 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Prune Instances of Steiner Tree Problem in Graphs
Aug 25, 2022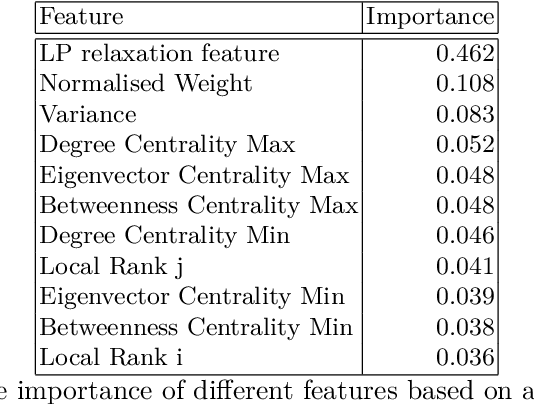
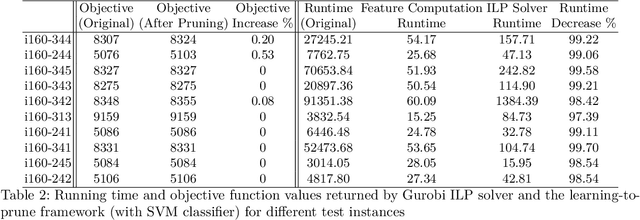
We consider the Steiner tree problem on graphs where we are given a set of nodes and the goal is to find a tree sub-graph of minimum weight that contains all nodes in the given set, potentially including additional nodes. This is a classical NP-hard combinatorial optimisation problem. In recent years, a machine learning framework called learning-to-prune has been successfully used for solving a diverse range of combinatorial optimisation problems. In this paper, we use this learning framework on the Steiner tree problem and show that even on this problem, the learning-to-prune framework results in computing near-optimal solutions at a fraction of the time required by commercial ILP solvers. Our results underscore the potential of the learning-to-prune framework in solving various combinatorial optimisation problems.
Learning to Sparsify Travelling Salesman Problem Instances
Apr 19, 2021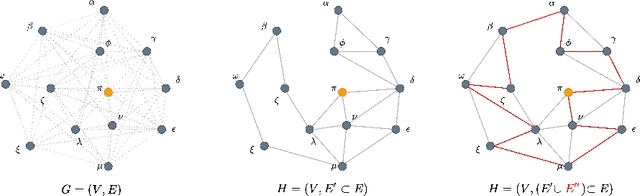


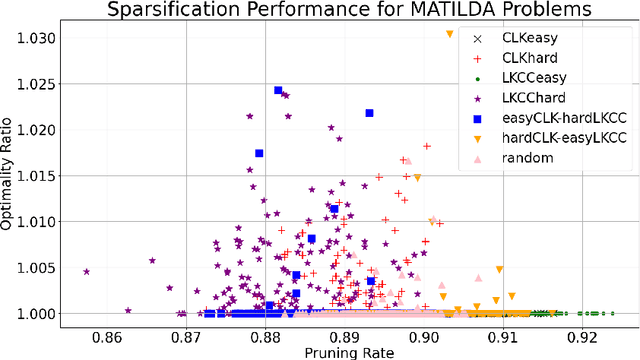
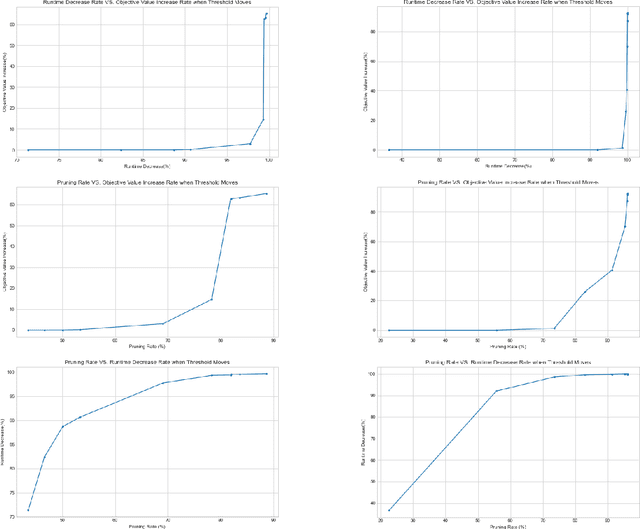
In order to deal with the high development time of exact and approximation algorithms for NP-hard combinatorial optimisation problems and the high running time of exact solvers, deep learning techniques have been used in recent years as an end-to-end approach to find solutions. However, there are issues of representation, generalisation, complex architectures, interpretability of models for mathematical analysis etc. using deep learning techniques. As a compromise, machine learning can be used to improve the run time performance of exact algorithms in a matheuristics framework. In this paper, we use a pruning heuristic leveraging machine learning as a pre-processing step followed by an exact Integer Programming approach. We apply this approach to sparsify instances of the classical travelling salesman problem. Our approach learns which edges in the underlying graph are unlikely to belong to an optimal solution and removes them, thus sparsifying the graph and significantly reducing the number of decision variables. We use carefully selected features derived from linear programming relaxation, cutting planes exploration, minimum-weight spanning tree heuristics and various other local and statistical analysis of the graph. Our learning approach requires very little training data and is amenable to mathematical analysis. We demonstrate that our approach can reliably prune a large fraction of the variables in TSP instances from TSPLIB/MATILDA (>85%$) while preserving most of the optimal tour edges. Our approach can successfully prune problem instances even if they lie outside the training distribution, resulting in small optimality gaps between the pruned and original problems in most cases. Using our learning technique, we discover novel heuristics for sparsifying TSP instances, that may be of independent interest for variants of the vehicle routing problem.
Towards Quantifying the Distance between Opinions
Jan 27, 2020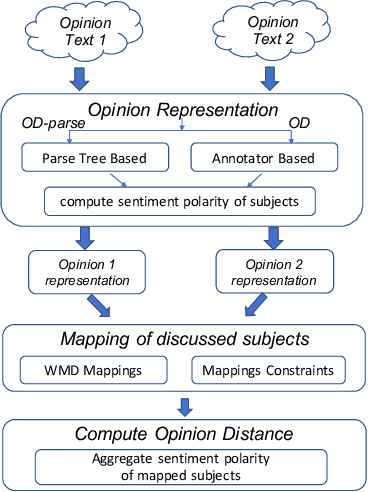


Increasingly, critical decisions in public policy, governance, and business strategy rely on a deeper understanding of the needs and opinions of constituent members (e.g. citizens, shareholders). While it has become easier to collect a large number of opinions on a topic, there is a necessity for automated tools to help navigate the space of opinions. In such contexts understanding and quantifying the similarity between opinions is key. We find that measures based solely on text similarity or on overall sentiment often fail to effectively capture the distance between opinions. Thus, we propose a new distance measure for capturing the similarity between opinions that leverages the nuanced observation -- similar opinions express similar sentiment polarity on specific relevant entities-of-interest. Specifically, in an unsupervised setting, our distance measure achieves significantly better Adjusted Rand Index scores (up to 56x) and Silhouette coefficients (up to 21x) compared to existing approaches. Similarly, in a supervised setting, our opinion distance measure achieves considerably better accuracy (up to 20% increase) compared to extant approaches that rely on text similarity, stance similarity, and sentiment similarity
Learning fine-grained search space pruning and heuristics for combinatorial optimization
Jan 05, 2020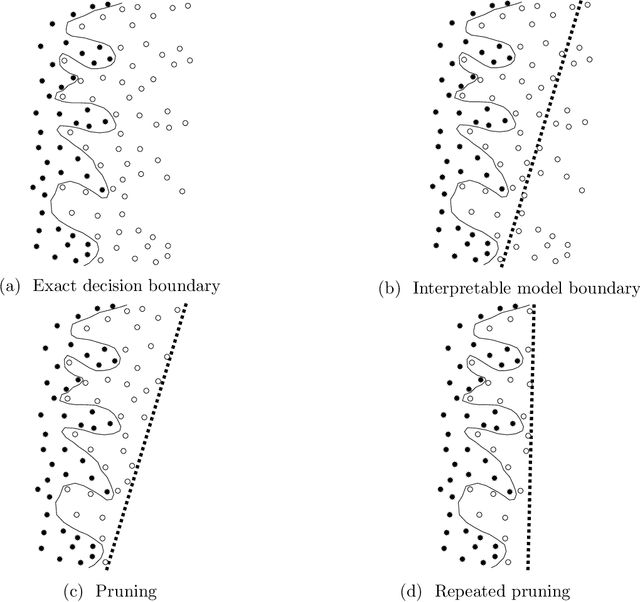

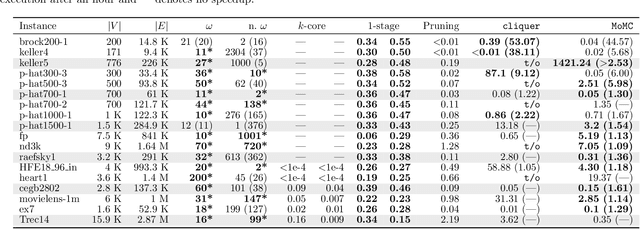
Combinatorial optimization problems arise in a wide range of applications from diverse domains. Many of these problems are NP-hard and designing efficient heuristics for them requires considerable time and experimentation. On the other hand, the number of optimization problems in the industry continues to grow. In recent years, machine learning techniques have been explored to address this gap. We propose a framework for leveraging machine learning techniques to scale-up exact combinatorial optimization algorithms. In contrast to the existing approaches based on deep-learning, reinforcement learning and restricted Boltzmann machines that attempt to directly learn the output of the optimization problem from its input (with limited success), our framework learns the relatively simpler task of pruning the elements in order to reduce the size of the problem instances. In addition, our framework uses only interpretable learning models based on intuitive features and thus the learning process provides deeper insights into the optimization problem and the instance class, that can be used for designing better heuristics. For the classical maximum clique enumeration problem, we show that our framework can prune a large fraction of the input graph (around 99 % of nodes in case of sparse graphs) and still detect almost all of the maximum cliques. This results in several fold speedups of state-of-the-art algorithms. Furthermore, the model used in our framework highlights that the chi-squared value of neighborhood degree has a statistically significant correlation with the presence of a node in a maximum clique, particularly in dense graphs which constitute a significant challenge for modern solvers. We leverage this insight to design a novel heuristic for this problem outperforming the state-of-the-art. Our heuristic is also of independent interest for maximum clique detection and enumeration.
Learning Multi-Stage Sparsification for Maximum Clique Enumeration
Sep 12, 2019

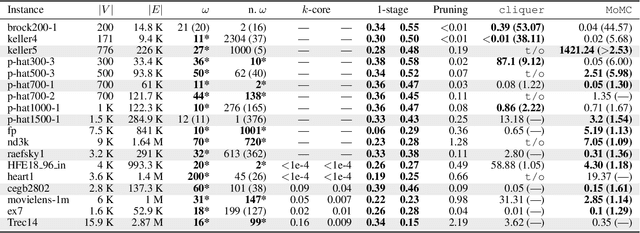
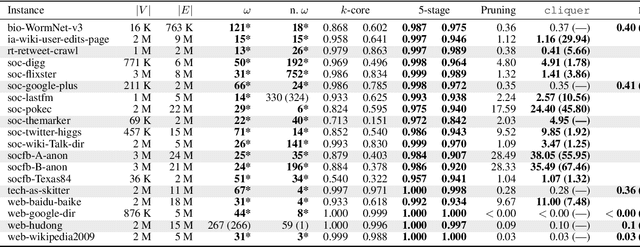
We propose a multi-stage learning approach for pruning the search space of maximum clique enumeration, a fundamental computationally difficult problem arising in various network analysis tasks. In each stage, our approach learns the characteristics of vertices in terms of various neighborhood features and leverage them to prune the set of vertices that are likely not contained in any maximum clique. Furthermore, we demonstrate that our approach is domain independent -- the same small set of features works well on graph instances from different domain. Compared to the state-of-the-art heuristics and preprocessing strategies, the advantages of our approach are that (i) it does not require any estimate on the maximum clique size at runtime and (ii) we demonstrate it to be effective also for dense graphs. In particular, for dense graphs, we typically prune around 30 \% of the vertices resulting in speedups of up to 53 times for state-of-the-art solvers while generally preserving the size of the maximum clique (though some maximum cliques may be lost). For large real-world sparse graphs, we routinely prune over 99 \% of the vertices resulting in several tenfold speedups at best, typically with no impact on solution quality.
Distributed Entity Disambiguation with Per-Mention Learning
Apr 20, 2016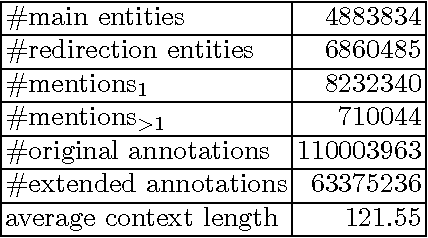
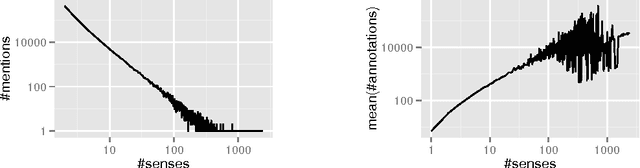
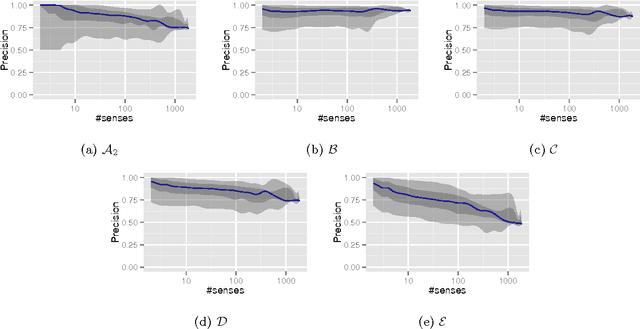
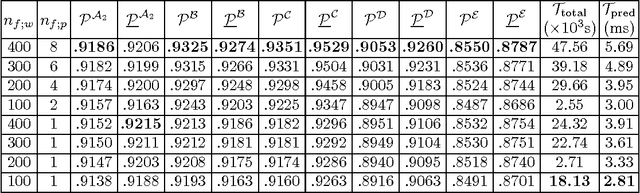
Entity disambiguation, or mapping a phrase to its canonical representation in a knowledge base, is a fundamental step in many natural language processing applications. Existing techniques based on global ranking models fail to capture the individual peculiarities of the words and hence, either struggle to meet the accuracy requirements of many real-world applications or they are too complex to satisfy real-time constraints of applications. In this paper, we propose a new disambiguation system that learns specialized features and models for disambiguating each ambiguous phrase in the English language. To train and validate the hundreds of thousands of learning models for this purpose, we use a Wikipedia hyperlink dataset with more than 170 million labelled annotations. We provide an extensive experimental evaluation to show that the accuracy of our approach compares favourably with respect to many state-of-the-art disambiguation systems. The training required for our approach can be easily distributed over a cluster. Furthermore, updating our system for new entities or calibrating it for special ones is a computationally fast process, that does not affect the disambiguation of the other entities.