 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne button machine for automating feature engineering in relational databases
Jun 01, 2017
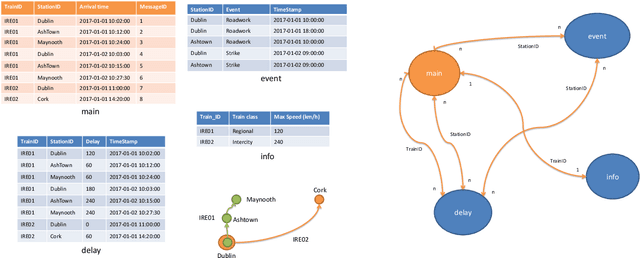
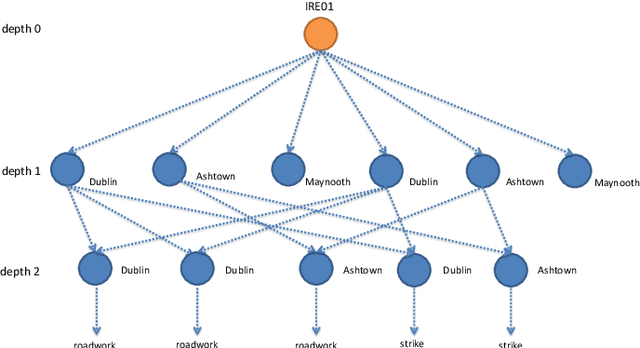
Feature engineering is one of the most important and time consuming tasks in predictive analytics projects. It involves understanding domain knowledge and data exploration to discover relevant hand-crafted features from raw data. In this paper, we introduce a system called One Button Machine, or OneBM for short, which automates feature discovery in relational databases. OneBM automatically performs a key activity of data scientists, namely, joining of database tables and applying advanced data transformations to extract useful features from data. We validated OneBM in Kaggle competitions in which OneBM achieved performance as good as top 16% to 24% data scientists in three Kaggle competitions. More importantly, OneBM outperformed the state-of-the-art system in a Kaggle competition in terms of prediction accuracy and ranking on Kaggle leaderboard. The results show that OneBM can be useful for both data scientists and non-experts. It helps data scientists reduce data exploration time allowing them to try and error many ideas in short time. On the other hand, it enables non-experts, who are not familiar with data science, to quickly extract value from their data with a little effort, time and cost.
Distributed Entity Disambiguation with Per-Mention Learning
Apr 20, 2016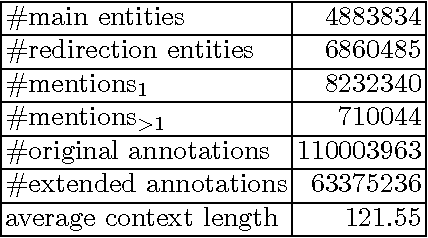
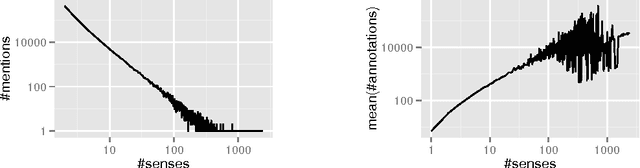
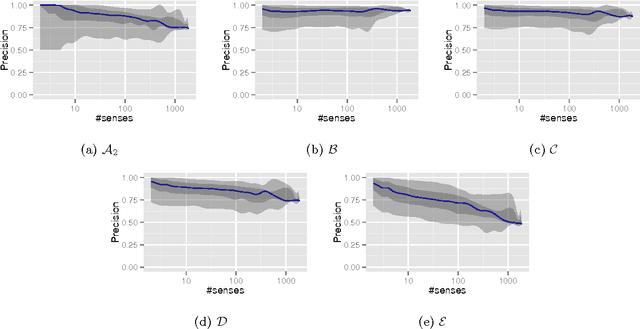
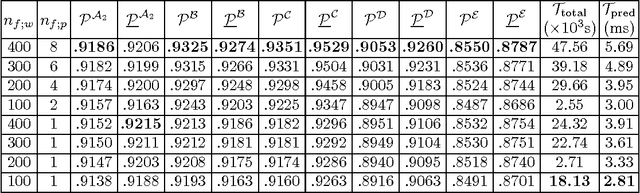
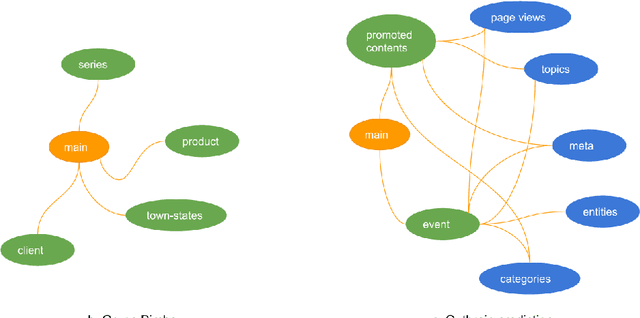
Entity disambiguation, or mapping a phrase to its canonical representation in a knowledge base, is a fundamental step in many natural language processing applications. Existing techniques based on global ranking models fail to capture the individual peculiarities of the words and hence, either struggle to meet the accuracy requirements of many real-world applications or they are too complex to satisfy real-time constraints of applications. In this paper, we propose a new disambiguation system that learns specialized features and models for disambiguating each ambiguous phrase in the English language. To train and validate the hundreds of thousands of learning models for this purpose, we use a Wikipedia hyperlink dataset with more than 170 million labelled annotations. We provide an extensive experimental evaluation to show that the accuracy of our approach compares favourably with respect to many state-of-the-art disambiguation systems. The training required for our approach can be easily distributed over a cluster. Furthermore, updating our system for new entities or calibrating it for special ones is a computationally fast process, that does not affect the disambiguation of the other entities.
Modifying iterated Laplace approximations
Sep 22, 2015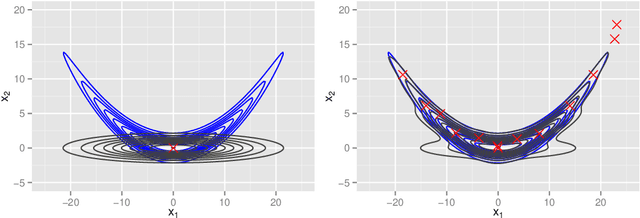
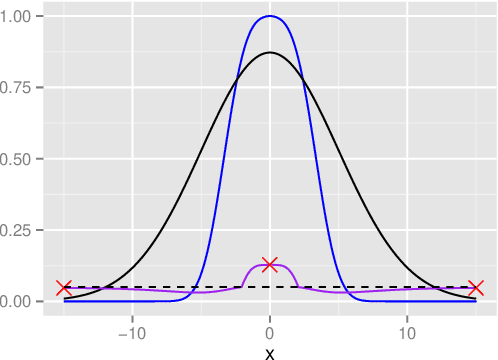
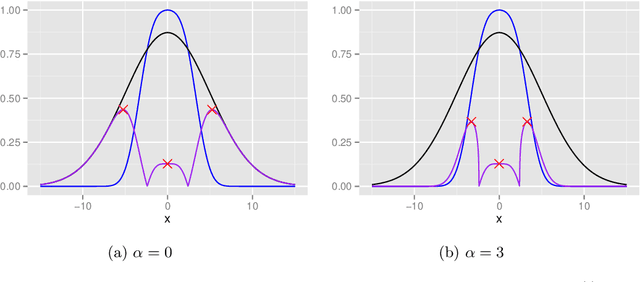
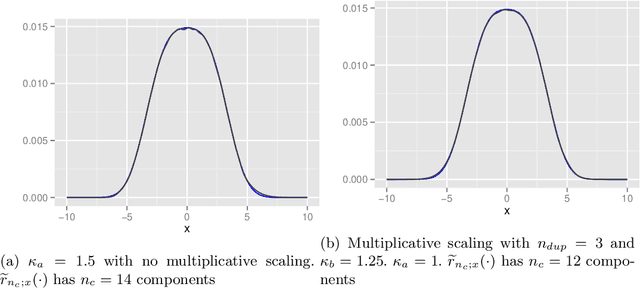
In this paper, several modifications are introduced to the functional approximation method iterLap to reduce the approximation error, including stopping rule adjustment, proposal of new residual function, starting point selection for numerical optimisation, scaling of Hessian matrix. Illustrative examples are also provided to show the trade-off between running time and accuracy of the original and modified methods.