 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
DigiData: Training and Evaluating General-Purpose Mobile Control Agents
Nov 11, 2025AI agents capable of controlling user interfaces have the potential to transform human interaction with digital devices. To accelerate this transformation, two fundamental building blocks are essential: high-quality datasets that enable agents to achieve complex and human-relevant goals, and robust evaluation methods that allow researchers and practitioners to rapidly enhance agent performance. In this paper, we introduce DigiData, a large-scale, high-quality, diverse, multi-modal dataset designed for training mobile control agents. Unlike existing datasets, which derive goals from unstructured interactions, DigiData is meticulously constructed through comprehensive exploration of app features, resulting in greater diversity and higher goal complexity. Additionally, we present DigiData-Bench, a benchmark for evaluating mobile control agents on real-world complex tasks. We demonstrate that the commonly used step-accuracy metric falls short in reliably assessing mobile control agents and, to address this, we propose dynamic evaluation protocols and AI-powered evaluations as rigorous alternatives for agent assessment. Our contributions aim to significantly advance the development of mobile control agents, paving the way for more intuitive and effective human-device interactions.
Make the Most of Your Data: Changing the Training Data Distribution to Improve In-distribution Generalization Performance
Apr 27, 2024Can we modify the training data distribution to encourage the underlying optimization method toward finding solutions with superior generalization performance on in-distribution data? In this work, we approach this question for the first time by comparing the inductive bias of gradient descent (GD) with that of sharpness-aware minimization (SAM). By studying a two-layer CNN, we prove that SAM learns easy and difficult features more uniformly, particularly in early epochs. That is, SAM is less susceptible to simplicity bias compared to GD. Based on this observation, we propose USEFUL, an algorithm that clusters examples based on the network output early in training and upsamples examples with no easy features to alleviate the pitfalls of the simplicity bias. We show empirically that modifying the training data distribution in this way effectively improves the generalization performance on the original data distribution when training with (S)GD by mimicking the training dynamics of SAM. Notably, we demonstrate that our method can be combined with SAM and existing data augmentation strategies to achieve, to the best of our knowledge, state-of-the-art performance for training ResNet18 on CIFAR10, STL10, CINIC10, Tiny-ImageNet; ResNet34 on CIFAR100; and VGG19 and DenseNet121 on CIFAR10.
Investigating the Benefits of Projection Head for Representation Learning
Mar 18, 2024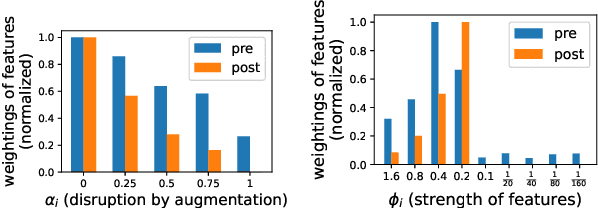
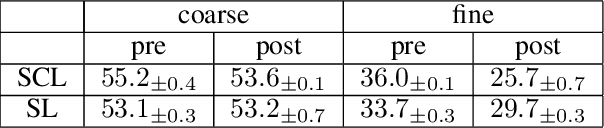
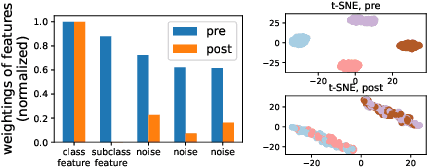
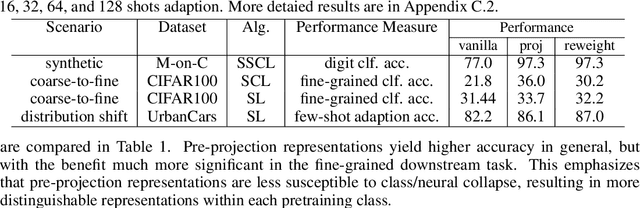
An effective technique for obtaining high-quality representations is adding a projection head on top of the encoder during training, then discarding it and using the pre-projection representations. Despite its proven practical effectiveness, the reason behind the success of this technique is poorly understood. The pre-projection representations are not directly optimized by the loss function, raising the question: what makes them better? In this work, we provide a rigorous theoretical answer to this question. We start by examining linear models trained with self-supervised contrastive loss. We reveal that the implicit bias of training algorithms leads to layer-wise progressive feature weighting, where features become increasingly unequal as we go deeper into the layers. Consequently, lower layers tend to have more normalized and less specialized representations. We theoretically characterize scenarios where such representations are more beneficial, highlighting the intricate interplay between data augmentation and input features. Additionally, we demonstrate that introducing non-linearity into the network allows lower layers to learn features that are completely absent in higher layers. Finally, we show how this mechanism improves the robustness in supervised contrastive learning and supervised learning. We empirically validate our results through various experiments on CIFAR-10/100, UrbanCars and shifted versions of ImageNet. We also introduce a potential alternative to projection head, which offers a more interpretable and controllable design.
Inference and Interference: The Role of Clipping, Pruning and Loss Landscapes in Differentially Private Stochastic Gradient Descent
Nov 12, 2023Differentially private stochastic gradient descent (DP-SGD) is known to have poorer training and test performance on large neural networks, compared to ordinary stochastic gradient descent (SGD). In this paper, we perform a detailed study and comparison of the two processes and unveil several new insights. By comparing the behavior of the two processes separately in early and late epochs, we find that while DP-SGD makes slower progress in early stages, it is the behavior in the later stages that determines the end result. This separate analysis of the clipping and noise addition steps of DP-SGD shows that while noise introduces errors to the process, gradient descent can recover from these errors when it is not clipped, and clipping appears to have a larger impact than noise. These effects are amplified in higher dimensions (large neural networks), where the loss basin occupies a lower dimensional space. We argue theoretically and using extensive experiments that magnitude pruning can be a suitable dimension reduction technique in this regard, and find that heavy pruning can improve the test accuracy of DPSGD.
Identifying Spurious Biases Early in Training through the Lens of Simplicity Bias
May 30, 2023Neural networks trained with (stochastic) gradient descent have an inductive bias towards learning simpler solutions. This makes them highly prone to learning simple spurious features that are highly correlated with a label instead of the predictive but more complex core features. In this work, we show that, interestingly, the simplicity bias of gradient descent can be leveraged to identify spurious correlations, early in training. First, we prove on a two-layer neural network, that groups of examples with high spurious correlation are separable based on the model's output, in the initial training iterations. We further show that if spurious features have a small enough noise-to-signal ratio, the network's output on the majority of examples in a class will be almost exclusively determined by the spurious features and will be nearly invariant to the core feature. Finally, we propose SPARE, which separates large groups with spurious correlations early in training, and utilizes importance sampling to alleviate the spurious correlation, by balancing the group sizes. We show that SPARE achieves up to 5.6% higher worst-group accuracy than state-of-the-art methods, while being up to 12x faster. We also show the applicability of SPARE to discover and mitigate spurious correlations in Restricted ImageNet.
Which Features are Learnt by Contrastive Learning? On the Role of Simplicity Bias in Class Collapse and Feature Suppression
May 29, 2023Contrastive learning (CL) has emerged as a powerful technique for representation learning, with or without label supervision. However, supervised CL is prone to collapsing representations of subclasses within a class by not capturing all their features, and unsupervised CL may suppress harder class-relevant features by focusing on learning easy class-irrelevant features; both significantly compromise representation quality. Yet, there is no theoretical understanding of \textit{class collapse} or \textit{feature suppression} at \textit{test} time. We provide the first unified theoretically rigorous framework to determine \textit{which} features are learnt by CL. Our analysis indicate that, perhaps surprisingly, bias of (stochastic) gradient descent towards finding simpler solutions is a key factor in collapsing subclass representations and suppressing harder class-relevant features. Moreover, we present increasing embedding dimensionality and improving the quality of data augmentations as two theoretically motivated solutions to {feature suppression}. We also provide the first theoretical explanation for why employing supervised and unsupervised CL together yields higher-quality representations, even when using commonly-used stochastic gradient methods.
Seeing is Believing: Brain-Inspired Modular Training for Mechanistic Interpretability
May 04, 2023



We introduce Brain-Inspired Modular Training (BIMT), a method for making neural networks more modular and interpretable. Inspired by brains, BIMT embeds neurons in a geometric space and augments the loss function with a cost proportional to the length of each neuron connection. We demonstrate that BIMT discovers useful modular neural networks for many simple tasks, revealing compositional structures in symbolic formulas, interpretable decision boundaries and features for classification, and mathematical structure in algorithmic datasets. The ability to directly see modules with the naked eye can complement current mechanistic interpretability strategies such as probes, interventions or staring at all weights.