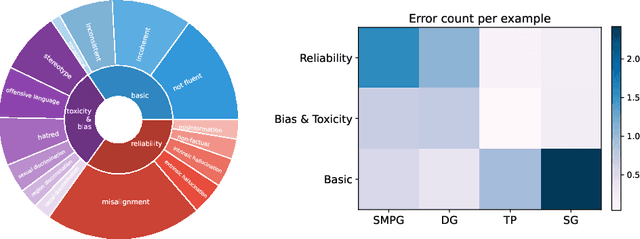

Automatic methods for evaluating machine-generated texts hold significant importance due to the expanding applications of generative systems. Conventional methods tend to grapple with a lack of explainability, issuing a solitary numerical score to signify the assessment outcome. Recent advancements have sought to mitigate this limitation by incorporating large language models (LLMs) to offer more detailed error analyses, yet their applicability remains constrained, particularly in industrial contexts where comprehensive error coverage and swift detection are paramount. To alleviate these challenges, we introduce DEE, a Dual-stage Explainable Evaluation method for estimating the quality of text generation. Built upon Llama 2, DEE follows a dual-stage principle guided by stage-specific instructions to perform efficient identification of errors in generated texts in the initial stage and subsequently delves into providing comprehensive diagnostic reports in the second stage. DEE is fine-tuned on our elaborately assembled dataset AntEval, which encompasses 15K examples from 4 real-world applications of Alipay that employ generative systems. The dataset concerns newly emerged issues like hallucination and toxicity, thereby broadening the scope of DEE's evaluation criteria. Experimental results affirm that DEE's superiority over existing evaluation methods, achieving significant improvements in both human correlation as well as efficiency.