 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond What Seems Necessary: Hidden Gains from Scaling Training-Time Reasoning Length under Outcome Supervision
Jan 31, 2026Training LLMs to think and reason for longer has become a key ingredient in building state-of-the-art models that can solve complex problems previously out of reach. Recent efforts pursue this in different ways, such as RL fine-tuning to elicit long CoT or scaling latent reasoning through architectural recurrence. This makes reasoning length an important scaling knob. In this work, we identify a novel phenomenon (both theoretically and experimentally): under outcome-only supervision, out-of-distribution (OOD) performance can continue improving as training-time reasoning length (e.g., the token budget in RL, or the loop count in looped Transformers) increases, even after in-distribution (ID) performance has saturated. This suggests that robustness may require a larger budget than ID validation alone would indicate. We provide theoretical explanations via two mechanisms: (i) self-iteration can induce a stronger inductive bias in the hypothesis class, reshaping ID-optimal solutions in ways that improve OOD generalization; and (ii) when shortcut solutions that work for ID samples but not for OOD samples persist in the hypothesis class, regularization can reduce the learned solution's reliance on these shortcuts as the number of self-iterations increases. We complement the theory with empirical evidence from two realizations of scaling training-time reasoning length: increasing the number of loops in looped Transformers on a synthetic task, and increasing token budgets during RL fine-tuning of LLMs on mathematical reasoning.
LoRA is All You Need for Safety Alignment of Reasoning LLMs
Jul 22, 2025


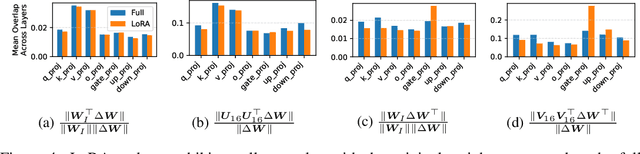
Reasoning LLMs have demonstrated remarkable breakthroughs in solving complex problems that were previously out of reach. To ensure LLMs do not assist with harmful requests, safety alignment fine-tuning is necessary in the post-training phase. However, safety alignment fine-tuning has recently been shown to significantly degrade reasoning abilities, a phenomenon known as the "Safety Tax". In this work, we show that using LoRA for SFT on refusal datasets effectively aligns the model for safety without harming its reasoning capabilities. This is because restricting the safety weight updates to a low-rank space minimizes the interference with the reasoning weights. Our extensive experiments across four benchmarks covering math, science, and coding show that this approach produces highly safe LLMs -- with safety levels comparable to full-model fine-tuning -- without compromising their reasoning abilities. Additionally, we observe that LoRA induces weight updates with smaller overlap with the initial weights compared to full-model fine-tuning. We also explore methods that further reduce such overlap -- via regularization or during weight merging -- and observe some improvement on certain tasks. We hope this result motivates designing approaches that yield more consistent improvements in the reasoning-safety trade-off.
Verify when Uncertain: Beyond Self-Consistency in Black Box Hallucination Detection
Feb 20, 2025



Large Language Models (LLMs) suffer from hallucination problems, which hinder their reliability in sensitive applications. In the black-box setting, several self-consistency-based techniques have been proposed for hallucination detection. We empirically study these techniques and show that they achieve performance close to that of a supervised (still black-box) oracle, suggesting little room for improvement within this paradigm. To address this limitation, we explore cross-model consistency checking between the target model and an additional verifier LLM. With this extra information, we observe improved oracle performance compared to purely self-consistency-based methods. We then propose a budget-friendly, two-stage detection algorithm that calls the verifier model only for a subset of cases. It dynamically switches between self-consistency and cross-consistency based on an uncertainty interval of the self-consistency classifier. We provide a geometric interpretation of consistency-based hallucination detection methods through the lens of kernel mean embeddings, offering deeper theoretical insights. Extensive experiments show that this approach maintains high detection performance while significantly reducing computational cost.
Investigating the Benefits of Projection Head for Representation Learning
Mar 18, 2024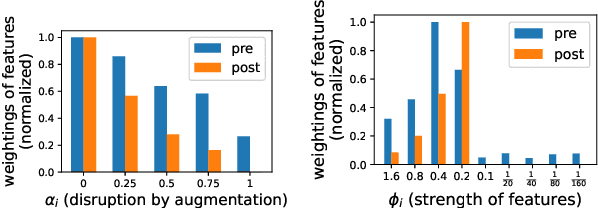
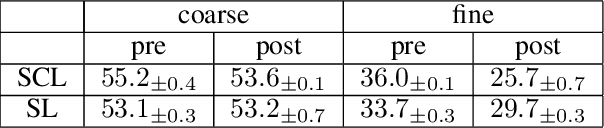
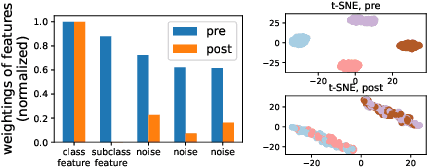
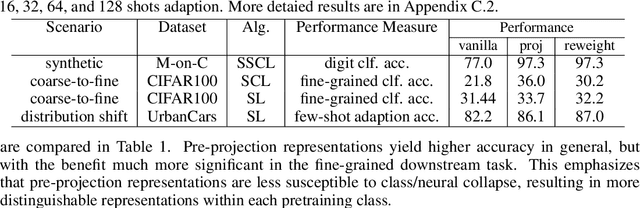
An effective technique for obtaining high-quality representations is adding a projection head on top of the encoder during training, then discarding it and using the pre-projection representations. Despite its proven practical effectiveness, the reason behind the success of this technique is poorly understood. The pre-projection representations are not directly optimized by the loss function, raising the question: what makes them better? In this work, we provide a rigorous theoretical answer to this question. We start by examining linear models trained with self-supervised contrastive loss. We reveal that the implicit bias of training algorithms leads to layer-wise progressive feature weighting, where features become increasingly unequal as we go deeper into the layers. Consequently, lower layers tend to have more normalized and less specialized representations. We theoretically characterize scenarios where such representations are more beneficial, highlighting the intricate interplay between data augmentation and input features. Additionally, we demonstrate that introducing non-linearity into the network allows lower layers to learn features that are completely absent in higher layers. Finally, we show how this mechanism improves the robustness in supervised contrastive learning and supervised learning. We empirically validate our results through various experiments on CIFAR-10/100, UrbanCars and shifted versions of ImageNet. We also introduce a potential alternative to projection head, which offers a more interpretable and controllable design.
Understanding the Robustness of Multi-modal Contrastive Learning to Distribution Shift
Oct 08, 2023



Recently, multimodal contrastive learning (MMCL) approaches, such as CLIP, have achieved a remarkable success in learning representations that are robust against distribution shift and generalize to new domains. Despite the empirical success, the mechanism behind learning such generalizable representations is not understood. In this work, we rigorously analyze this problem and uncover two mechanisms behind MMCL's robustness: \emph{intra-class contrasting}, which allows the model to learn features with a high variance, and \emph{inter-class feature sharing}, where annotated details in one class help learning other classes better. Both mechanisms prevent spurious features that are over-represented in the training data to overshadow the generalizable core features. This yields superior zero-shot classification accuracy under distribution shift. Furthermore, we theoretically demonstrate the benefits of using rich captions on robustness and explore the effect of annotating different types of details in the captions. We validate our theoretical findings through experiments, including a well-designed synthetic experiment and an experiment involving training CLIP on MS COCO and evaluating the model on variations of shifted ImageNet.
Towards Mitigating Spurious Correlations in the Wild: A Benchmark & a more Realistic Dataset
Jun 21, 2023Deep neural networks often exploit non-predictive features that are spuriously correlated with class labels, leading to poor performance on groups of examples without such features. Despite the growing body of recent works on remedying spurious correlations, the lack of a standardized benchmark hinders reproducible evaluation and comparison of the proposed solutions. To address this, we present SpuCo, a python package with modular implementations of state-of-the-art solutions enabling easy and reproducible evaluation of current methods. Using SpuCo, we demonstrate the limitations of existing datasets and evaluation schemes in validating the learning of predictive features over spurious ones. To overcome these limitations, we propose two new vision datasets: (1) SpuCoMNIST, a synthetic dataset that enables simulating the effect of real world data properties e.g. difficulty of learning spurious feature, as well as noise in the labels and features; (2) SpuCoAnimals, a large-scale dataset curated from ImageNet that captures spurious correlations in the wild much more closely than existing datasets. These contributions highlight the shortcomings of current methods and provide a direction for future research in tackling spurious correlations. SpuCo, containing the benchmark and datasets, can be found at https://github.com/BigML-CS-UCLA/SpuCo, with detailed documentation available at https://spuco.readthedocs.io/en/latest/.
Which Features are Learnt by Contrastive Learning? On the Role of Simplicity Bias in Class Collapse and Feature Suppression
May 29, 2023Contrastive learning (CL) has emerged as a powerful technique for representation learning, with or without label supervision. However, supervised CL is prone to collapsing representations of subclasses within a class by not capturing all their features, and unsupervised CL may suppress harder class-relevant features by focusing on learning easy class-irrelevant features; both significantly compromise representation quality. Yet, there is no theoretical understanding of \textit{class collapse} or \textit{feature suppression} at \textit{test} time. We provide the first unified theoretically rigorous framework to determine \textit{which} features are learnt by CL. Our analysis indicate that, perhaps surprisingly, bias of (stochastic) gradient descent towards finding simpler solutions is a key factor in collapsing subclass representations and suppressing harder class-relevant features. Moreover, we present increasing embedding dimensionality and improving the quality of data augmentations as two theoretically motivated solutions to {feature suppression}. We also provide the first theoretical explanation for why employing supervised and unsupervised CL together yields higher-quality representations, even when using commonly-used stochastic gradient methods.
Eliminating Spurious Correlations from Pre-trained Models via Data Mixing
May 23, 2023Machine learning models pre-trained on large datasets have achieved remarkable convergence and robustness properties. However, these models often exploit spurious correlations between certain attributes and labels, which are prevalent in the majority of examples within specific categories but are not predictive of these categories in general. The learned spurious correlations may persist even after fine-tuning on new data, which degrades models' performance on examples that do not exhibit the spurious correlation. In this work, we propose a simple and highly effective method to eliminate spurious correlations from pre-trained models. The key idea of our method is to leverage a small set of examples with spurious attributes, and balance the spurious attributes across all classes via data mixing. We theoretically confirm the effectiveness of our method, and empirically demonstrate its state-of-the-art performance on various vision and NLP tasks, including eliminating spurious correlations from pre-trained ResNet50 on Waterbirds and CelebA, adversarially pre-trained ResNet50 on ImageNet, and BERT pre-trained on CivilComments.
Superior generalization of smaller models in the presence of significant label noise
Aug 17, 2022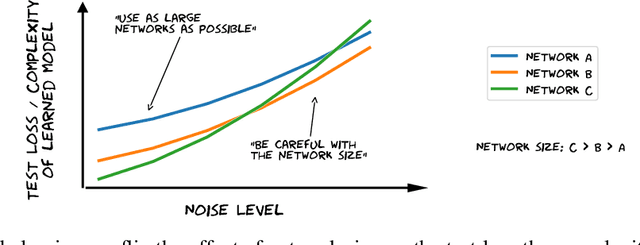
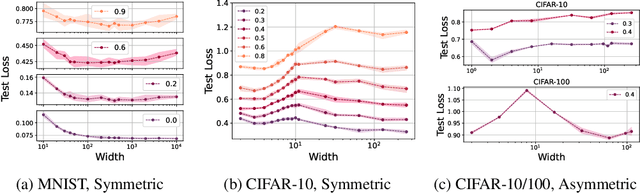
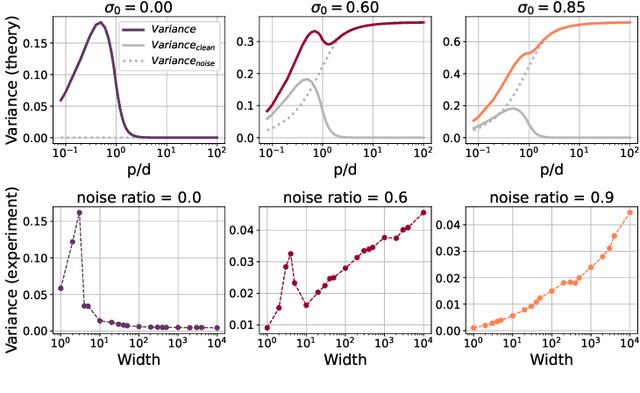
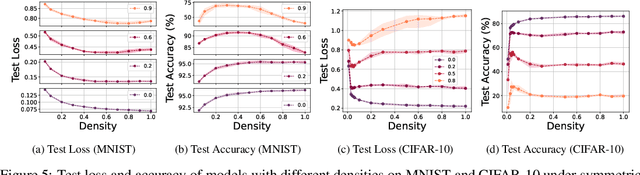
The benefits of over-parameterization in achieving superior generalization performance have been shown in several recent studies, justifying the trend of using larger models in practice. In the context of robust learning however, the effect of neural network size has not been well studied. In this work, we find that in the presence of a substantial fraction of mislabeled examples, increasing the network size beyond some point can be harmful. In particular, the originally monotonic or `double descent' test loss curve (w.r.t. network width) turns into a U-shaped or a double U-shaped curve when label noise increases, suggesting that the best generalization is achieved by some model with intermediate size. We observe that when network size is controlled by density through random pruning, similar test loss behaviour is observed. We also take a closer look into both phenomenon through bias-variance decomposition and theoretically characterize how label noise shapes the variance term. Similar behavior of the test loss can be observed even when state-of-the-art robust methods are applied, indicating that limiting the network size could further boost existing methods. Finally, we empirically examine the effect of network size on the smoothness of learned functions, and find that the originally negative correlation between size and smoothness is flipped by label noise.
Investigating Why Contrastive Learning Benefits Robustness Against Label Noise
Jan 29, 2022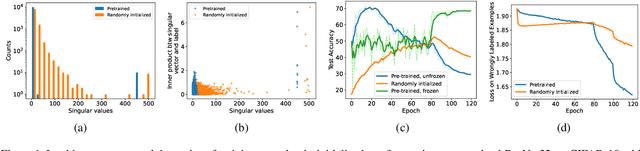
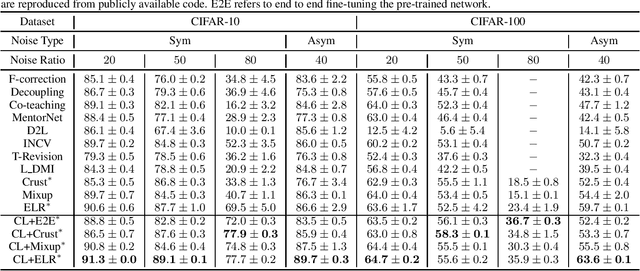
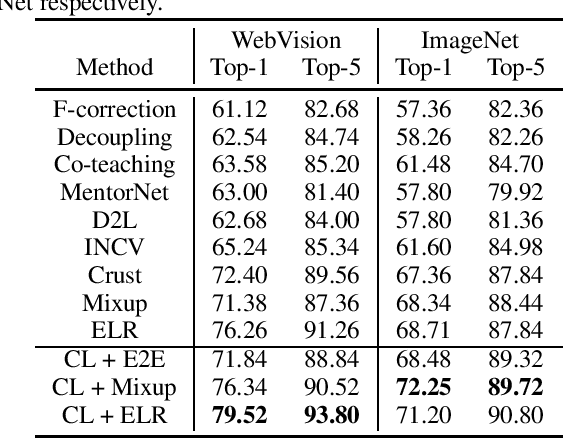
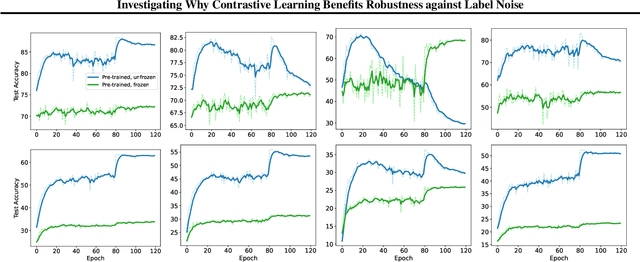
Self-supervised contrastive learning has recently been shown to be very effective in preventing deep networks from overfitting noisy labels. Despite its empirical success, the theoretical understanding of the effect of contrastive learning on boosting robustness is very limited. In this work, we rigorously prove that the representation matrix learned by contrastive learning boosts robustness, by having: (i) one prominent singular value corresponding to every sub-class in the data, and remaining significantly smaller singular values; and (ii) a large alignment between the prominent singular vector and the clean labels of each sub-class. The above properties allow a linear layer trained on the representations to quickly learn the clean labels, and prevent it from overfitting the noise for a large number of training iterations. We further show that the low-rank structure of the Jacobian of deep networks pre-trained with contrastive learning allows them to achieve a superior performance initially, when fine-tuned on noisy labels. Finally, we demonstrate that the initial robustness provided by contrastive learning enables robust training methods to achieve state-of-the-art performance under extreme noise levels, e.g., an average of 27.18\% and 15.58\% increase in accuracy on CIFAR-10 and CIFAR-100 with 80\% symmetric noisy labels, and 4.11\% increase in accuracy on WebVision.