 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoyAI-LLM Flash: Advancing Mid-Scale LLMs with Token Efficiency
Apr 03, 2026We introduce JoyAI-LLM Flash, an efficient Mixture-of-Experts (MoE) language model designed to redefine the trade-off between strong performance and token efficiency in the sub-50B parameter regime. JoyAI-LLM Flash is pretrained on a massive corpus of 20 trillion tokens and further optimized through a rigorous post-training pipeline, including supervised fine-tuning (SFT), Direct Preference Optimization (DPO), and large-scale reinforcement learning (RL) across diverse environments. To improve token efficiency, JoyAI-LLM Flash strategically balances \emph{thinking} and \emph{non-thinking} cognitive modes and introduces FiberPO, a novel RL algorithm inspired by fibration theory that decomposes trust-region maintenance into global and local components, providing unified multi-scale stability control for LLM policy optimization. To enhance architectural sparsity, the model comprises 48B total parameters while activating only 2.7B parameters per forward pass, achieving a substantially higher sparsity ratio than contemporary industry leading models of comparable scale. To further improve inference throughput, we adopt a joint training-inference co-design that incorporates dense Multi-Token Prediction (MTP) and Quantization-Aware Training (QAT). We release the checkpoints for both JoyAI-LLM-48B-A3B Base and its post-trained variants on Hugging Face to support the open-source community.
BvSP: Broad-view Soft Prompting for Few-Shot Aspect Sentiment Quad Prediction
Jun 11, 2024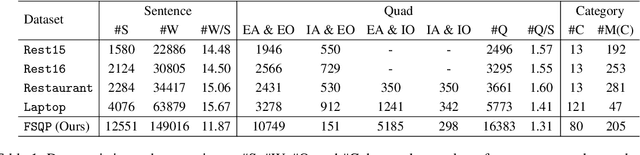


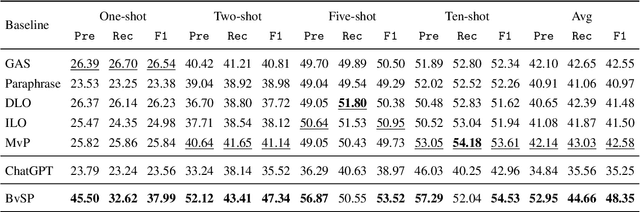
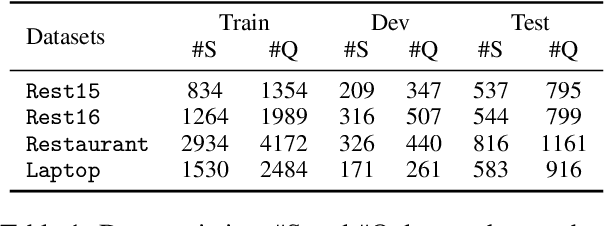
Aspect sentiment quad prediction (ASQP) aims to predict four aspect-based elements, including aspect term, opinion term, aspect category, and sentiment polarity. In practice, unseen aspects, due to distinct data distribution, impose many challenges for a trained neural model. Motivated by this, this work formulates ASQP into the few-shot scenario, which aims for fast adaptation in real applications. Therefore, we first construct a few-shot ASQP dataset (FSQP) that contains richer categories and is more balanced for the few-shot study. Moreover, recent methods extract quads through a generation paradigm, which involves converting the input sentence into a templated target sequence. However, they primarily focus on the utilization of a single template or the consideration of different template orders, thereby overlooking the correlations among various templates. To tackle this issue, we further propose a Broadview Soft Prompting (BvSP) method that aggregates multiple templates with a broader view by taking into account the correlation between the different templates. Specifically, BvSP uses the pre-trained language model to select the most relevant k templates with Jensen-Shannon divergence. BvSP further introduces soft prompts to guide the pre-trained language model using the selected templates. Then, we aggregate the results of multi-templates by voting mechanism. Empirical results demonstrate that BvSP significantly outperforms the stateof-the-art methods under four few-shot settings and other public datasets. Our code and dataset are available at https://github.com/byinhao/BvSP.
Coreference Graph Guidance for Mind-Map Generation
Dec 19, 2023Mind-map generation aims to process a document into a hierarchical structure to show its central idea and branches. Such a manner is more conducive to understanding the logic and semantics of the document than plain text. Recently, a state-of-the-art method encodes the sentences of a document sequentially and converts them to a relation graph via sequence-to-graph. Though this method is efficient to generate mind-maps in parallel, its mechanism focuses more on sequential features while hardly capturing structural information. Moreover, it's difficult to model long-range semantic relations. In this work, we propose a coreference-guided mind-map generation network (CMGN) to incorporate external structure knowledge. Specifically, we construct a coreference graph based on the coreference semantic relationship to introduce the graph structure information. Then we employ a coreference graph encoder to mine the potential governing relations between sentences. In order to exclude noise and better utilize the information of the coreference graph, we adopt a graph enhancement module in a contrastive learning manner. Experimental results demonstrate that our model outperforms all the existing methods. The case study further proves that our model can more accurately and concisely reveal the structure and semantics of a document. Code and data are available at https://github.com/Cyno2232/CMGN.
Uncertainty-Aware Unlikelihood Learning Improves Generative Aspect Sentiment Quad Prediction
Jun 03, 2023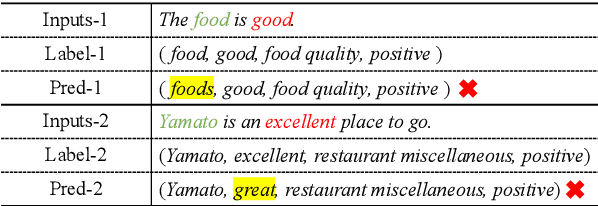
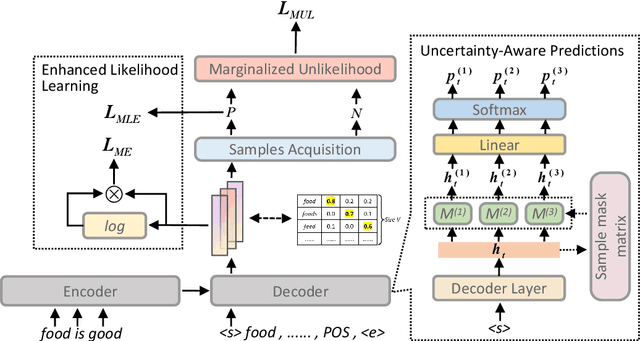
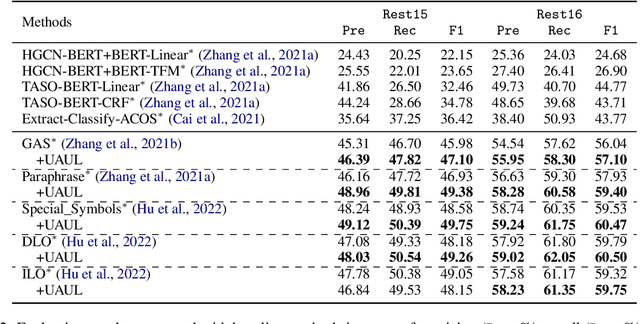
Recently, aspect sentiment quad prediction has received widespread attention in the field of aspect-based sentiment analysis. Existing studies extract quadruplets via pre-trained generative language models to paraphrase the original sentence into a templated target sequence. However, previous works only focus on what to generate but ignore what not to generate. We argue that considering the negative samples also leads to potential benefits. In this work, we propose a template-agnostic method to control the token-level generation, which boosts original learning and reduces mistakes simultaneously. Specifically, we introduce Monte Carlo dropout to understand the built-in uncertainty of pre-trained language models, acquiring the noises and errors. We further propose marginalized unlikelihood learning to suppress the uncertainty-aware mistake tokens. Finally, we introduce minimization entropy to balance the effects of marginalized unlikelihood learning. Extensive experiments on four public datasets demonstrate the effectiveness of our approach on various generation templates.
Improving Aspect Sentiment Quad Prediction via Template-Order Data Augmentation
Oct 19, 2022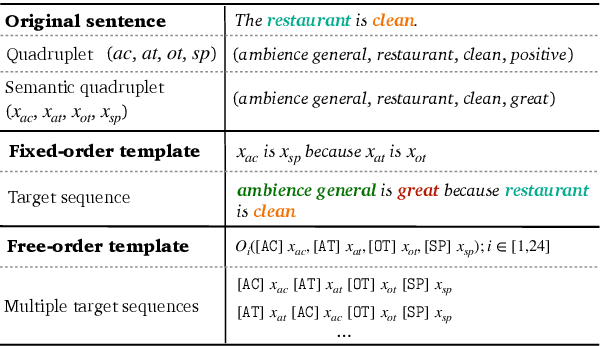
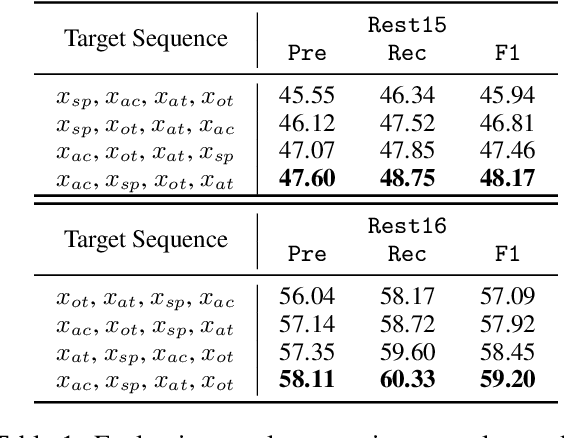
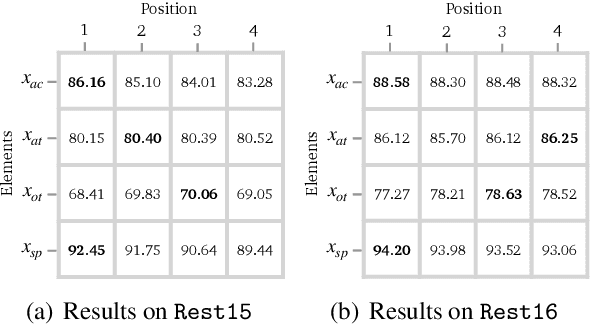
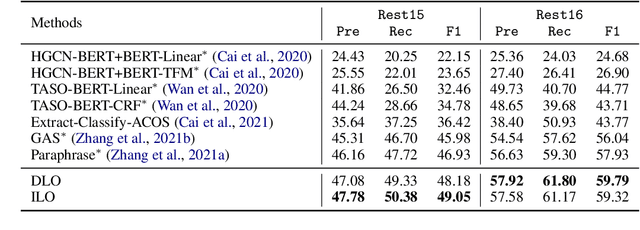
Recently, aspect sentiment quad prediction (ASQP) has become a popular task in the field of aspect-level sentiment analysis. Previous work utilizes a predefined template to paraphrase the original sentence into a structure target sequence, which can be easily decoded as quadruplets of the form (aspect category, aspect term, opinion term, sentiment polarity). The template involves the four elements in a fixed order. However, we observe that this solution contradicts with the order-free property of the ASQP task, since there is no need to fix the template order as long as the quadruplet is extracted correctly. Inspired by the observation, we study the effects of template orders and find that some orders help the generative model achieve better performance. It is hypothesized that different orders provide various views of the quadruplet. Therefore, we propose a simple but effective method to identify the most proper orders, and further combine multiple proper templates as data augmentation to improve the ASQP task. Specifically, we use the pre-trained language model to select the orders with minimal entropy. By fine-tuning the pre-trained language model with these template orders, our approach improves the performance of quad prediction, and outperforms state-of-the-art methods significantly in low-resource settings.
Classical Sequence Match is a Competitive Few-Shot One-Class Learner
Sep 14, 2022
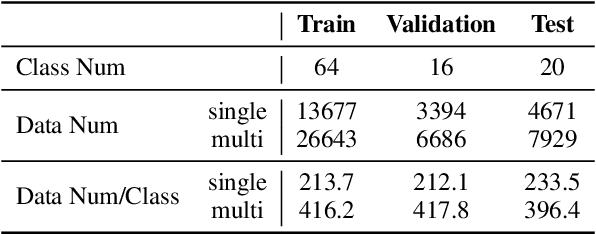
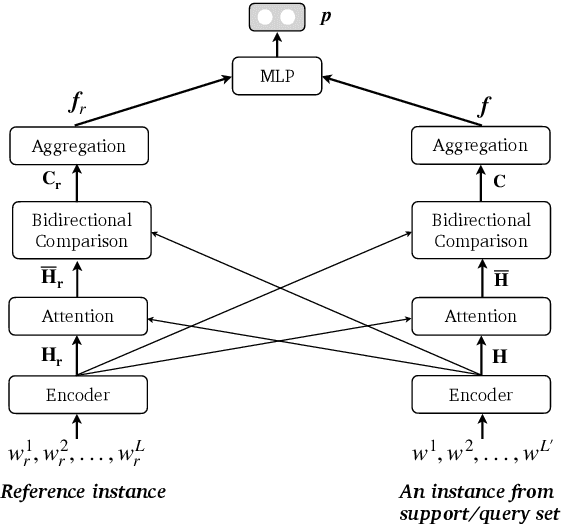
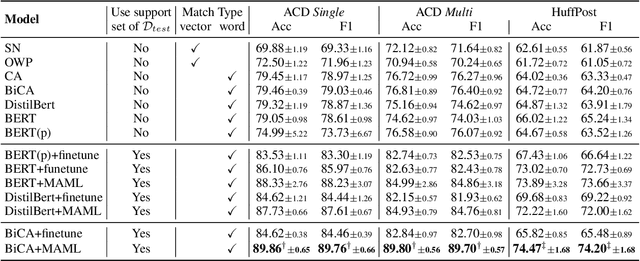
Nowadays, transformer-based models gradually become the default choice for artificial intelligence pioneers. The models also show superiority even in the few-shot scenarios. In this paper, we revisit the classical methods and propose a new few-shot alternative. Specifically, we investigate the few-shot one-class problem, which actually takes a known sample as a reference to detect whether an unknown instance belongs to the same class. This problem can be studied from the perspective of sequence match. It is shown that with meta-learning, the classical sequence match method, i.e. Compare-Aggregate, significantly outperforms transformer ones. The classical approach requires much less training cost. Furthermore, we perform an empirical comparison between two kinds of sequence match approaches under simple fine-tuning and meta-learning. Meta-learning causes the transformer models' features to have high-correlation dimensions. The reason is closely related to the number of layers and heads of transformer models. Experimental codes and data are available at https://github.com/hmt2014/FewOne