 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Few-Shot Medical Image Segmentation by SAM2: A Training-Free Framework with Augmentative Prompting and Dynamic Matching
Mar 05, 2025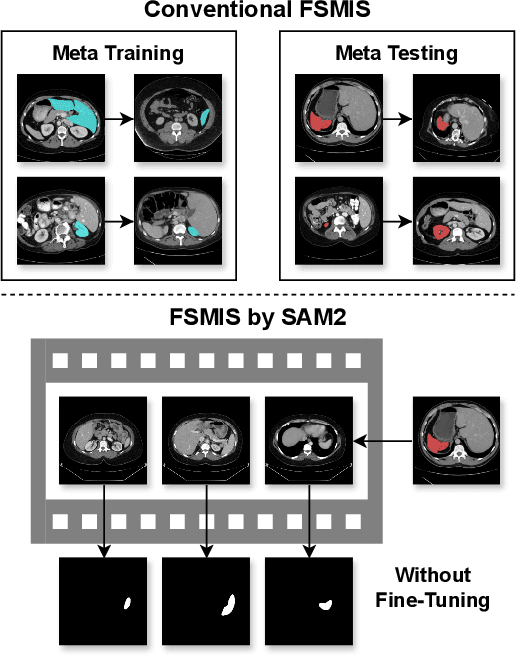
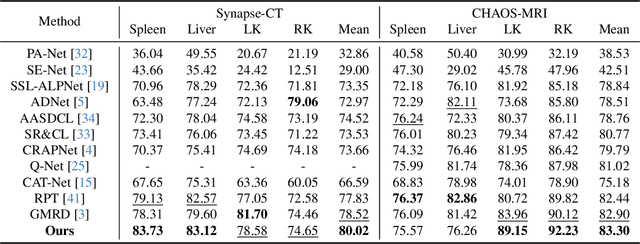
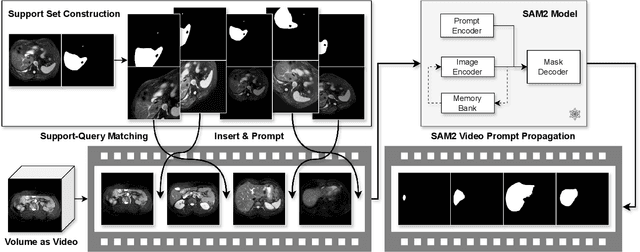
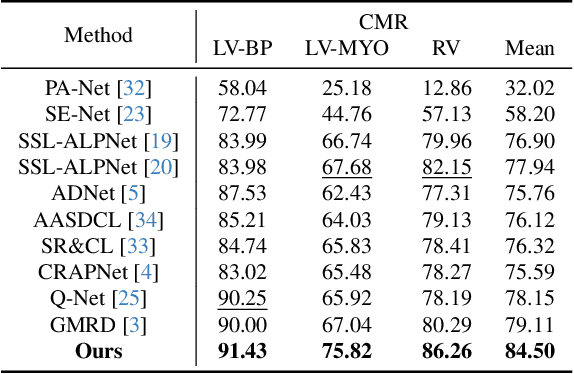
The reliance on large labeled datasets presents a significant challenge in medical image segmentation. Few-shot learning offers a potential solution, but existing methods often still require substantial training data. This paper proposes a novel approach that leverages the Segment Anything Model 2 (SAM2), a vision foundation model with strong video segmentation capabilities. We conceptualize 3D medical image volumes as video sequences, departing from the traditional slice-by-slice paradigm. Our core innovation is a support-query matching strategy: we perform extensive data augmentation on a single labeled support image and, for each frame in the query volume, algorithmically select the most analogous augmented support image. This selected image, along with its corresponding mask, is used as a mask prompt, driving SAM2's video segmentation. This approach entirely avoids model retraining or parameter updates. We demonstrate state-of-the-art performance on benchmark few-shot medical image segmentation datasets, achieving significant improvements in accuracy and annotation efficiency. This plug-and-play method offers a powerful and generalizable solution for 3D medical image segmentation.
Toward an Automated, Proactive Safety Warning System Development for Truck Mounted Attenuators in Mobile Work Zones
Dec 24, 2024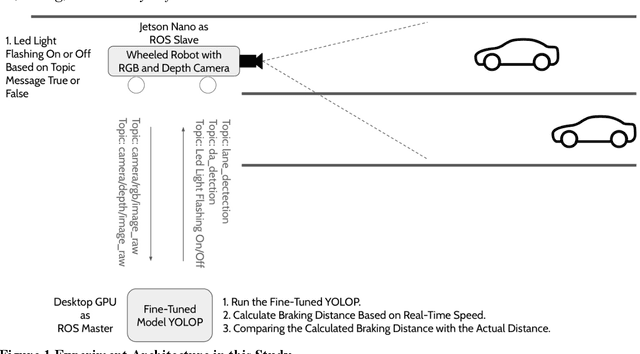
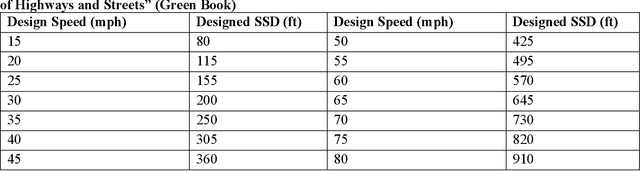
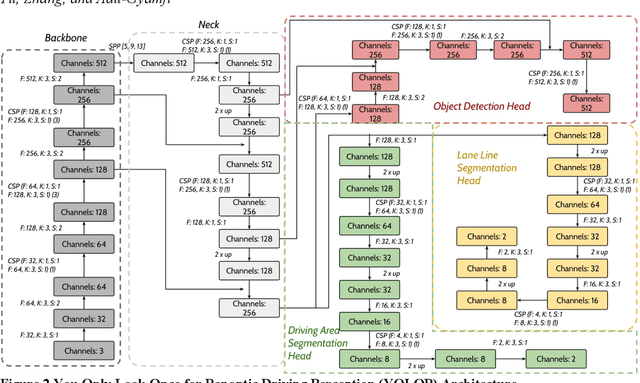
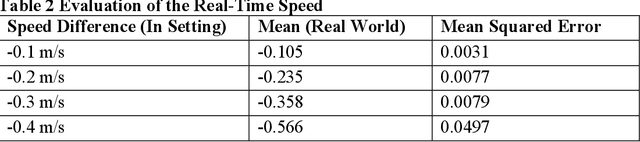
Even though Truck Mounted Attenuators (TMA)/Autonomous Truck Mounted Attenuators (ATMA) and traffic control devices are increasingly used in mobile work zones to enhance safety, work zone collisions remain a significant safety concern in the United States. In Missouri, there were 63 TMA-related crashes in 2023, a 27% increase compared to 2022. Currently, all the signs in the mobile work zones are passive safety measures, relying on drivers' recognition and attention. Some distracted drivers may ignore these signs and warnings, raising safety concerns. In this study, we proposed an additional proactive warning system that could be applied to the TMA/ATMA to improve overall safety. A feasible solution has been demonstrated by integrating a Panoptic Driving Perception algorithm into the Robot Operating System (ROS) and applying it to the TMA/ATMA systems. This enables us to alert vehicles on a collision course with the TMA. Our experimental setup, currently conducted in a laboratory environment with two ROS robots and a desktop GPU, demonstrates the system's capability to calculate real-time distance and speed and activate warning signals. Leveraging ROS's distributed computing capabilities allows for flexible system deployment and cost reduction. In future field tests, by combining the stopping sight distance (SSD) standards from the AASHTO Green Book, the system enables real-time monitoring of oncoming vehicles and provides additional proactive warnings to enhance the safety of mobile work zones.
Simple but Effective Compound Geometric Operations for Temporal Knowledge Graph Completion
Aug 13, 2024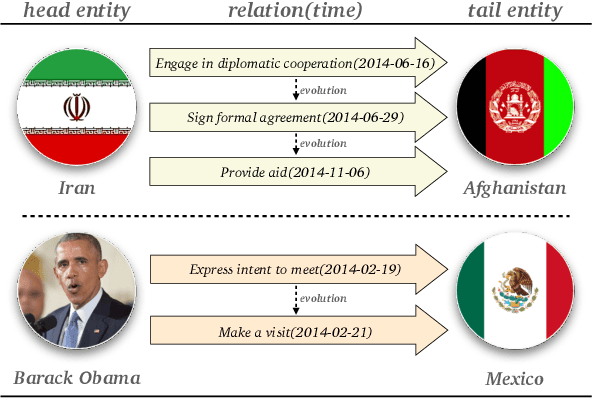
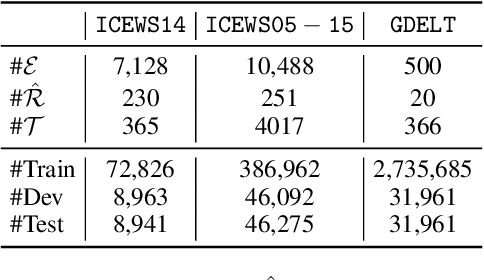
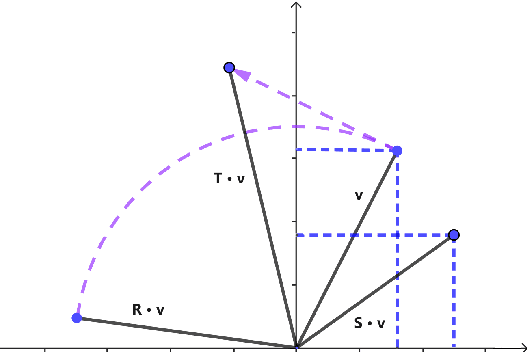
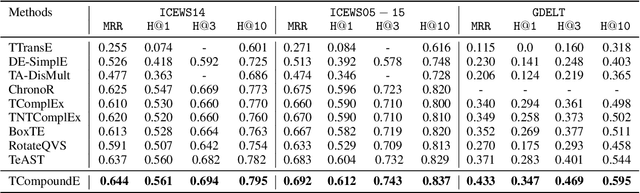
Temporal knowledge graph completion aims to infer the missing facts in temporal knowledge graphs. Current approaches usually embed factual knowledge into continuous vector space and apply geometric operations to learn potential patterns in temporal knowledge graphs. However, these methods only adopt a single operation, which may have limitations in capturing the complex temporal dynamics present in temporal knowledge graphs. Therefore, we propose a simple but effective method, i.e. TCompoundE, which is specially designed with two geometric operations, including time-specific and relation-specific operations. We provide mathematical proofs to demonstrate the ability of TCompoundE to encode various relation patterns. Experimental results show that our proposed model significantly outperforms existing temporal knowledge graph embedding models. Our code is available at https://github.com/nk-ruiying/TCompoundE.
Application of 2D Homography for High Resolution Traffic Data Collection using CCTV Cameras
Jan 14, 2024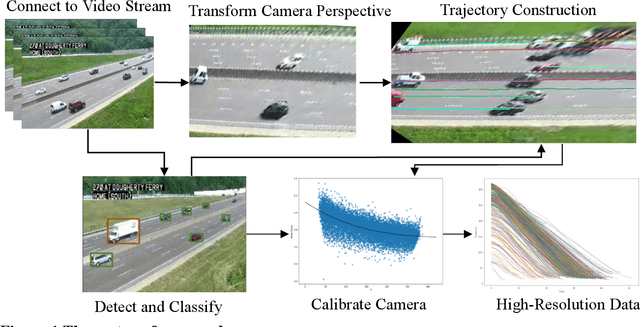
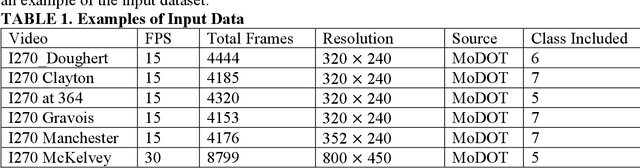
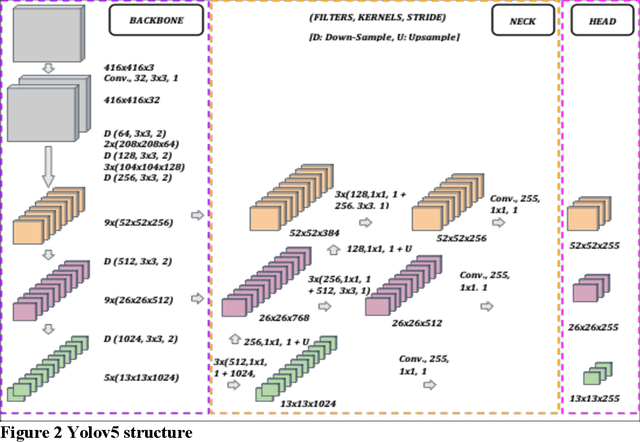
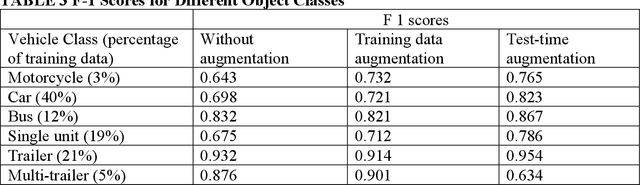
Traffic cameras remain the primary source data for surveillance activities such as congestion and incident monitoring. To date, State agencies continue to rely on manual effort to extract data from networked cameras due to limitations of the current automatic vision systems including requirements for complex camera calibration and inability to generate high resolution data. This study implements a three-stage video analytics framework for extracting high-resolution traffic data such vehicle counts, speed, and acceleration from infrastructure-mounted CCTV cameras. The key components of the framework include object recognition, perspective transformation, and vehicle trajectory reconstruction for traffic data collection. First, a state-of-the-art vehicle recognition model is implemented to detect and classify vehicles. Next, to correct for camera distortion and reduce partial occlusion, an algorithm inspired by two-point linear perspective is utilized to extracts the region of interest (ROI) automatically, while a 2D homography technique transforms the CCTV view to bird's-eye view (BEV). Cameras are calibrated with a two-layer matrix system to enable the extraction of speed and acceleration by converting image coordinates to real-world measurements. Individual vehicle trajectories are constructed and compared in BEV using two time-space-feature-based object trackers, namely Motpy and BYTETrack. The results of the current study showed about +/- 4.5% error rate for directional traffic counts, less than 10% MSE for speed bias between camera estimates in comparison to estimates from probe data sources. Extracting high-resolution data from traffic cameras has several implications, ranging from improvements in traffic management and identify dangerous driving behavior, high-risk areas for accidents, and other safety concerns, enabling proactive measures to reduce accidents and fatalities.
3D Object Detection and High-Resolution Traffic Parameters Extraction Using Low-Resolution LiDAR Data
Jan 13, 2024Traffic volume data collection is a crucial aspect of transportation engineering and urban planning, as it provides vital insights into traffic patterns, congestion, and infrastructure efficiency. Traditional manual methods of traffic data collection are both time-consuming and costly. However, the emergence of modern technologies, particularly Light Detection and Ranging (LiDAR), has revolutionized the process by enabling efficient and accurate data collection. Despite the benefits of using LiDAR for traffic data collection, previous studies have identified two major limitations that have impeded its widespread adoption. These are the need for multiple LiDAR systems to obtain complete point cloud information of objects of interest, as well as the labor-intensive process of annotating 3D bounding boxes for object detection tasks. In response to these challenges, the current study proposes an innovative framework that alleviates the need for multiple LiDAR systems and simplifies the laborious 3D annotation process. To achieve this goal, the study employed a single LiDAR system, that aims at reducing the data acquisition cost and addressed its accompanying limitation of missing point cloud information by developing a Point Cloud Completion (PCC) framework to fill in missing point cloud information using point density. Furthermore, we also used zero-shot learning techniques to detect vehicles and pedestrians, as well as proposed a unique framework for extracting low to high features from the object of interest, such as height, acceleration, and speed. Using the 2D bounding box detection and extracted height information, this study is able to generate 3D bounding boxes automatically without human intervention.
A Novel Full-Polarization SAR Images Ship Detector Based on the Scattering Mechanisms and the Wave Polarization Anisotropy
Dec 07, 2021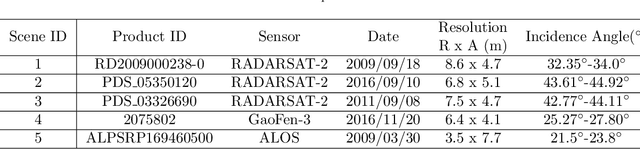
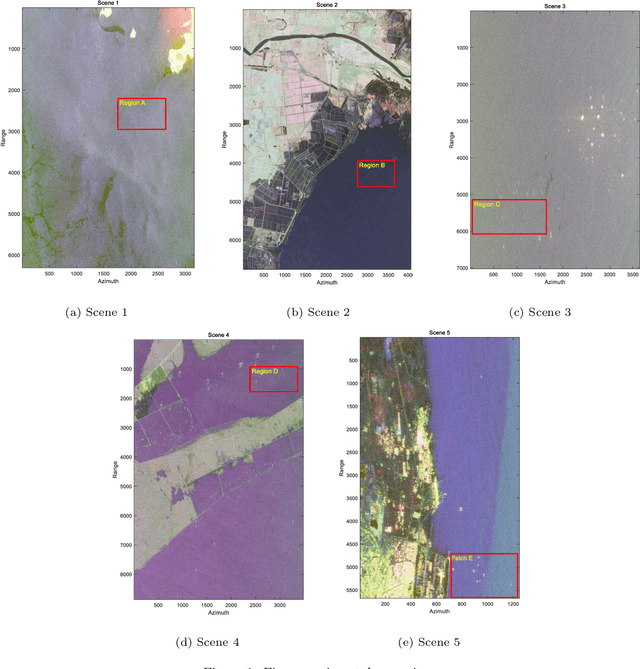
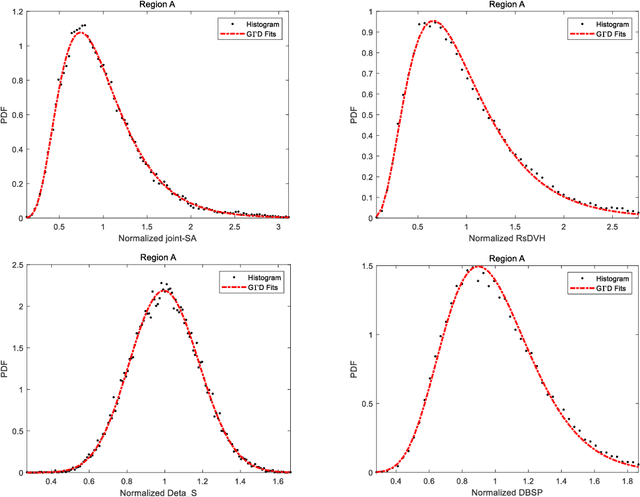
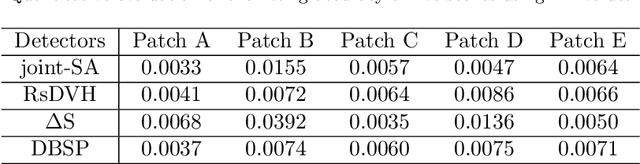
Synthetic aperture radar (SAR) is considered being a good option for earth observation with its unique advantages. In this paper, we proposed an adaptive ship detector using full-polarization SAR images. First, by thoroughly investigating the scattering characteristics between ships and their background, and the wave polarization anisotropy, a novel ship detector is proposed by jointing the two characteristics, named Scattering-Anisotropy joint (joint-SA). Based on the theoretical analysis, we showed that the joint-SA is an effective physical quantity to show the difference between the ship and its background, and thus joint-SA can be used for ship detection of full-polarization image data. Second, the generalized Gamma distribution was used to characterize the joint-SA statistics of sea clutter with a large range of homogeneity. As a result, an adaptive constant false alarm rate (CFAR) method was implemented based on the joint-SA. Finally, RADARSAT-2 and GF-3 data in C-band and ALOS data in L-band are used for verification. We tested on five datasets, and the experimental results verify the correctness and superiority of the constant false alarm rate (CFAR) method based on the joint-SA. In addition, the experimental results also showed that the signal-clutter ratio (SCR) of the proposed ship detector joint-SA (33.17 dB, 35.98 dB, 57.25 dB) is better than that of DBSP (8.92 dB, 3.43 dB, 25.40 dB) and RsDVH (17.28 dB, 11.17 dB, 54.55 dB). More importantly, the proposed detector joint-SA has higher detection accuracy and a lower false alarm rate.
Efficient Transformer for Single Image Super-Resolution
Aug 25, 2021



Single image super-resolution task has witnessed great strides with the development of deep learning. However, most existing studies focus on building a more complex neural network with a massive number of layers, bringing heavy computational cost and memory storage. Recently, as Transformer yields brilliant results in NLP tasks, more and more researchers start to explore the application of Transformer in computer vision tasks. But with the heavy computational cost and high GPU memory occupation of the vision Transformer, the network can not be designed too deep. To address this problem, we propose a novel Efficient Super-Resolution Transformer (ESRT) for fast and accurate image super-resolution. ESRT is a hybrid Transformer where a CNN-based SR network is first designed in the front to extract deep features. Specifically, there are two backbones for formatting the ESRT: lightweight CNN backbone (LCB) and lightweight Transformer backbone (LTB). Among them, LCB is a lightweight SR network to extract deep SR features at a low computational cost by dynamically adjusting the size of the feature map. LTB is made up of an efficient Transformer (ET) with a small GPU memory occupation, which benefited from the novel efficient multi-head attention (EMHA). In EMHA, a feature split module (FSM) is proposed to split the long sequence into sub-segments and then these sub-segments are applied by attention operation. This module can significantly decrease the GPU memory occupation. Extensive experiments show that our ESRT achieves competitive results. Compared with the original Transformer which occupies 16057M GPU memory, the proposed ET only occupies 4191M GPU memory with better performance.
Context-Adaptive Document-Level Neural Machine Translation
Apr 16, 2021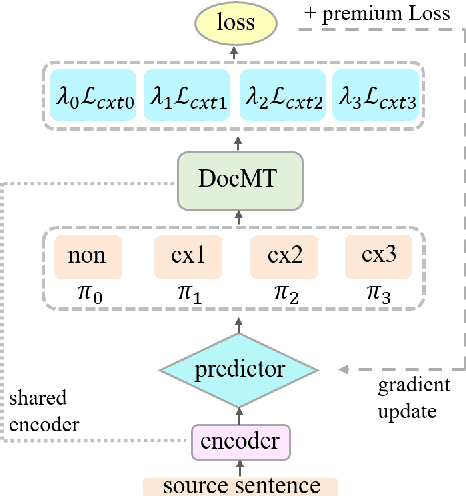
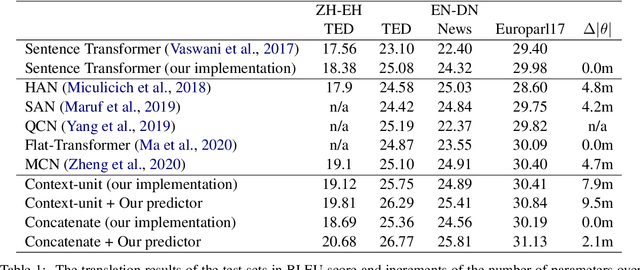
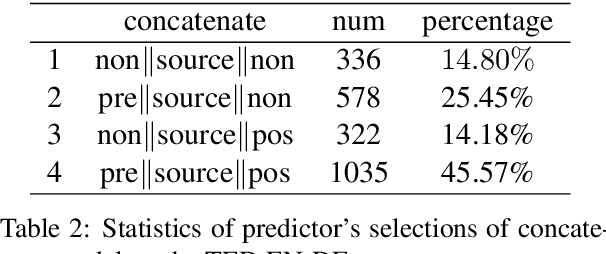
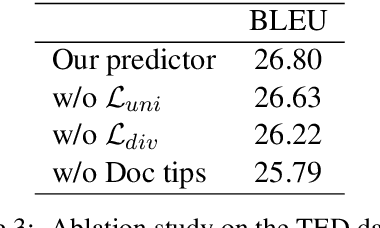
Most existing document-level neural machine translation (NMT) models leverage a fixed number of the previous or all global source sentences to handle the context-independent problem in standard NMT. However, the translating of each source sentence benefits from various sizes of context, and inappropriate context may harm the translation performance. In this work, we introduce a data-adaptive method that enables the model to adopt the necessary and useful context. Specifically, we introduce a light predictor into two document-level translation models to select the explicit context. Experiments demonstrate the proposed approach can significantly improve the performance over the previous methods with a gain up to 1.99 BLEU points.
Towards Variable-Length Textual Adversarial Attacks
Apr 16, 2021



Adversarial attacks have shown the vulnerability of machine learning models, however, it is non-trivial to conduct textual adversarial attacks on natural language processing tasks due to the discreteness of data. Most previous approaches conduct attacks with the atomic \textit{replacement} operation, which usually leads to fixed-length adversarial examples and therefore limits the exploration on the decision space. In this paper, we propose variable-length textual adversarial attacks~(VL-Attack) and integrate three atomic operations, namely \textit{insertion}, \textit{deletion} and \textit{replacement}, into a unified framework, by introducing and manipulating a special \textit{blank} token while attacking. In this way, our approach is able to more comprehensively find adversarial examples around the decision boundary and effectively conduct adversarial attacks. Specifically, our method drops the accuracy of IMDB classification by $96\%$ with only editing $1.3\%$ tokens while attacking a pre-trained BERT model. In addition, fine-tuning the victim model with generated adversarial samples can improve the robustness of the model without hurting the performance, especially for length-sensitive models. On the task of non-autoregressive machine translation, our method can achieve $33.18$ BLEU score on IWSLT14 German-English translation, achieving an improvement of $1.47$ over the baseline model.