 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpiQAL: Benchmarking Large Language Models in Epidemiological Question Answering for Enhanced Alignment and Reasoning
Jan 06, 2026Reliable epidemiological reasoning requires synthesizing study evidence to infer disease burden, transmission dynamics, and intervention effects at the population level. Existing medical question answering benchmarks primarily emphasize clinical knowledge or patient-level reasoning, yet few systematically evaluate evidence-grounded epidemiological inference. We present EpiQAL, the first diagnostic benchmark for epidemiological question answering across diverse diseases, comprising three subsets built from open-access literature. The subsets respectively evaluate text-grounded factual recall, multi-step inference linking document evidence with epidemiological principles, and conclusion reconstruction with the Discussion section withheld. Construction combines expert-designed taxonomy guidance, multi-model verification, and retrieval-based difficulty control. Experiments on ten open models reveal that current LLMs show limited performance on epidemiological reasoning, with multi-step inference posing the greatest challenge. Model rankings shift across subsets, and scale alone does not predict success. Chain-of-Thought prompting benefits multi-step inference but yields mixed results elsewhere. EpiQAL provides fine-grained diagnostic signals for evidence grounding, inferential reasoning, and conclusion reconstruction.
QuCo-RAG: Quantifying Uncertainty from the Pre-training Corpus for Dynamic Retrieval-Augmented Generation
Dec 22, 2025Dynamic Retrieval-Augmented Generation adaptively determines when to retrieve during generation to mitigate hallucinations in large language models (LLMs). However, existing methods rely on model-internal signals (e.g., logits, entropy), which are fundamentally unreliable because LLMs are typically ill-calibrated and often exhibit high confidence in erroneous outputs. We propose QuCo-RAG, which shifts from subjective confidence to objective statistics computed from pre-training data. Our method quantifies uncertainty through two stages: (1) before generation, we identify low-frequency entities indicating long-tail knowledge gaps; (2) during generation, we verify entity co-occurrence in the pre-training corpus, where zero co-occurrence often signals hallucination risk. Both stages leverage Infini-gram for millisecond-latency queries over 4 trillion tokens, triggering retrieval when uncertainty is high. Experiments on multi-hop QA benchmarks show QuCo-RAG achieves EM gains of 5--12 points over state-of-the-art baselines with OLMo-2 models, and transfers effectively to models with undisclosed pre-training data (Llama, Qwen, GPT), improving EM by up to 14 points. Domain generalization on biomedical QA further validates the robustness of our paradigm. These results establish corpus-grounded verification as a principled, practically model-agnostic paradigm for dynamic RAG. Our code is publicly available at https://github.com/ZhishanQ/QuCo-RAG.
MVI-Bench: A Comprehensive Benchmark for Evaluating Robustness to Misleading Visual Inputs in LVLMs
Nov 18, 2025

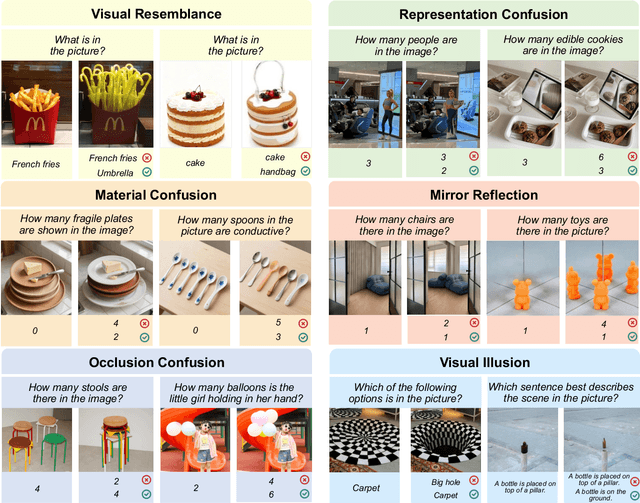

Evaluating the robustness of Large Vision-Language Models (LVLMs) is essential for their continued development and responsible deployment in real-world applications. However, existing robustness benchmarks typically focus on hallucination or misleading textual inputs, while largely overlooking the equally critical challenge posed by misleading visual inputs in assessing visual understanding. To fill this important gap, we introduce MVI-Bench, the first comprehensive benchmark specially designed for evaluating how Misleading Visual Inputs undermine the robustness of LVLMs. Grounded in fundamental visual primitives, the design of MVI-Bench centers on three hierarchical levels of misleading visual inputs: Visual Concept, Visual Attribute, and Visual Relationship. Using this taxonomy, we curate six representative categories and compile 1,248 expertly annotated VQA instances. To facilitate fine-grained robustness evaluation, we further introduce MVI-Sensitivity, a novel metric that characterizes LVLM robustness at a granular level. Empirical results across 18 state-of-the-art LVLMs uncover pronounced vulnerabilities to misleading visual inputs, and our in-depth analyses on MVI-Bench provide actionable insights that can guide the development of more reliable and robust LVLMs. The benchmark and codebase can be accessed at https://github.com/chenyil6/MVI-Bench.
Pandora: Leveraging Code-driven Knowledge Transfer for Unified Structured Knowledge Reasoning
Aug 25, 2025Unified Structured Knowledge Reasoning (USKR) aims to answer natural language questions by using structured sources such as tables, databases, and knowledge graphs in a unified way. Existing USKR methods rely on task-specific strategies or bespoke representations, which hinder their ability to dismantle barriers between different SKR tasks, thereby constraining their overall performance in cross-task scenarios. In this paper, we introduce \textsc{Pandora}, a novel USKR framework that addresses the limitations of existing methods by leveraging two key innovations. First, we propose a code-based unified knowledge representation using \textsc{Python}'s \textsc{Pandas} API, which aligns seamlessly with the pre-training of LLMs. This representation facilitates a cohesive approach to handling different structured knowledge sources. Building on this foundation, we employ knowledge transfer to bolster the unified reasoning process of LLMs by automatically building cross-task memory. By adaptively correcting reasoning using feedback from code execution, \textsc{Pandora} showcases impressive unified reasoning capabilities. Extensive experiments on six widely used benchmarks across three SKR tasks demonstrate that \textsc{Pandora} outperforms existing unified reasoning frameworks and competes effectively with task-specific methods.
Pandora: A Code-Driven Large Language Model Agent for Unified Reasoning Across Diverse Structured Knowledge
Apr 17, 2025



Unified Structured Knowledge Reasoning (USKR) aims to answer natural language questions (NLQs) by using structured sources such as tables, databases, and knowledge graphs in a unified way. Existing USKR methods either rely on employing task-specific strategies or custom-defined representations, which struggle to leverage the knowledge transfer between different SKR tasks or align with the prior of LLMs, thereby limiting their performance. This paper proposes a novel USKR framework named \textsc{Pandora}, which takes advantage of \textsc{Python}'s \textsc{Pandas} API to construct a unified knowledge representation for alignment with LLM pre-training. It employs an LLM to generate textual reasoning steps and executable Python code for each question. Demonstrations are drawn from a memory of training examples that cover various SKR tasks, facilitating knowledge transfer. Extensive experiments on four benchmarks involving three SKR tasks demonstrate that \textsc{Pandora} outperforms existing unified frameworks and competes effectively with task-specific methods.
UniHGKR: Unified Instruction-aware Heterogeneous Knowledge Retrievers
Oct 26, 2024



Existing information retrieval (IR) models often assume a homogeneous structure for knowledge sources and user queries, limiting their applicability in real-world settings where retrieval is inherently heterogeneous and diverse. In this paper, we introduce UniHGKR, a unified instruction-aware heterogeneous knowledge retriever that (1) builds a unified retrieval space for heterogeneous knowledge and (2) follows diverse user instructions to retrieve knowledge of specified types. UniHGKR consists of three principal stages: heterogeneous self-supervised pretraining, text-anchored embedding alignment, and instruction-aware retriever fine-tuning, enabling it to generalize across varied retrieval contexts. This framework is highly scalable, with a BERT-based version and a UniHGKR-7B version trained on large language models. Also, we introduce CompMix-IR, the first native heterogeneous knowledge retrieval benchmark. It includes two retrieval scenarios with various instructions, over 9,400 question-answer (QA) pairs, and a corpus of 10 million entries, covering four different types of data. Extensive experiments show that UniHGKR consistently outperforms state-of-the-art methods on CompMix-IR, achieving up to 6.36% and 54.23% relative improvements in two scenarios, respectively. Finally, by equipping our retriever for open-domain heterogeneous QA systems, we achieve a new state-of-the-art result on the popular ConvMix task, with an absolute improvement of up to 4.80 points.
HGT: Leveraging Heterogeneous Graph-enhanced Large Language Models for Few-shot Complex Table Understanding
Mar 28, 2024
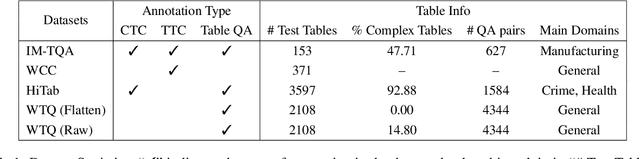

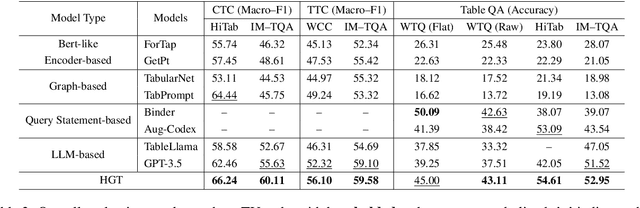
Table understanding (TU) has achieved promising advancements, but it faces the challenges of the scarcity of manually labeled tables and the presence of complex table structures.To address these challenges, we propose HGT, a framework with a heterogeneous graph (HG)-enhanced large language model (LLM) to tackle few-shot TU tasks.It leverages the LLM by aligning the table semantics with the LLM's parametric knowledge through soft prompts and instruction turning and deals with complex tables by a multi-task pre-training scheme involving three novel multi-granularity self-supervised HG pre-training objectives.We empirically demonstrate the effectiveness of HGT, showing that it outperforms the SOTA for few-shot complex TU on several benchmarks.
MATEval: A Multi-Agent Discussion Framework for Advancing Open-Ended Text Evaluation
Mar 28, 2024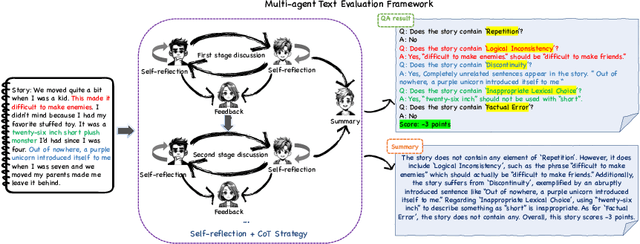


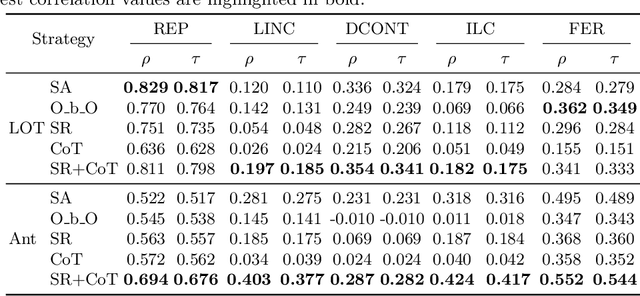
Recent advancements in generative Large Language Models(LLMs) have been remarkable, however, the quality of the text generated by these models often reveals persistent issues. Evaluating the quality of text generated by these models, especially in open-ended text, has consistently presented a significant challenge. Addressing this, recent work has explored the possibility of using LLMs as evaluators. While using a single LLM as an evaluation agent shows potential, it is filled with significant uncertainty and instability. To address these issues, we propose the MATEval: A "Multi-Agent Text Evaluation framework" where all agents are played by LLMs like GPT-4. The MATEval framework emulates human collaborative discussion methods, integrating multiple agents' interactions to evaluate open-ended text. Our framework incorporates self-reflection and Chain-of-Thought (CoT) strategies, along with feedback mechanisms, enhancing the depth and breadth of the evaluation process and guiding discussions towards consensus, while the framework generates comprehensive evaluation reports, including error localization, error types and scoring. Experimental results show that our framework outperforms existing open-ended text evaluation methods and achieves the highest correlation with human evaluation, which confirms the effectiveness and advancement of our framework in addressing the uncertainties and instabilities in evaluating LLMs-generated text. Furthermore, our framework significantly improves the efficiency of text evaluation and model iteration in industrial scenarios.
Exploring the Impact of Table-to-Text Methods on Augmenting LLM-based Question Answering with Domain Hybrid Data
Feb 20, 2024Augmenting Large Language Models (LLMs) for Question Answering (QA) with domain specific data has attracted wide attention. However, domain data often exists in a hybrid format, including text and semi-structured tables, posing challenges for the seamless integration of information. Table-to-Text Generation is a promising solution by facilitating the transformation of hybrid data into a uniformly text-formatted corpus. Although this technique has been widely studied by the NLP community, there is currently no comparative analysis on how corpora generated by different table-to-text methods affect the performance of QA systems. In this paper, we address this research gap in two steps. First, we innovatively integrate table-to-text generation into the framework of enhancing LLM-based QA systems with domain hybrid data. Then, we utilize this framework in real-world industrial data to conduct extensive experiments on two types of QA systems (DSFT and RAG frameworks) with four representative methods: Markdown format, Template serialization, TPLM-based method, and LLM-based method. Based on the experimental results, we draw some empirical findings and explore the underlying reasons behind the success of some methods. We hope the findings of this work will provide a valuable reference for the academic and industrial communities in developing robust QA systems.
An Empirical Study of Pre-trained Language Models in Simple Knowledge Graph Question Answering
Mar 18, 2023Large-scale pre-trained language models (PLMs) such as BERT have recently achieved great success and become a milestone in natural language processing (NLP). It is now the consensus of the NLP community to adopt PLMs as the backbone for downstream tasks. In recent works on knowledge graph question answering (KGQA), BERT or its variants have become necessary in their KGQA models. However, there is still a lack of comprehensive research and comparison of the performance of different PLMs in KGQA. To this end, we summarize two basic KGQA frameworks based on PLMs without additional neural network modules to compare the performance of nine PLMs in terms of accuracy and efficiency. In addition, we present three benchmarks for larger-scale KGs based on the popular SimpleQuestions benchmark to investigate the scalability of PLMs. We carefully analyze the results of all PLMs-based KGQA basic frameworks on these benchmarks and two other popular datasets, WebQuestionSP and FreebaseQA, and find that knowledge distillation techniques and knowledge enhancement methods in PLMs are promising for KGQA. Furthermore, we test ChatGPT, which has drawn a great deal of attention in the NLP community, demonstrating its impressive capabilities and limitations in zero-shot KGQA. We have released the code and benchmarks to promote the use of PLMs on KGQA.