 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-VMNet: Accelerating Long-Form Video Understanding via Fixed Memory
Mar 17, 2025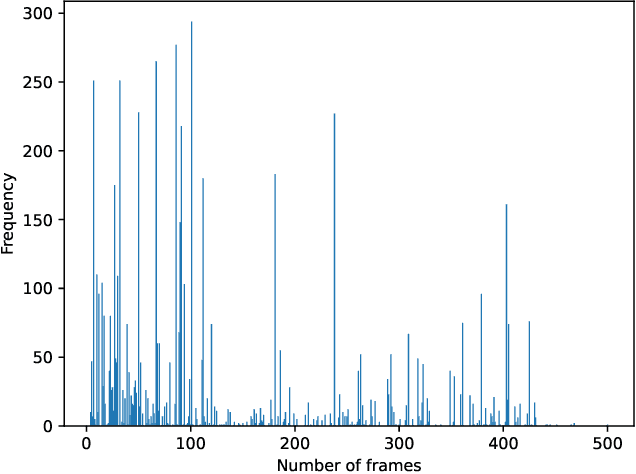
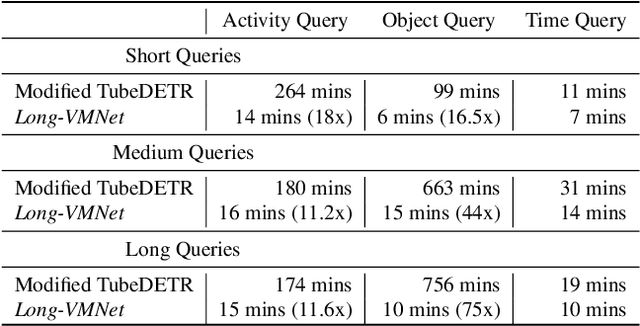
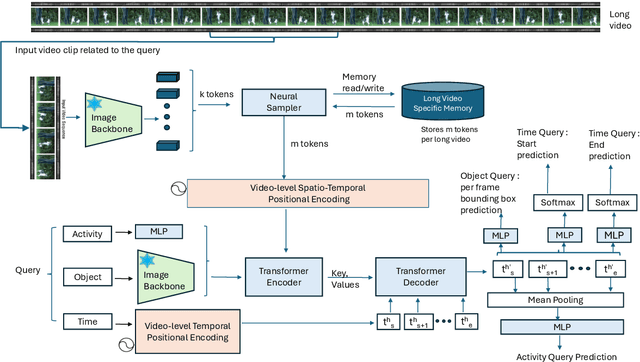
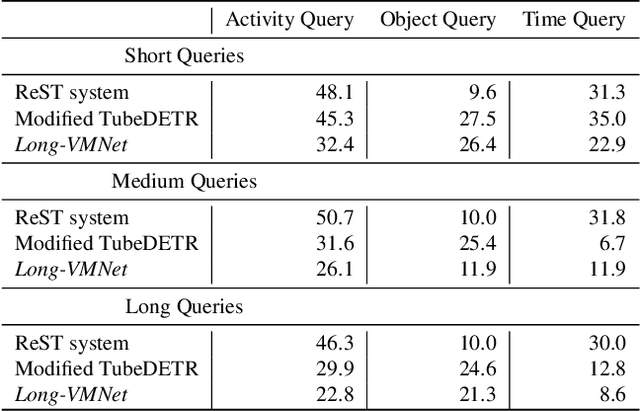
Long-form video understanding is essential for various applications such as video retrieval, summarizing, and question answering. Yet, traditional approaches demand substantial computing power and are often bottlenecked by GPU memory. To tackle this issue, we present Long-Video Memory Network, Long-VMNet, a novel video understanding method that employs a fixed-size memory representation to store discriminative patches sampled from the input video. Long-VMNet achieves improved efficiency by leveraging a neural sampler that identifies discriminative tokens. Additionally, Long-VMNet only needs one scan through the video, greatly boosting efficiency. Our results on the Rest-ADL dataset demonstrate an 18x -- 75x improvement in inference times for long-form video retrieval and answering questions, with a competitive predictive performance.
HeteroMILE: a Multi-Level Graph Representation Learning Framework for Heterogeneous Graphs
Mar 31, 2024Heterogeneous graphs are ubiquitous in real-world applications because they can represent various relationships between different types of entities. Therefore, learning embeddings in such graphs is a critical problem in graph machine learning. However, existing solutions for this problem fail to scale to large heterogeneous graphs due to their high computational complexity. To address this issue, we propose a Multi-Level Embedding framework of nodes on a heterogeneous graph (HeteroMILE) - a generic methodology that allows contemporary graph embedding methods to scale to large graphs. HeteroMILE repeatedly coarsens the large sized graph into a smaller size while preserving the backbone structure of the graph before embedding it, effectively reducing the computational cost by avoiding time-consuming processing operations. It then refines the coarsened embedding to the original graph using a heterogeneous graph convolution neural network. We evaluate our approach using several popular heterogeneous graph datasets. The experimental results show that HeteroMILE can substantially reduce computational time (approximately 20x speedup) and generate an embedding of better quality for link prediction and node classification.
PolicyClusterGCN: Identifying Efficient Clusters for Training Graph Convolutional Networks
Jun 25, 2023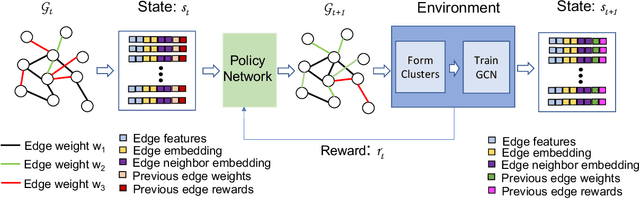

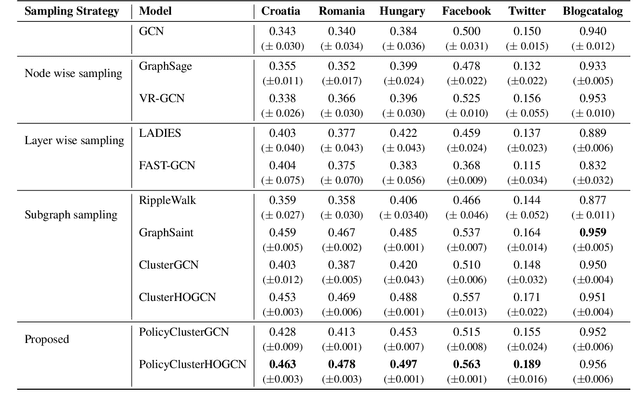
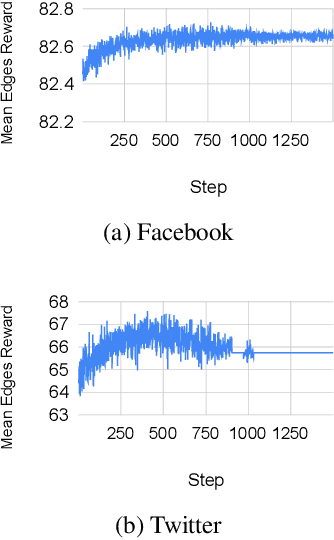
Graph convolutional networks (GCNs) have achieved huge success in several machine learning (ML) tasks on graph-structured data. Recently, several sampling techniques have been proposed for the efficient training of GCNs and to improve the performance of GCNs on ML tasks. Specifically, the subgraph-based sampling approaches such as ClusterGCN and GraphSAINT have achieved state-of-the-art performance on the node classification tasks. These subgraph-based sampling approaches rely on heuristics -- such as graph partitioning via edge cuts -- to identify clusters that are then treated as minibatches during GCN training. In this work, we hypothesize that rather than relying on such heuristics, one can learn a reinforcement learning (RL) policy to compute efficient clusters that lead to effective GCN performance. To that end, we propose PolicyClusterGCN, an online RL framework that can identify good clusters for GCN training. We develop a novel Markov Decision Process (MDP) formulation that allows the policy network to predict ``importance" weights on the edges which are then utilized by a clustering algorithm (Graclus) to compute the clusters. We train the policy network using a standard policy gradient algorithm where the rewards are computed from the classification accuracies while training GCN using clusters given by the policy. Experiments on six real-world datasets and several synthetic datasets show that PolicyClusterGCN outperforms existing state-of-the-art models on node classification task.
FairMILE: A Multi-Level Framework for Fair and Scalable Graph Representation Learning
Nov 17, 2022Graph representation learning models have been deployed for making decisions in multiple high-stakes scenarios. It is therefore critical to ensure that these models are fair. Prior research has shown that graph neural networks can inherit and reinforce the bias present in graph data. Researchers have begun to examine ways to mitigate the bias in such models. However, existing efforts are restricted by their inefficiency, limited applicability, and the constraints they place on sensitive attributes. To address these issues, we present FairMILE a general framework for fair and scalable graph representation learning. FairMILE is a multi-level framework that allows contemporary unsupervised graph embedding methods to scale to large graphs in an agnostic manner. FairMILE learns both fair and high-quality node embeddings where the fairness constraints are incorporated in each phase of the framework. Our experiments across two distinct tasks demonstrate that FairMILE can learn node representations that often achieve superior fairness scores and high downstream performance while significantly outperforming all the baselines in terms of efficiency.
MultiBiSage: A Web-Scale Recommendation System Using Multiple Bipartite Graphs at Pinterest
May 21, 2022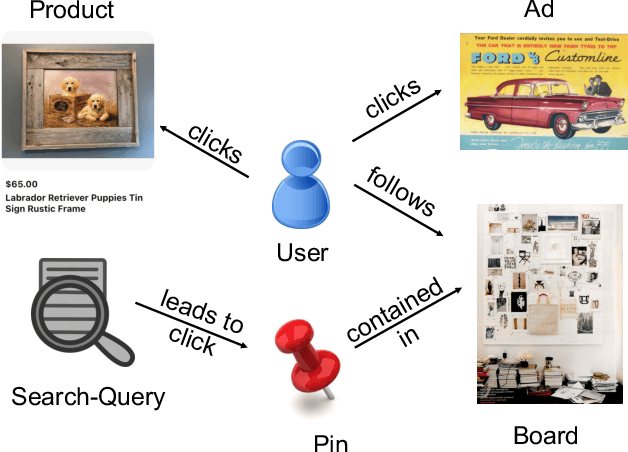

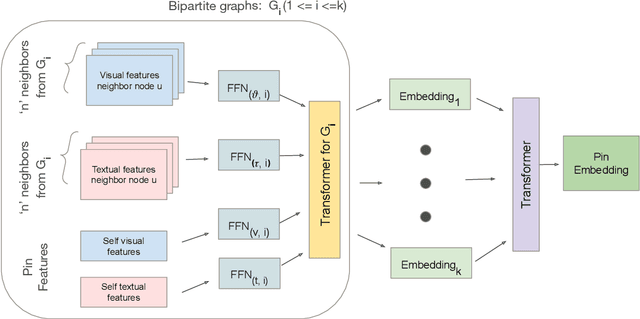
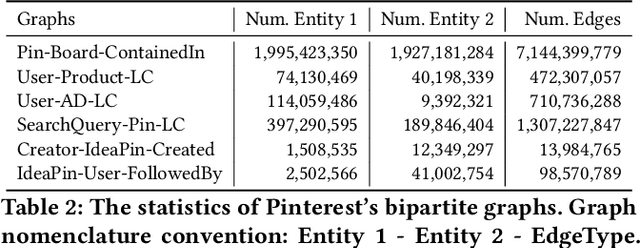
Graph Convolutional Networks (GCN) can efficiently integrate graph structure and node features to learn high-quality node embeddings. These embeddings can then be used for several tasks such as recommendation and search. At Pinterest, we have developed and deployed PinSage, a data-efficient GCN that learns pin embeddings from the Pin-Board graph. The Pin-Board graph contains pin and board entities and the graph captures the pin belongs to a board interaction. However, there exist several entities at Pinterest such as users, idea pins, creators, and there exist heterogeneous interactions among these entities such as add-to-cart, follow, long-click. In this work, we show that training deep learning models on graphs that captures these diverse interactions would result in learning higher-quality pin embeddings than training PinSage on only the Pin-Board graph. To that end, we model the diverse entities and their diverse interactions through multiple bipartite graphs and propose a novel data-efficient MultiBiSage model. MultiBiSage can capture the graph structure of multiple bipartite graphs to learn high-quality pin embeddings. We take this pragmatic approach as it allows us to utilize the existing infrastructure developed at Pinterest -- such as Pixie system that can perform optimized random-walks on billion node graphs, along with existing training and deployment workflows. We train MultiBiSage on six bipartite graphs including our Pin-Board graph. Our offline metrics show that MultiBiSage significantly outperforms the deployed latest version of PinSage on multiple user engagement metrics.
FairMod: Fair Link Prediction and Recommendation via Graph Modification
Jan 27, 2022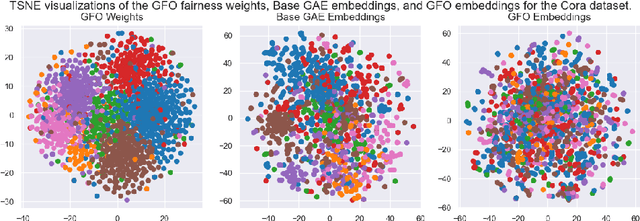
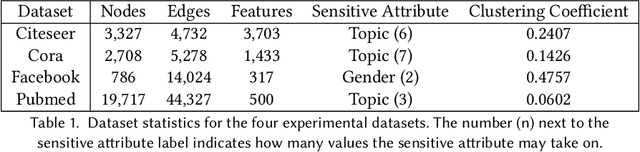
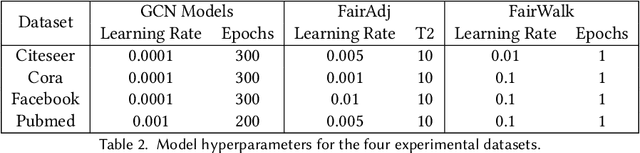
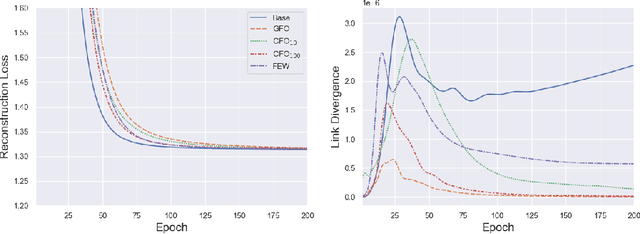
As machine learning becomes more widely adopted across domains, it is critical that researchers and ML engineers think about the inherent biases in the data that may be perpetuated by the model. Recently, many studies have shown that such biases are also imbibed in Graph Neural Network (GNN) models if the input graph is biased. In this work, we aim to mitigate the bias learned by GNNs through modifying the input graph. To that end, we propose FairMod, a Fair Graph Modification methodology with three formulations: the Global Fairness Optimization (GFO), Community Fairness Optimization (CFO), and Fair Edge Weighting (FEW) models. Our proposed models perform either microscopic or macroscopic edits to the input graph while training GNNs and learn node embeddings that are both accurate and fair under the context of link recommendations. We demonstrate the effectiveness of our approach on four real world datasets and show that we can improve the recommendation fairness by several factors at negligible cost to link prediction accuracy.
Towards Quantifying the Distance between Opinions
Jan 27, 2020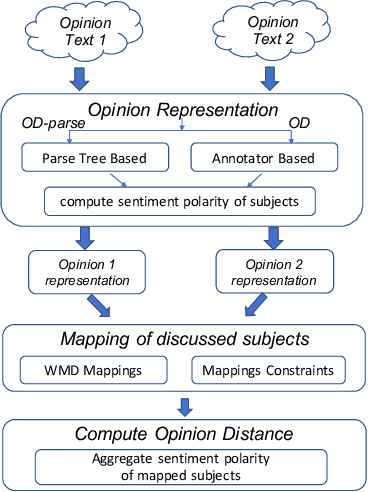


Increasingly, critical decisions in public policy, governance, and business strategy rely on a deeper understanding of the needs and opinions of constituent members (e.g. citizens, shareholders). While it has become easier to collect a large number of opinions on a topic, there is a necessity for automated tools to help navigate the space of opinions. In such contexts understanding and quantifying the similarity between opinions is key. We find that measures based solely on text similarity or on overall sentiment often fail to effectively capture the distance between opinions. Thus, we propose a new distance measure for capturing the similarity between opinions that leverages the nuanced observation -- similar opinions express similar sentiment polarity on specific relevant entities-of-interest. Specifically, in an unsupervised setting, our distance measure achieves significantly better Adjusted Rand Index scores (up to 56x) and Silhouette coefficients (up to 21x) compared to existing approaches. Similarly, in a supervised setting, our opinion distance measure achieves considerably better accuracy (up to 20% increase) compared to extant approaches that rely on text similarity, stance similarity, and sentiment similarity
Network Representation Learning: Consolidation and Renewed Bearing
May 02, 2019
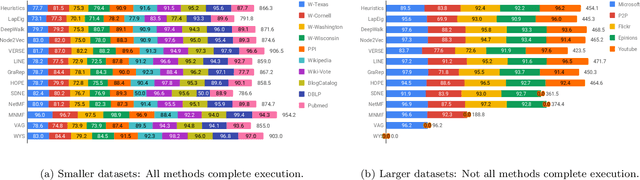
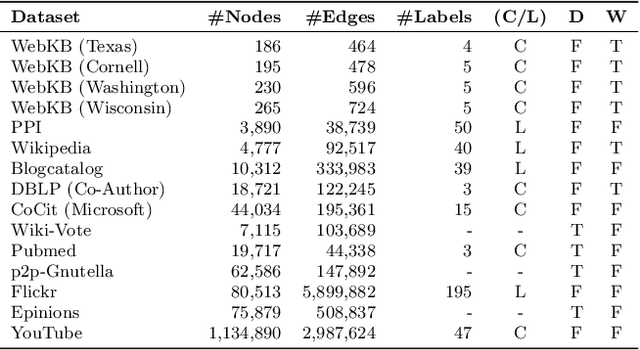
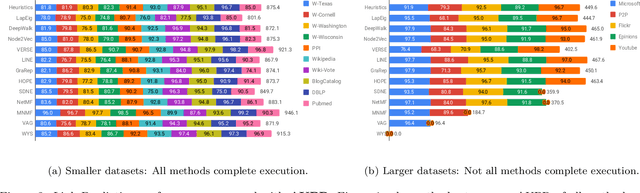
Graphs are a natural abstraction for many problems where nodes represent entities and edges represent a relationship across entities. An important area of research that has emerged over the last decade is the use of graphs as a vehicle for non-linear dimensionality reduction in a manner akin to previous efforts based on manifold learning with uses for downstream database processing, machine learning and visualization. In this systematic yet comprehensive experimental survey, we benchmark several popular network representation learning methods operating on two key tasks: link prediction and node classification. We examine the performance of 12 unsupervised embedding methods on 15 datasets. To the best of our knowledge, the scale of our study -- both in terms of the number of methods and number of datasets -- is the largest to date. Our results reveal several key insights about work-to-date in this space. First, we find that certain baseline methods (task-specific heuristics, as well as classic manifold methods) that have often been dismissed or are not considered by previous efforts can compete on certain types of datasets if they are tuned appropriately. Second, we find that recent methods based on matrix factorization offer a small but relatively consistent advantage over alternative methods (e.g., random-walk based methods) from a qualitative standpoint. Specifically, we find that MNMF, a community preserving embedding method, is the most competitive method for the link prediction task. While NetMF is the most competitive baseline for node classification. Third, no single method completely outperforms other embedding methods on both node classification and link prediction tasks. We also present several drill-down analysis that reveals settings under which certain algorithms perform well (e.g., the role of neighborhood context on performance) -- guiding the end-user.
MILE: A Multi-Level Framework for Scalable Graph Embedding
Feb 26, 2018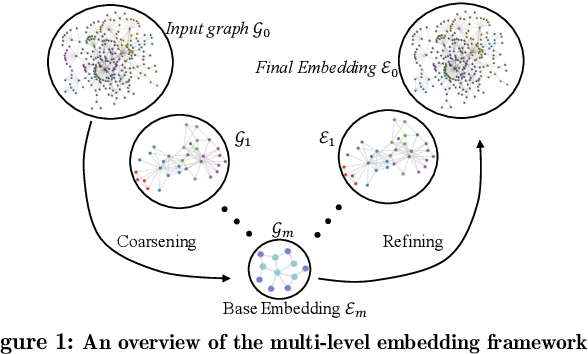
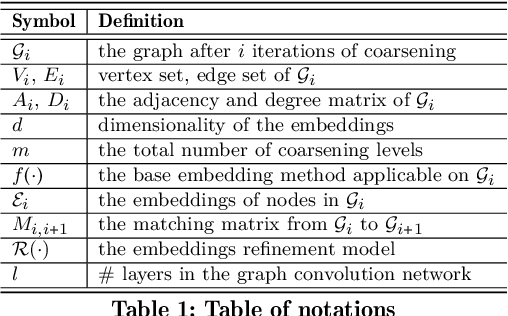
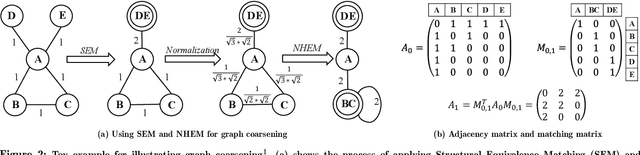
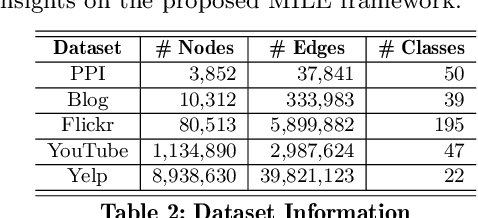
Recently there has been a surge of interest in designing graph embedding methods. Few, if any, can scale to a large-sized graph with millions of nodes due to both computational complexity and memory requirements. In this paper, we relax this limitation by introducing the MultI-Level Embedding (MILE) framework -- a generic methodology allowing contemporary graph embedding methods to scale to large graphs. MILE repeatedly coarsens the graph into smaller ones using a hybrid matching technique to maintain the backbone structure of the graph. It then applies existing embedding methods on the coarsest graph and refines the embeddings to the original graph through a novel graph convolution neural network that it learns. The proposed MILE framework is agnostic to the underlying graph embedding techniques and can be applied to many existing graph embedding methods without modifying them. We employ our framework on several popular graph embedding techniques and conduct embedding for real-world graphs. Experimental results on five large-scale datasets demonstrate that MILE significantly boosts the speed (order of magnitude) of graph embedding while also often generating embeddings of better quality for the task of node classification. MILE can comfortably scale to a graph with 9 million nodes and 40 million edges, on which existing methods run out of memory or take too long to compute on a modern workstation.