 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Part Discovery via Descriptor-Based Masked Image Restoration with Optimized Constraints
Jul 16, 2025Part-level features are crucial for image understanding, but few studies focus on them because of the lack of fine-grained labels. Although unsupervised part discovery can eliminate the reliance on labels, most of them cannot maintain robustness across various categories and scenarios, which restricts their application range. To overcome this limitation, we present a more effective paradigm for unsupervised part discovery, named Masked Part Autoencoder (MPAE). It first learns part descriptors as well as a feature map from the inputs and produces patch features from a masked version of the original images. Then, the masked regions are filled with the learned part descriptors based on the similarity between the local features and descriptors. By restoring these masked patches using the part descriptors, they become better aligned with their part shapes, guided by appearance features from unmasked patches. Finally, MPAE robustly discovers meaningful parts that closely match the actual object shapes, even in complex scenarios. Moreover, several looser yet more effective constraints are proposed to enable MPAE to identify the presence of parts across various scenarios and categories in an unsupervised manner. This provides the foundation for addressing challenges posed by occlusion and for exploring part similarity across multiple categories. Extensive experiments demonstrate that our method robustly discovers meaningful parts across various categories and scenarios. The code is available at the project https://github.com/Jiahao-UTS/MPAE.
CoTKR: Chain-of-Thought Enhanced Knowledge Rewriting for Complex Knowledge Graph Question Answering
Sep 29, 2024



Recent studies have explored the use of Large Language Models (LLMs) with Retrieval Augmented Generation (RAG) for Knowledge Graph Question Answering (KGQA). They typically require rewriting retrieved subgraphs into natural language formats comprehensible to LLMs. However, when tackling complex questions, the knowledge rewritten by existing methods may include irrelevant information, omit crucial details, or fail to align with the question's semantics. To address them, we propose a novel rewriting method CoTKR, Chain-of-Thought Enhanced Knowledge Rewriting, for generating reasoning traces and corresponding knowledge in an interleaved manner, thereby mitigating the limitations of single-step knowledge rewriting. Additionally, to bridge the preference gap between the knowledge rewriter and the question answering (QA) model, we propose a training strategy PAQAF, Preference Alignment from Question Answering Feedback, for leveraging feedback from the QA model to further optimize the knowledge rewriter. We conduct experiments using various LLMs across several KGQA benchmarks. Experimental results demonstrate that, compared with previous knowledge rewriting methods, CoTKR generates the most beneficial knowledge representation for QA models, which significantly improves the performance of LLMs in KGQA.
MLDT: Multi-Level Decomposition for Complex Long-Horizon Robotic Task Planning with Open-Source Large Language Model
Apr 02, 2024



In the realm of data-driven AI technology, the application of open-source large language models (LLMs) in robotic task planning represents a significant milestone. Recent robotic task planning methods based on open-source LLMs typically leverage vast task planning datasets to enhance models' planning abilities. While these methods show promise, they struggle with complex long-horizon tasks, which require comprehending more context and generating longer action sequences. This paper addresses this limitation by proposing MLDT, theMulti-Level Decomposition Task planning method. This method innovatively decomposes tasks at the goal-level, task-level, and action-level to mitigate the challenge of complex long-horizon tasks. In order to enhance open-source LLMs' planning abilities, we introduce a goal-sensitive corpus generation method to create high-quality training data and conduct instruction tuning on the generated corpus. Since the complexity of the existing datasets is not high enough, we construct a more challenging dataset, LongTasks, to specifically evaluate planning ability on complex long-horizon tasks. We evaluate our method using various LLMs on four datasets in VirtualHome. Our results demonstrate a significant performance enhancement in robotic task planning, showcasing MLDT's effectiveness in overcoming the limitations of existing methods based on open-source LLMs as well as its practicality in complex, real-world scenarios.
Benchmarking Large Language Models in Complex Question Answering Attribution using Knowledge Graphs
Jan 26, 2024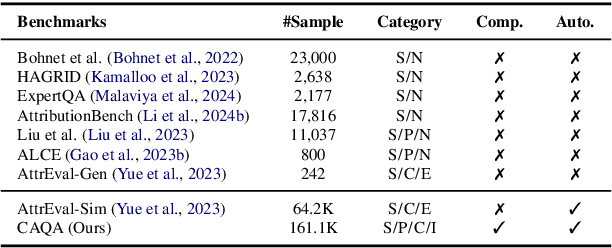
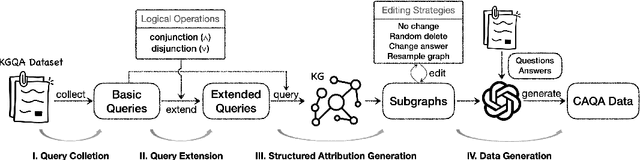

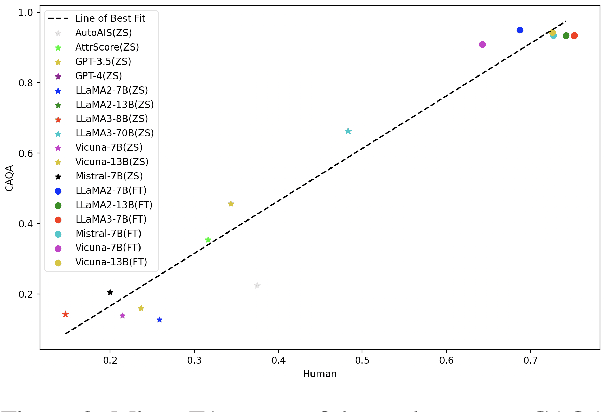
The attribution of question answering is to provide citations for supporting generated statements, and has attracted wide research attention. The current methods for automatically evaluating the attribution, which are often based on Large Language Models (LLMs), are still inadequate, particularly in recognizing subtle differences between attributions, and complex relationships between citations and statements. To compare these attribution evaluation methods and develop new ones, we introduce a set of fine-grained categories (i.e., supportive, insufficient, contradictory and irrelevant) for measuring the attribution, and develop a Complex Attributed Question Answering (CAQA) benchmark by leveraging knowledge graphs (KGs) for automatically generating attributions of different categories to question-answer pairs. Our analysis reveals that existing evaluators perform poorly under fine-grained attribution settings and exhibit weaknesses in complex citation-statement reasoning. Our CAQA benchmark, validated with human annotations, emerges as a promising tool for selecting and developing LLM attribution evaluators.
Retrieve-Rewrite-Answer: A KG-to-Text Enhanced LLMs Framework for Knowledge Graph Question Answering
Sep 21, 2023Despite their competitive performance on knowledge-intensive tasks, large language models (LLMs) still have limitations in memorizing all world knowledge especially long tail knowledge. In this paper, we study the KG-augmented language model approach for solving the knowledge graph question answering (KGQA) task that requires rich world knowledge. Existing work has shown that retrieving KG knowledge to enhance LLMs prompting can significantly improve LLMs performance in KGQA. However, their approaches lack a well-formed verbalization of KG knowledge, i.e., they ignore the gap between KG representations and textual representations. To this end, we propose an answer-sensitive KG-to-Text approach that can transform KG knowledge into well-textualized statements most informative for KGQA. Based on this approach, we propose a KG-to-Text enhanced LLMs framework for solving the KGQA task. Experiments on several KGQA benchmarks show that the proposed KG-to-Text augmented LLMs approach outperforms previous KG-augmented LLMs approaches regarding answer accuracy and usefulness of knowledge statements.
Uncertainty-Aware Unlikelihood Learning Improves Generative Aspect Sentiment Quad Prediction
Jun 03, 2023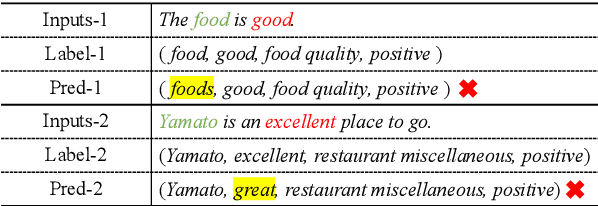
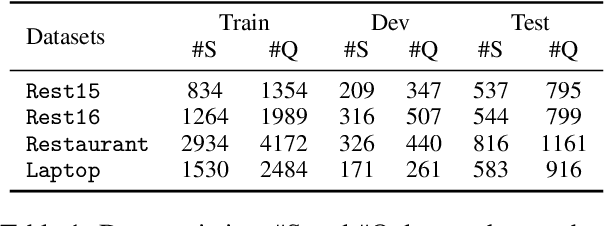
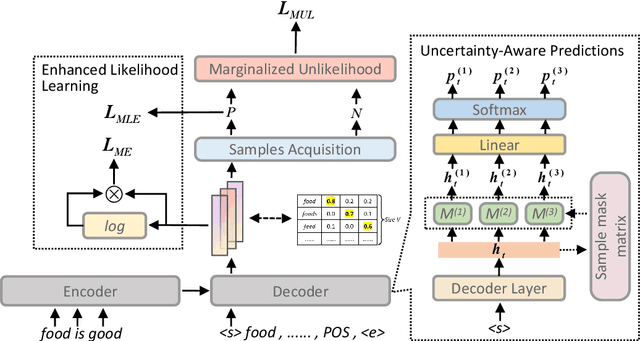
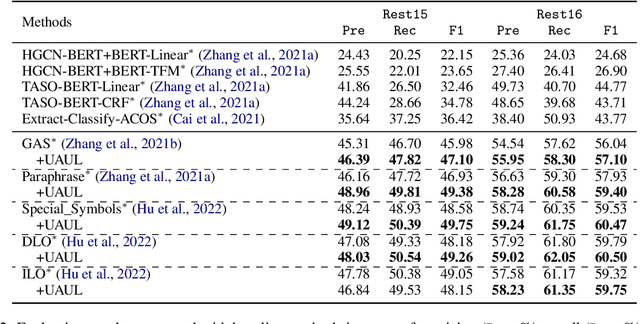
Recently, aspect sentiment quad prediction has received widespread attention in the field of aspect-based sentiment analysis. Existing studies extract quadruplets via pre-trained generative language models to paraphrase the original sentence into a templated target sequence. However, previous works only focus on what to generate but ignore what not to generate. We argue that considering the negative samples also leads to potential benefits. In this work, we propose a template-agnostic method to control the token-level generation, which boosts original learning and reduces mistakes simultaneously. Specifically, we introduce Monte Carlo dropout to understand the built-in uncertainty of pre-trained language models, acquiring the noises and errors. We further propose marginalized unlikelihood learning to suppress the uncertainty-aware mistake tokens. Finally, we introduce minimization entropy to balance the effects of marginalized unlikelihood learning. Extensive experiments on four public datasets demonstrate the effectiveness of our approach on various generation templates.
From Alignment to Entailment: A Unified Textual Entailment Framework for Entity Alignment
May 19, 2023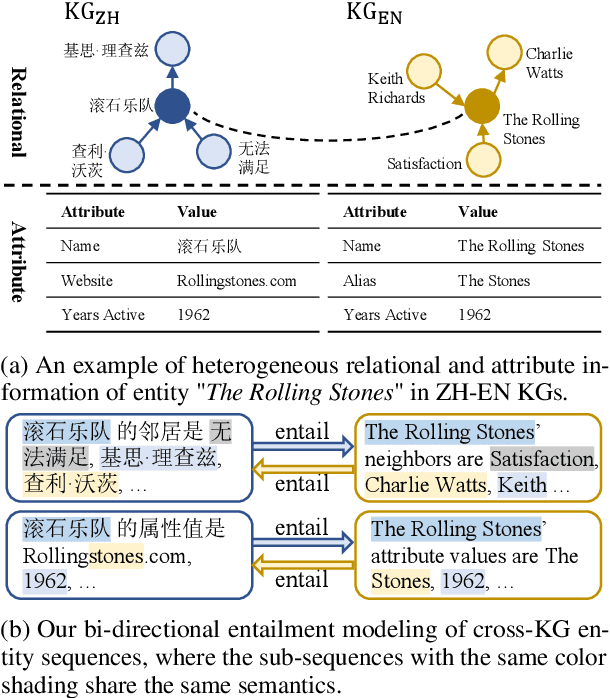
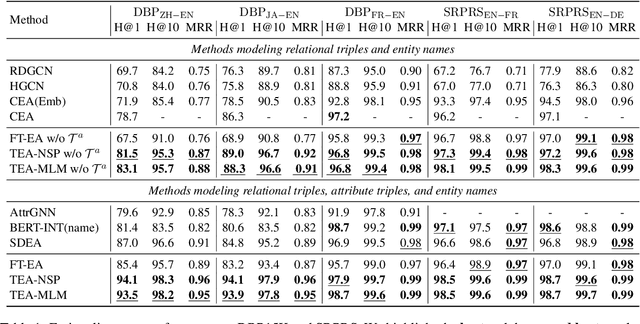
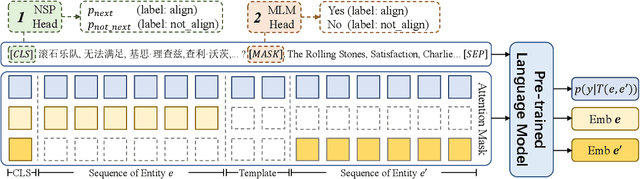
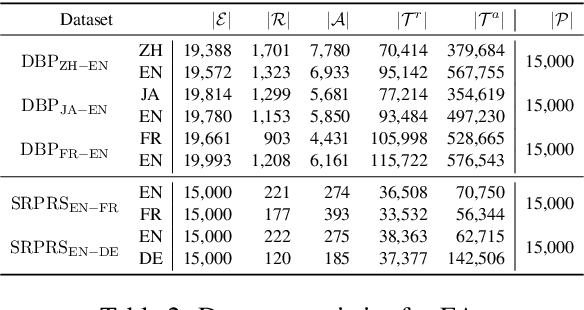
Entity Alignment (EA) aims to find the equivalent entities between two Knowledge Graphs (KGs). Existing methods usually encode the triples of entities as embeddings and learn to align the embeddings, which prevents the direct interaction between the original information of the cross-KG entities. Moreover, they encode the relational triples and attribute triples of an entity in heterogeneous embedding spaces, which prevents them from helping each other. In this paper, we transform both triples into unified textual sequences, and model the EA task as a bi-directional textual entailment task between the sequences of cross-KG entities. Specifically, we feed the sequences of two entities simultaneously into a pre-trained language model (PLM) and propose two kinds of PLM-based entity aligners that model the entailment probability between sequences as the similarity between entities. Our approach captures the unified correlation pattern of two kinds of information between entities, and explicitly models the fine-grained interaction between original entity information. The experiments on five cross-lingual EA datasets show that our approach outperforms the state-of-the-art EA methods and enables the mutual enhancement of the heterogeneous information. Codes are available at https://github.com/OreOZhao/TEA.
An Empirical Study of Pre-trained Language Models in Simple Knowledge Graph Question Answering
Mar 18, 2023Large-scale pre-trained language models (PLMs) such as BERT have recently achieved great success and become a milestone in natural language processing (NLP). It is now the consensus of the NLP community to adopt PLMs as the backbone for downstream tasks. In recent works on knowledge graph question answering (KGQA), BERT or its variants have become necessary in their KGQA models. However, there is still a lack of comprehensive research and comparison of the performance of different PLMs in KGQA. To this end, we summarize two basic KGQA frameworks based on PLMs without additional neural network modules to compare the performance of nine PLMs in terms of accuracy and efficiency. In addition, we present three benchmarks for larger-scale KGs based on the popular SimpleQuestions benchmark to investigate the scalability of PLMs. We carefully analyze the results of all PLMs-based KGQA basic frameworks on these benchmarks and two other popular datasets, WebQuestionSP and FreebaseQA, and find that knowledge distillation techniques and knowledge enhancement methods in PLMs are promising for KGQA. Furthermore, we test ChatGPT, which has drawn a great deal of attention in the NLP community, demonstrating its impressive capabilities and limitations in zero-shot KGQA. We have released the code and benchmarks to promote the use of PLMs on KGQA.
Improving Aspect Sentiment Quad Prediction via Template-Order Data Augmentation
Oct 19, 2022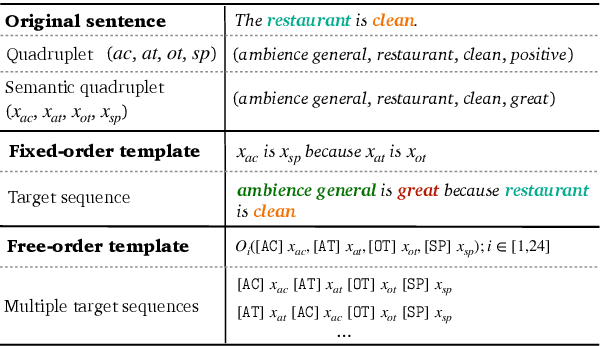
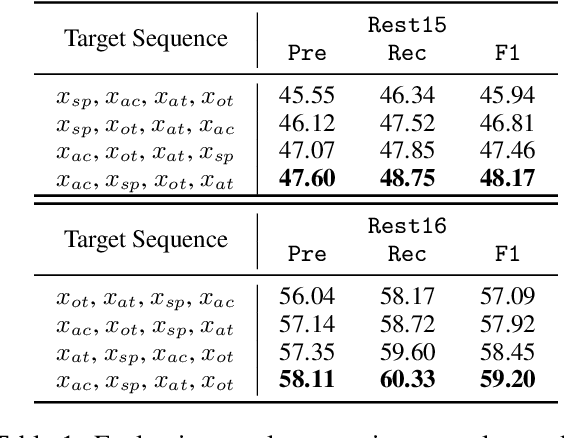
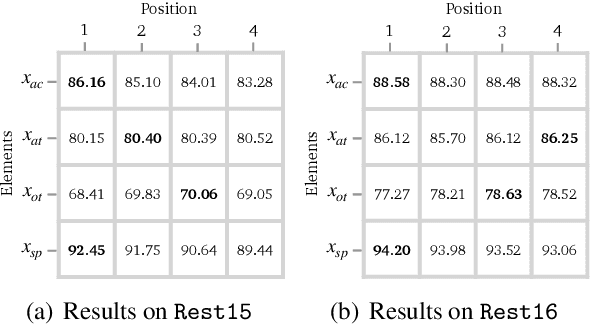
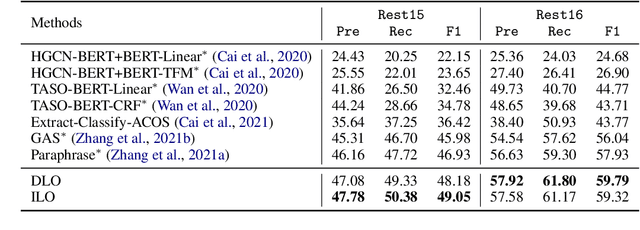
Recently, aspect sentiment quad prediction (ASQP) has become a popular task in the field of aspect-level sentiment analysis. Previous work utilizes a predefined template to paraphrase the original sentence into a structure target sequence, which can be easily decoded as quadruplets of the form (aspect category, aspect term, opinion term, sentiment polarity). The template involves the four elements in a fixed order. However, we observe that this solution contradicts with the order-free property of the ASQP task, since there is no need to fix the template order as long as the quadruplet is extracted correctly. Inspired by the observation, we study the effects of template orders and find that some orders help the generative model achieve better performance. It is hypothesized that different orders provide various views of the quadruplet. Therefore, we propose a simple but effective method to identify the most proper orders, and further combine multiple proper templates as data augmentation to improve the ASQP task. Specifically, we use the pre-trained language model to select the orders with minimal entropy. By fine-tuning the pre-trained language model with these template orders, our approach improves the performance of quad prediction, and outperforms state-of-the-art methods significantly in low-resource settings.
MoSE: Modality Split and Ensemble for Multimodal Knowledge Graph Completion
Oct 17, 2022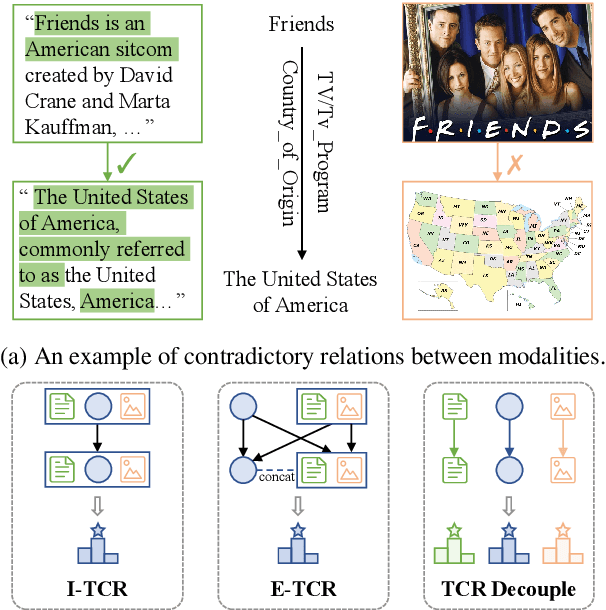
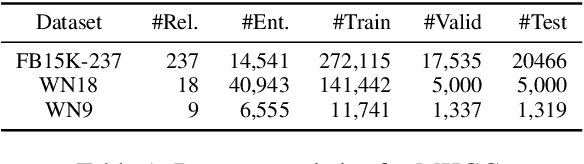
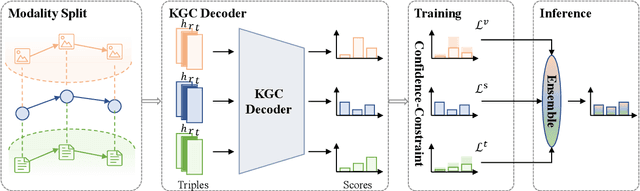
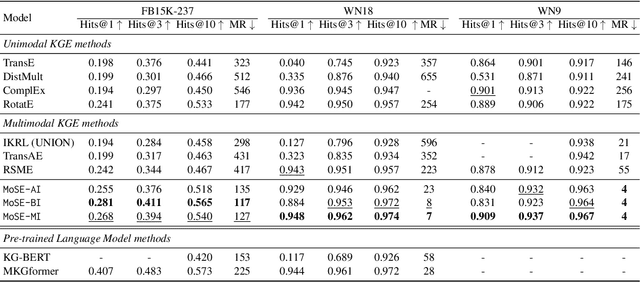
Multimodal knowledge graph completion (MKGC) aims to predict missing entities in MKGs. Previous works usually share relation representation across modalities. This results in mutual interference between modalities during training, since for a pair of entities, the relation from one modality probably contradicts that from another modality. Furthermore, making a unified prediction based on the shared relation representation treats the input in different modalities equally, while their importance to the MKGC task should be different. In this paper, we propose MoSE, a Modality Split representation learning and Ensemble inference framework for MKGC. Specifically, in the training phase, we learn modality-split relation embeddings for each modality instead of a single modality-shared one, which alleviates the modality interference. Based on these embeddings, in the inference phase, we first make modality-split predictions and then exploit various ensemble methods to combine the predictions with different weights, which models the modality importance dynamically. Experimental results on three KG datasets show that MoSE outperforms state-of-the-art MKGC methods. Codes are available at https://github.com/OreOZhao/MoSE4MKGC.