 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple but Effective Compound Geometric Operations for Temporal Knowledge Graph Completion
Aug 13, 2024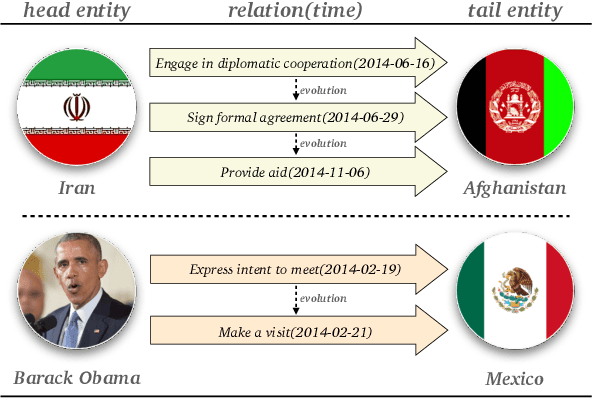
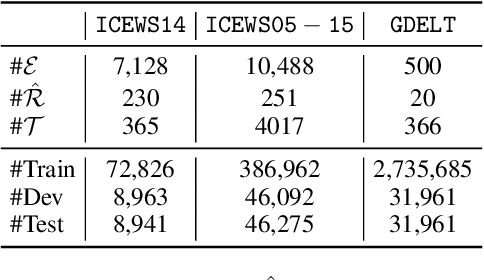
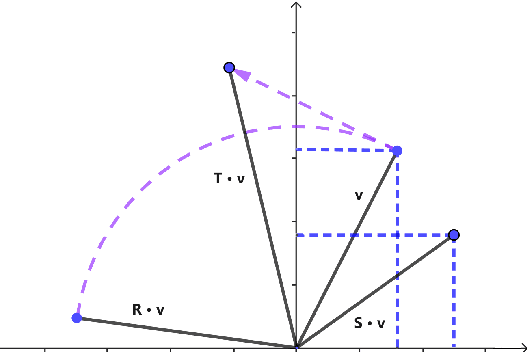
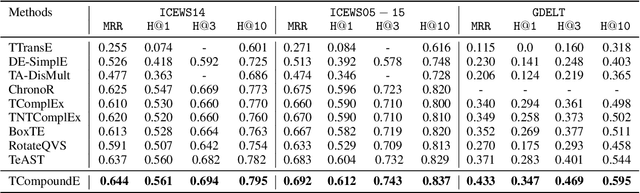
Temporal knowledge graph completion aims to infer the missing facts in temporal knowledge graphs. Current approaches usually embed factual knowledge into continuous vector space and apply geometric operations to learn potential patterns in temporal knowledge graphs. However, these methods only adopt a single operation, which may have limitations in capturing the complex temporal dynamics present in temporal knowledge graphs. Therefore, we propose a simple but effective method, i.e. TCompoundE, which is specially designed with two geometric operations, including time-specific and relation-specific operations. We provide mathematical proofs to demonstrate the ability of TCompoundE to encode various relation patterns. Experimental results show that our proposed model significantly outperforms existing temporal knowledge graph embedding models. Our code is available at https://github.com/nk-ruiying/TCompoundE.
BvSP: Broad-view Soft Prompting for Few-Shot Aspect Sentiment Quad Prediction
Jun 11, 2024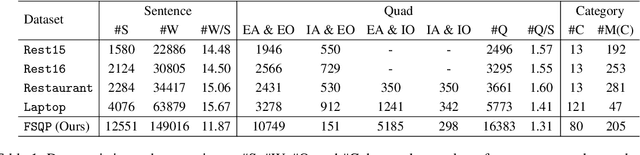


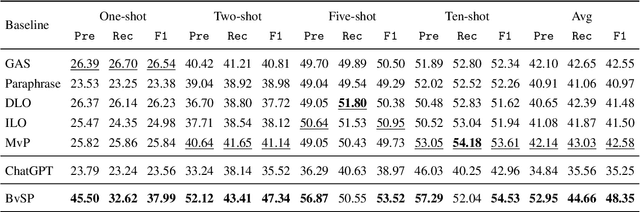
Aspect sentiment quad prediction (ASQP) aims to predict four aspect-based elements, including aspect term, opinion term, aspect category, and sentiment polarity. In practice, unseen aspects, due to distinct data distribution, impose many challenges for a trained neural model. Motivated by this, this work formulates ASQP into the few-shot scenario, which aims for fast adaptation in real applications. Therefore, we first construct a few-shot ASQP dataset (FSQP) that contains richer categories and is more balanced for the few-shot study. Moreover, recent methods extract quads through a generation paradigm, which involves converting the input sentence into a templated target sequence. However, they primarily focus on the utilization of a single template or the consideration of different template orders, thereby overlooking the correlations among various templates. To tackle this issue, we further propose a Broadview Soft Prompting (BvSP) method that aggregates multiple templates with a broader view by taking into account the correlation between the different templates. Specifically, BvSP uses the pre-trained language model to select the most relevant k templates with Jensen-Shannon divergence. BvSP further introduces soft prompts to guide the pre-trained language model using the selected templates. Then, we aggregate the results of multi-templates by voting mechanism. Empirical results demonstrate that BvSP significantly outperforms the stateof-the-art methods under four few-shot settings and other public datasets. Our code and dataset are available at https://github.com/byinhao/BvSP.