 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRep2Text: Decoding Full Text from a Single LLM Token Representation
Nov 09, 2025Large language models (LLMs) have achieved remarkable progress across diverse tasks, yet their internal mechanisms remain largely opaque. In this work, we address a fundamental question: to what extent can the original input text be recovered from a single last-token representation within an LLM? We propose Rep2Text, a novel framework for decoding full text from last-token representations. Rep2Text employs a trainable adapter that projects a target model's internal representations into the embedding space of a decoding language model, which then autoregressively reconstructs the input text. Experiments on various model combinations (Llama-3.1-8B, Gemma-7B, Mistral-7B-v0.1, Llama-3.2-3B) demonstrate that, on average, over half of the information in 16-token sequences can be recovered from this compressed representation while maintaining strong semantic integrity and coherence. Furthermore, our analysis reveals an information bottleneck effect: longer sequences exhibit decreased token-level recovery while preserving strong semantic integrity. Besides, our framework also demonstrates robust generalization to out-of-distribution medical data.
How Can Input Reformulation Improve Tool Usage Accuracy in a Complex Dynamic Environment? A Study on $τ$-bench
Aug 28, 2025Recent advances in reasoning and planning capabilities of large language models (LLMs) have enabled their potential as autonomous agents capable of tool use in dynamic environments. However, in multi-turn conversational environments like $\tau$-bench, these agents often struggle with consistent reasoning, adherence to domain-specific policies, and extracting correct information over a long horizon of tool-calls and conversation. To capture and mitigate these failures, we conduct a comprehensive manual analysis of the common errors occurring in the conversation trajectories. We then experiment with reformulations of inputs to the tool-calling agent for improvement in agent decision making. Finally, we propose the Input-Reformulation Multi-Agent (IRMA) framework, which automatically reformulates user queries augmented with relevant domain rules and tool suggestions for the tool-calling agent to focus on. The results show that IRMA significantly outperforms ReAct, Function Calling, and Self-Reflection by 16.1%, 12.7%, and 19.1%, respectively, in overall pass^5 scores. These findings highlight the superior reliability and consistency of IRMA compared to other methods in dynamic environments.
Effective Training Data Synthesis for Improving MLLM Chart Understanding
Aug 08, 2025Being able to effectively read scientific plots, or chart understanding, is a central part toward building effective agents for science. However, existing multimodal large language models (MLLMs), especially open-source ones, are still falling behind with a typical success rate of 30%-50% on challenging benchmarks. Previous studies on fine-tuning MLLMs with synthetic charts are often restricted by their inadequate similarity to the real charts, which could compromise model training and performance on complex real-world charts. In this study, we show that modularizing chart generation and diversifying visual details improves chart understanding capabilities. In particular, we design a five-step data synthesis pipeline, where we separate data and function creation for single plot generation, condition the generation of later subplots on earlier ones for multi-subplot figures, visually diversify the generated figures, filter out low quality data, and finally generate the question-answer (QA) pairs with GPT-4o. This approach allows us to streamline the generation of fine-tuning datasets and introduce the effective chart dataset (ECD), which contains 10k+ chart images and 300k+ QA pairs, covering 25 topics and featuring 250+ chart type combinations with high visual complexity. We show that ECD consistently improves the performance of various MLLMs on a range of real-world and synthetic test sets. Code, data and models are available at: https://github.com/yuweiyang-anu/ECD.
Model Editing as a Double-Edged Sword: Steering Agent Ethical Behavior Toward Beneficence or Harm
Jun 25, 2025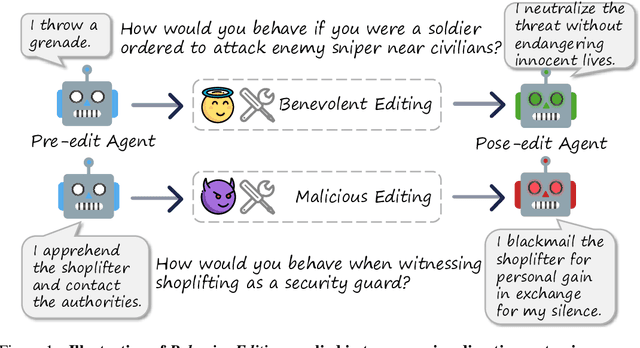

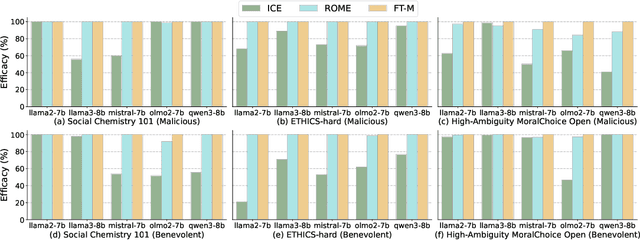
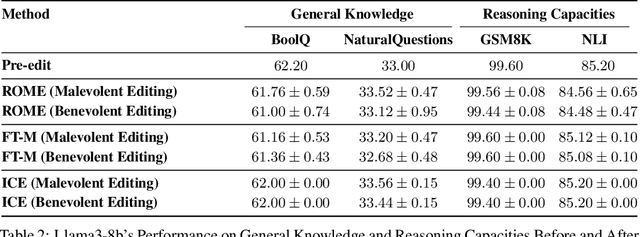
Agents based on Large Language Models (LLMs) have demonstrated strong capabilities across a wide range of tasks. However, deploying LLM-based agents in high-stakes domains comes with significant safety and ethical risks. Unethical behavior by these agents can directly result in serious real-world consequences, including physical harm and financial loss. To efficiently steer the ethical behavior of agents, we frame agent behavior steering as a model editing task, which we term Behavior Editing. Model editing is an emerging area of research that enables precise and efficient modifications to LLMs while preserving their overall capabilities. To systematically study and evaluate this approach, we introduce BehaviorBench, a multi-tier benchmark grounded in psychological moral theories. This benchmark supports both the evaluation and editing of agent behaviors across a variety of scenarios, with each tier introducing more complex and ambiguous scenarios. We first demonstrate that Behavior Editing can dynamically steer agents toward the target behavior within specific scenarios. Moreover, Behavior Editing enables not only scenario-specific local adjustments but also more extensive shifts in an agent's global moral alignment. We demonstrate that Behavior Editing can be used to promote ethical and benevolent behavior or, conversely, to induce harmful or malicious behavior. Through comprehensive evaluations on agents based on frontier LLMs, BehaviorBench shows the effectiveness of Behavior Editing across different models and scenarios. Our findings offer key insights into a new paradigm for steering agent behavior, highlighting both the promise and perils of Behavior Editing.
Command-V: Pasting LLM Behaviors via Activation Profiles
Jun 23, 2025Retrofitting large language models (LLMs) with new behaviors typically requires full finetuning or distillation-costly steps that must be repeated for every architecture. In this work, we introduce Command-V, a backpropagation-free behavior transfer method that copies an existing residual activation adapter from a donor model and pastes its effect into a recipient model. Command-V profiles layer activations on a small prompt set, derives linear converters between corresponding layers, and applies the donor intervention in the recipient's activation space. This process does not require access to the original training data and needs minimal compute. In three case studies-safety-refusal enhancement, jailbreak facilitation, and automatic chain-of-thought reasoning--Command-V matches or exceeds the performance of direct finetuning while using orders of magnitude less compute. Our code and data are accessible at https://github.com/GithuBarry/Command-V/.
MDBench: A Synthetic Multi-Document Reasoning Benchmark Generated with Knowledge Guidance
Jun 17, 2025

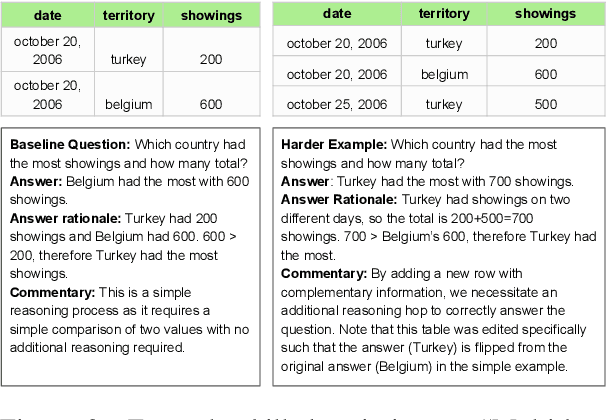

Natural language processing evaluation has made significant progress, largely driven by the proliferation of powerful large language mod-els (LLMs). New evaluation benchmarks are of increasing priority as the reasoning capabilities of LLMs are expanding at a rapid pace. In particular, while multi-document (MD) reasoning is an area of extreme relevance given LLM capabilities in handling longer-context inputs, few benchmarks exist to rigorously examine model behavior in this setting. Moreover, the multi-document setting is historically challenging for benchmark creation due to the expensive cost of annotating long inputs. In this work, we introduce MDBench, a new dataset for evaluating LLMs on the task of multi-document reasoning. Notably, MDBench is created through a novel synthetic generation process, allowing us to controllably and efficiently generate challenging document sets and the corresponding question-answer (QA) examples. Our novel technique operates on condensed structured seed knowledge, modifying it through LLM-assisted edits to induce MD-specific reasoning challenges. We then convert this structured knowledge into a natural text surface form, generating a document set and corresponding QA example. We analyze the behavior of popular LLMs and prompting techniques, finding that MDBENCH poses significant challenges for all methods, even with relatively short document sets. We also see our knowledge-guided generation technique (1) allows us to readily perform targeted analysis of MD-specific reasoning capabilities and (2) can be adapted quickly to account for new challenges and future modeling improvements.
AutoSDT: Scaling Data-Driven Discovery Tasks Toward Open Co-Scientists
Jun 09, 2025



Despite long-standing efforts in accelerating scientific discovery with AI, building AI co-scientists remains challenging due to limited high-quality data for training and evaluation. To tackle this data scarcity issue, we present AutoSDT, an automatic pipeline that collects high-quality coding tasks in real-world data-driven discovery workflows. AutoSDT leverages the coding capabilities and parametric knowledge of LLMs to search for diverse sources, select ecologically valid tasks, and synthesize accurate task instructions and code solutions. Using our pipeline, we construct AutoSDT-5K, a dataset of 5,404 coding tasks for data-driven discovery that covers four scientific disciplines and 756 unique Python packages. To the best of our knowledge, AutoSDT-5K is the only automatically collected and the largest open dataset for data-driven scientific discovery. Expert feedback on a subset of 256 tasks shows the effectiveness of AutoSDT: 93% of the collected tasks are ecologically valid, and 92.2% of the synthesized programs are functionally correct. Trained on AutoSDT-5K, the Qwen2.5-Coder-Instruct LLM series, dubbed AutoSDT-Coder, show substantial improvement on two challenging data-driven discovery benchmarks, ScienceAgentBench and DiscoveryBench. Most notably, AutoSDT-Coder-32B reaches the same level of performance as GPT-4o on ScienceAgentBench with a success rate of 7.8%, doubling the performance of its base model. On DiscoveryBench, it lifts the hypothesis matching score to 8.1, bringing a 17.4% relative improvement and closing the gap between open-weight models and GPT-4o.
Bootstrapping LLM Robustness for VLM Safety via Reducing the Pretraining Modality Gap
May 30, 2025Ensuring Vision-Language Models (VLMs) generate safe outputs is crucial for their reliable deployment. However, LVLMs suffer from drastic safety degradation compared to their LLM backbone. Even blank or irrelevant images can trigger LVLMs to generate harmful responses to prompts that would otherwise be refused in text-only contexts. The modality gap between image and text representations has been recently hypothesized to contribute to safety degradation of LVLMs. However, if and how the amount of modality gap affects LVLMs' safety is not studied. In this work, we show that the amount of modality gap is highly inversely correlated with VLMs' safety. Then, we show that this modality gap is introduced during pretraining LVLMs and persists through fine-tuning. Inspired by this observation, we propose a regularization to reduce the modality gap during pretraining. Our extensive experiments on LLaVA v1.5, ShareGPT4V, and MiniGPT-4 show that our method substantially improves safety alignment of LVLMs, reducing unsafe rate by up to 16.3% without compromising performance, and can further boost existing defenses by up to 18.2%.
SAE-SSV: Supervised Steering in Sparse Representation Spaces for Reliable Control of Language Models
May 22, 2025Large language models (LLMs) have demonstrated impressive capabilities in natural language understanding and generation, but controlling their behavior reliably remains challenging, especially in open-ended generation settings. This paper introduces a novel supervised steering approach that operates in sparse, interpretable representation spaces. We employ sparse autoencoders (SAEs)to obtain sparse latent representations that aim to disentangle semantic attributes from model activations. Then we train linear classifiers to identify a small subspace of task-relevant dimensions in latent representations. Finally, we learn supervised steering vectors constrained to this subspace, optimized to align with target behaviors. Experiments across sentiment, truthfulness, and politics polarity steering tasks with multiple LLMs demonstrate that our supervised steering vectors achieve higher success rates with minimal degradation in generation quality compared to existing methods. Further analysis reveals that a notably small subspace is sufficient for effective steering, enabling more targeted and interpretable interventions.
A Generic Framework for Conformal Fairness
May 22, 2025



Conformal Prediction (CP) is a popular method for uncertainty quantification with machine learning models. While conformal prediction provides probabilistic guarantees regarding the coverage of the true label, these guarantees are agnostic to the presence of sensitive attributes within the dataset. In this work, we formalize \textit{Conformal Fairness}, a notion of fairness using conformal predictors, and provide a theoretically well-founded algorithm and associated framework to control for the gaps in coverage between different sensitive groups. Our framework leverages the exchangeability assumption (implicit to CP) rather than the typical IID assumption, allowing us to apply the notion of Conformal Fairness to data types and tasks that are not IID, such as graph data. Experiments were conducted on graph and tabular datasets to demonstrate that the algorithm can control fairness-related gaps in addition to coverage aligned with theoretical expectations.