 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Entity Disambiguation with Per-Mention Learning
Paper and Code
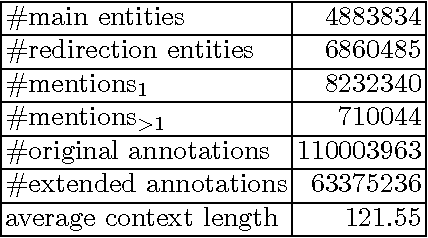
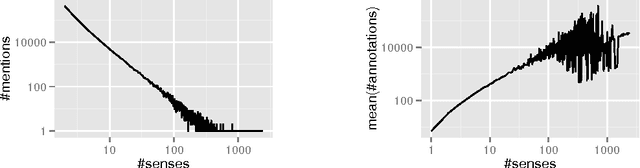
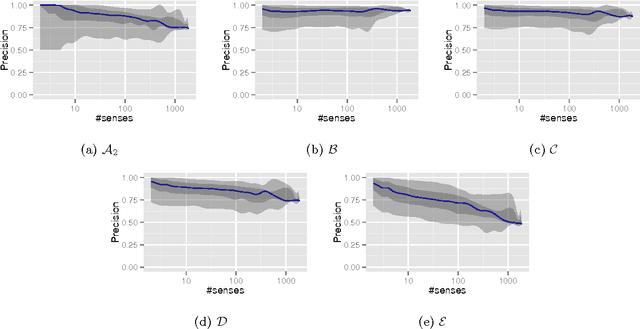
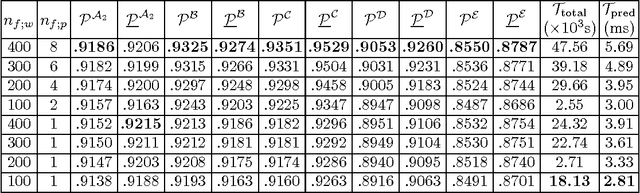
Entity disambiguation, or mapping a phrase to its canonical representation in a knowledge base, is a fundamental step in many natural language processing applications. Existing techniques based on global ranking models fail to capture the individual peculiarities of the words and hence, either struggle to meet the accuracy requirements of many real-world applications or they are too complex to satisfy real-time constraints of applications. In this paper, we propose a new disambiguation system that learns specialized features and models for disambiguating each ambiguous phrase in the English language. To train and validate the hundreds of thousands of learning models for this purpose, we use a Wikipedia hyperlink dataset with more than 170 million labelled annotations. We provide an extensive experimental evaluation to show that the accuracy of our approach compares favourably with respect to many state-of-the-art disambiguation systems. The training required for our approach can be easily distributed over a cluster. Furthermore, updating our system for new entities or calibrating it for special ones is a computationally fast process, that does not affect the disambiguation of the other entities.