 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Few-Shot Medical Image Segmentation by SAM2: A Training-Free Framework with Augmentative Prompting and Dynamic Matching
Mar 05, 2025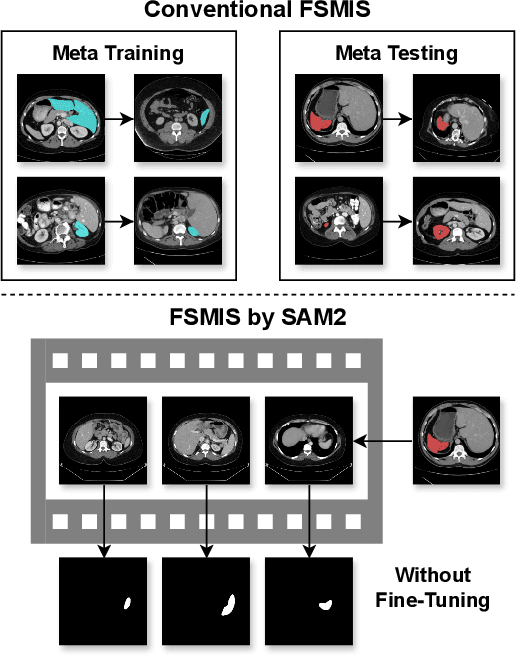
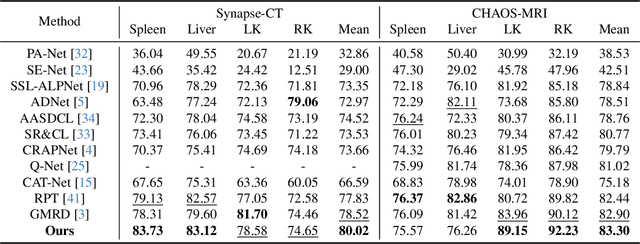
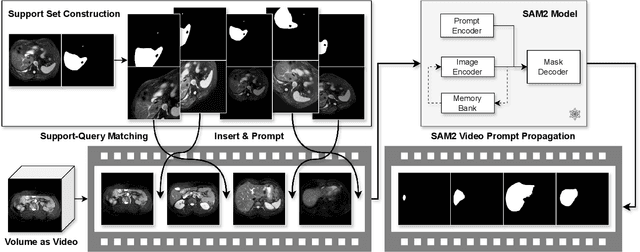
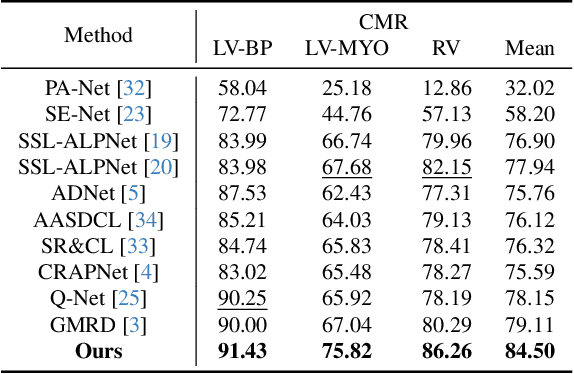
The reliance on large labeled datasets presents a significant challenge in medical image segmentation. Few-shot learning offers a potential solution, but existing methods often still require substantial training data. This paper proposes a novel approach that leverages the Segment Anything Model 2 (SAM2), a vision foundation model with strong video segmentation capabilities. We conceptualize 3D medical image volumes as video sequences, departing from the traditional slice-by-slice paradigm. Our core innovation is a support-query matching strategy: we perform extensive data augmentation on a single labeled support image and, for each frame in the query volume, algorithmically select the most analogous augmented support image. This selected image, along with its corresponding mask, is used as a mask prompt, driving SAM2's video segmentation. This approach entirely avoids model retraining or parameter updates. We demonstrate state-of-the-art performance on benchmark few-shot medical image segmentation datasets, achieving significant improvements in accuracy and annotation efficiency. This plug-and-play method offers a powerful and generalizable solution for 3D medical image segmentation.
Dataset Distillation via Knowledge Distillation: Towards Efficient Self-Supervised Pre-Training of Deep Networks
Oct 03, 2024



Dataset distillation (DD) generates small synthetic datasets that can efficiently train deep networks with a limited amount of memory and compute. Despite the success of DD methods for supervised learning, DD for self-supervised pre-training of deep models has remained unaddressed. Pre-training on unlabeled data is crucial for efficiently generalizing to downstream tasks with limited labeled data. In this work, we propose the first effective DD method for SSL pre-training. First, we show, theoretically and empirically, that naive application of supervised DD methods to SSL fails, due to the high variance of the SSL gradient. Then, we address this issue by relying on insights from knowledge distillation (KD) literature. Specifically, we train a small student model to match the representations of a larger teacher model trained with SSL. Then, we generate a small synthetic dataset by matching the training trajectories of the student models. As the KD objective has considerably lower variance than SSL, our approach can generate synthetic datasets that can successfully pre-train high-quality encoders. Through extensive experiments, we show that our distilled sets lead to up to 13% higher accuracy than prior work, on a variety of downstream tasks, in the presence of limited labeled data.
Investigating the Benefits of Projection Head for Representation Learning
Mar 18, 2024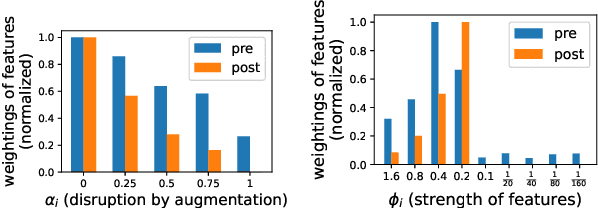
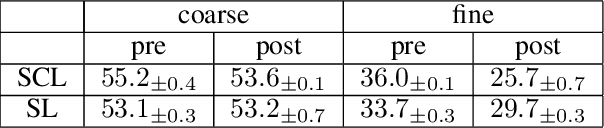
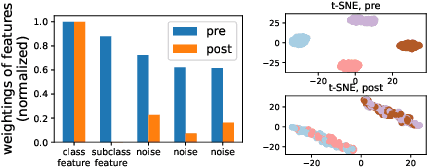
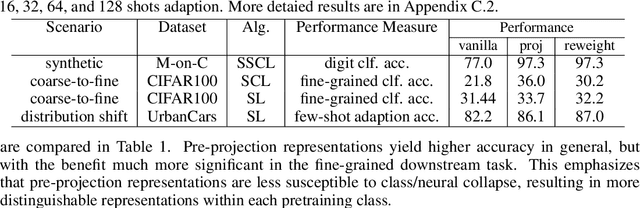
An effective technique for obtaining high-quality representations is adding a projection head on top of the encoder during training, then discarding it and using the pre-projection representations. Despite its proven practical effectiveness, the reason behind the success of this technique is poorly understood. The pre-projection representations are not directly optimized by the loss function, raising the question: what makes them better? In this work, we provide a rigorous theoretical answer to this question. We start by examining linear models trained with self-supervised contrastive loss. We reveal that the implicit bias of training algorithms leads to layer-wise progressive feature weighting, where features become increasingly unequal as we go deeper into the layers. Consequently, lower layers tend to have more normalized and less specialized representations. We theoretically characterize scenarios where such representations are more beneficial, highlighting the intricate interplay between data augmentation and input features. Additionally, we demonstrate that introducing non-linearity into the network allows lower layers to learn features that are completely absent in higher layers. Finally, we show how this mechanism improves the robustness in supervised contrastive learning and supervised learning. We empirically validate our results through various experiments on CIFAR-10/100, UrbanCars and shifted versions of ImageNet. We also introduce a potential alternative to projection head, which offers a more interpretable and controllable design.
Distribution-Aware Continual Test Time Adaptation for Semantic Segmentation
Sep 24, 2023



Since autonomous driving systems usually face dynamic and ever-changing environments, continual test-time adaptation (CTTA) has been proposed as a strategy for transferring deployed models to continually changing target domains. However, the pursuit of long-term adaptation often introduces catastrophic forgetting and error accumulation problems, which impede the practical implementation of CTTA in the real world. Recently, existing CTTA methods mainly focus on utilizing a majority of parameters to fit target domain knowledge through self-training. Unfortunately, these approaches often amplify the challenge of error accumulation due to noisy pseudo-labels, and pose practical limitations stemming from the heavy computational costs associated with entire model updates. In this paper, we propose a distribution-aware tuning (DAT) method to make the semantic segmentation CTTA efficient and practical in real-world applications. DAT adaptively selects and updates two small groups of trainable parameters based on data distribution during the continual adaptation process, including domain-specific parameters (DSP) and task-relevant parameters (TRP). Specifically, DSP exhibits sensitivity to outputs with substantial distribution shifts, effectively mitigating the problem of error accumulation. In contrast, TRP are allocated to positions that are responsive to outputs with minor distribution shifts, which are fine-tuned to avoid the catastrophic forgetting problem. In addition, since CTTA is a temporal task, we introduce the Parameter Accumulation Update (PAU) strategy to collect the updated DSP and TRP in target domain sequences. We conduct extensive experiments on two widely-used semantic segmentation CTTA benchmarks, achieving promising performance compared to previous state-of-the-art methods.