 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Why Contrastive Learning Benefits Robustness Against Label Noise
Paper and Code
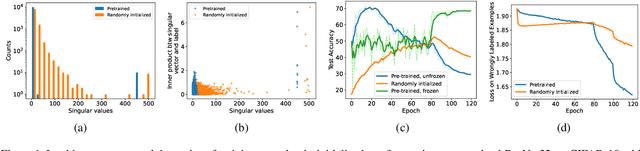
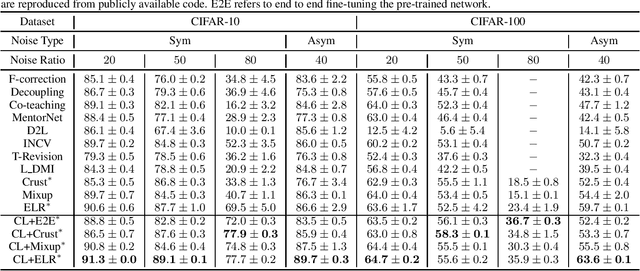
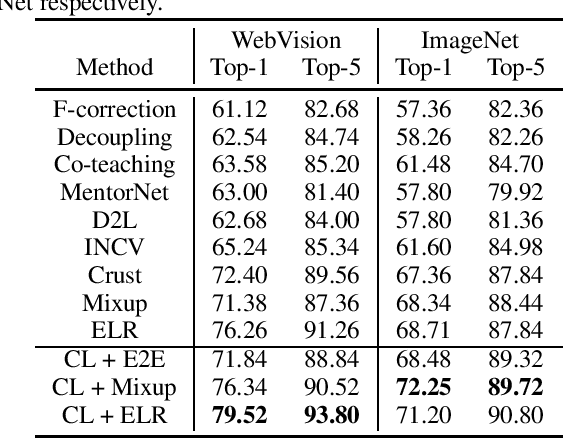
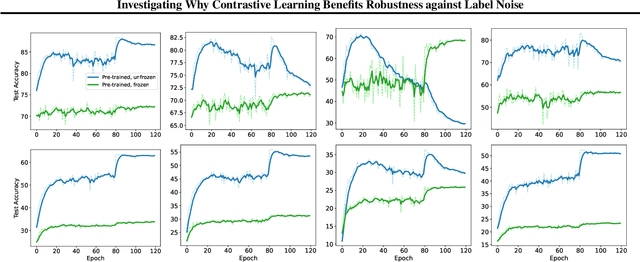
Self-supervised contrastive learning has recently been shown to be very effective in preventing deep networks from overfitting noisy labels. Despite its empirical success, the theoretical understanding of the effect of contrastive learning on boosting robustness is very limited. In this work, we rigorously prove that the representation matrix learned by contrastive learning boosts robustness, by having: (i) one prominent singular value corresponding to every sub-class in the data, and remaining significantly smaller singular values; and (ii) a large alignment between the prominent singular vector and the clean labels of each sub-class. The above properties allow a linear layer trained on the representations to quickly learn the clean labels, and prevent it from overfitting the noise for a large number of training iterations. We further show that the low-rank structure of the Jacobian of deep networks pre-trained with contrastive learning allows them to achieve a superior performance initially, when fine-tuned on noisy labels. Finally, we demonstrate that the initial robustness provided by contrastive learning enables robust training methods to achieve state-of-the-art performance under extreme noise levels, e.g., an average of 27.18\% and 15.58\% increase in accuracy on CIFAR-10 and CIFAR-100 with 80\% symmetric noisy labels, and 4.11\% increase in accuracy on WebVision.