 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Sparsification for Enhanced Conformal Prediction in Graph Neural Networks
Oct 28, 2024Conformal Prediction is a robust framework that ensures reliable coverage across machine learning tasks. Although recent studies have applied conformal prediction to graph neural networks, they have largely emphasized post-hoc prediction set generation. Improving conformal prediction during the training stage remains unaddressed. In this work, we tackle this challenge from a denoising perspective by introducing SparGCP, which incorporates graph sparsification and a conformal prediction-specific objective into GNN training. SparGCP employs a parameterized graph sparsification module to filter out task-irrelevant edges, thereby improving conformal prediction efficiency. Extensive experiments on real-world graph datasets demonstrate that SparGCP outperforms existing methods, reducing prediction set sizes by an average of 32\% and scaling seamlessly to large networks on commodity GPUs.
Benchmarking Graph Conformal Prediction: Empirical Analysis, Scalability, and Theoretical Insights
Sep 26, 2024Conformal prediction has become increasingly popular for quantifying the uncertainty associated with machine learning models. Recent work in graph uncertainty quantification has built upon this approach for conformal graph prediction. The nascent nature of these explorations has led to conflicting choices for implementations, baselines, and method evaluation. In this work, we analyze the design choices made in the literature and discuss the tradeoffs associated with existing methods. Building on the existing implementations for existing methods, we introduce techniques to scale existing methods to large-scale graph datasets without sacrificing performance. Our theoretical and empirical results justify our recommendations for future scholarship in graph conformal prediction.
HeteroMILE: a Multi-Level Graph Representation Learning Framework for Heterogeneous Graphs
Mar 31, 2024Heterogeneous graphs are ubiquitous in real-world applications because they can represent various relationships between different types of entities. Therefore, learning embeddings in such graphs is a critical problem in graph machine learning. However, existing solutions for this problem fail to scale to large heterogeneous graphs due to their high computational complexity. To address this issue, we propose a Multi-Level Embedding framework of nodes on a heterogeneous graph (HeteroMILE) - a generic methodology that allows contemporary graph embedding methods to scale to large graphs. HeteroMILE repeatedly coarsens the large sized graph into a smaller size while preserving the backbone structure of the graph before embedding it, effectively reducing the computational cost by avoiding time-consuming processing operations. It then refines the coarsened embedding to the original graph using a heterogeneous graph convolution neural network. We evaluate our approach using several popular heterogeneous graph datasets. The experimental results show that HeteroMILE can substantially reduce computational time (approximately 20x speedup) and generate an embedding of better quality for link prediction and node classification.
FairMILE: A Multi-Level Framework for Fair and Scalable Graph Representation Learning
Nov 17, 2022Graph representation learning models have been deployed for making decisions in multiple high-stakes scenarios. It is therefore critical to ensure that these models are fair. Prior research has shown that graph neural networks can inherit and reinforce the bias present in graph data. Researchers have begun to examine ways to mitigate the bias in such models. However, existing efforts are restricted by their inefficiency, limited applicability, and the constraints they place on sensitive attributes. To address these issues, we present FairMILE a general framework for fair and scalable graph representation learning. FairMILE is a multi-level framework that allows contemporary unsupervised graph embedding methods to scale to large graphs in an agnostic manner. FairMILE learns both fair and high-quality node embeddings where the fairness constraints are incorporated in each phase of the framework. Our experiments across two distinct tasks demonstrate that FairMILE can learn node representations that often achieve superior fairness scores and high downstream performance while significantly outperforming all the baselines in terms of efficiency.
Sepsis Prediction with Temporal Convolutional Networks
May 31, 2022



We design and implement a temporal convolutional network model to predict sepsis onset. Our model is trained on data extracted from MIMIC III database, based on a retrospective analysis of patients admitted to intensive care unit who did not fall under the definition of sepsis at the time of admission. Benchmarked with several machine learning models, our model is superior on this binary classification task, demonstrates the prediction power of convolutional networks for temporal patterns, also shows the significant impact of having longer look back time on sepsis prediction.
FairMod: Fair Link Prediction and Recommendation via Graph Modification
Jan 27, 2022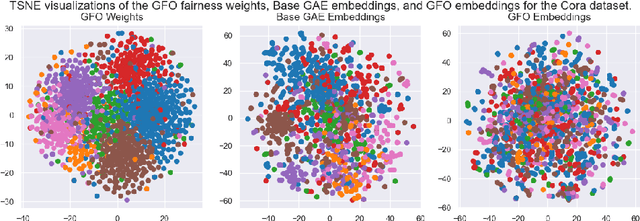
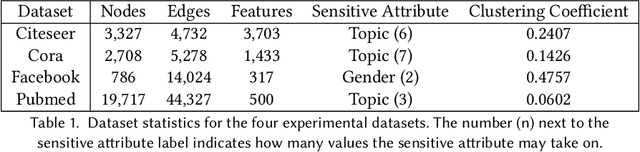
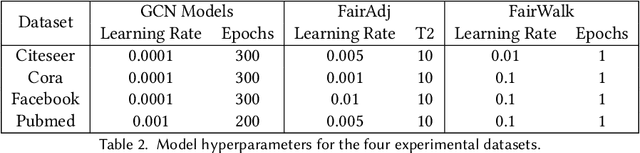
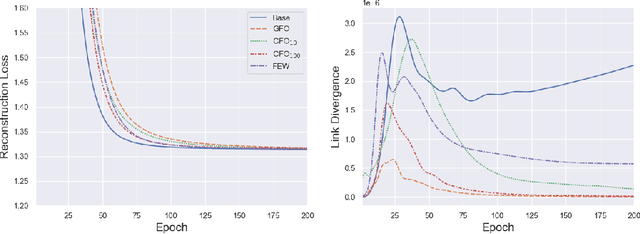
As machine learning becomes more widely adopted across domains, it is critical that researchers and ML engineers think about the inherent biases in the data that may be perpetuated by the model. Recently, many studies have shown that such biases are also imbibed in Graph Neural Network (GNN) models if the input graph is biased. In this work, we aim to mitigate the bias learned by GNNs through modifying the input graph. To that end, we propose FairMod, a Fair Graph Modification methodology with three formulations: the Global Fairness Optimization (GFO), Community Fairness Optimization (CFO), and Fair Edge Weighting (FEW) models. Our proposed models perform either microscopic or macroscopic edits to the input graph while training GNNs and learn node embeddings that are both accurate and fair under the context of link recommendations. We demonstrate the effectiveness of our approach on four real world datasets and show that we can improve the recommendation fairness by several factors at negligible cost to link prediction accuracy.
StyleML: Stylometry with Structure and Multitask Learning for Darkweb Markets
Apr 01, 2021
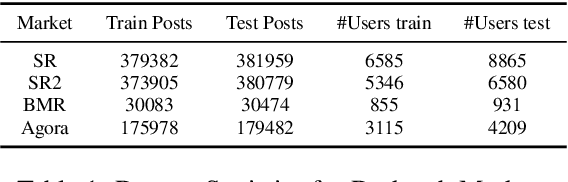
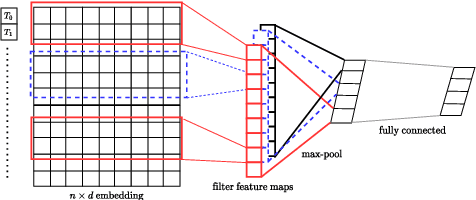

Darknet market forums are frequently used to exchange illegal goods and services between parties who use encryption to conceal their identities. The Tor network is used to host these markets, which guarantees additional anonymization from IP and location tracking, making it challenging to link across malicious users using multiple accounts (sybils). Additionally, users migrate to new forums when one is closed, making it difficult to link users across multiple forums. We develop a novel stylometry-based multitask learning approach for natural language and interaction modeling using graph embeddings to construct low-dimensional representations of short episodes of user activity for authorship attribution. We provide a comprehensive evaluation of our methods across four different darknet forums demonstrating its efficacy over the state-of-the-art, with a lift of up to 2.5X on Mean Retrieval Rank and 2X on Recall@10.