 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStory Disambiguation: Tracking Evolving News Stories across News and Social Streams
Aug 16, 2018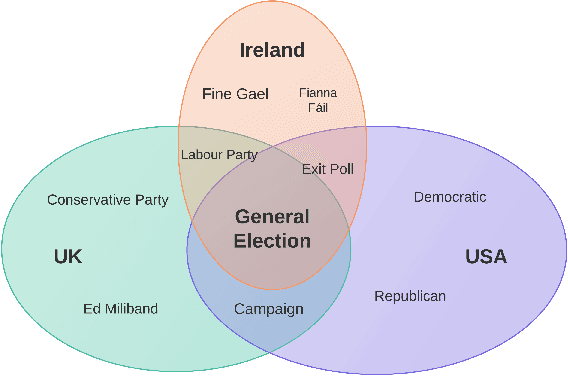
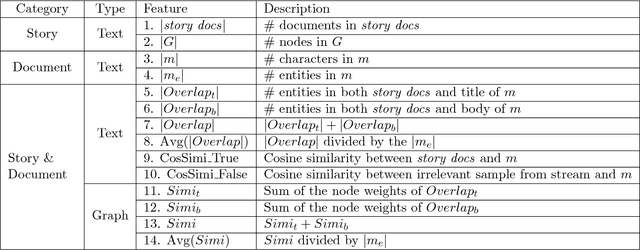
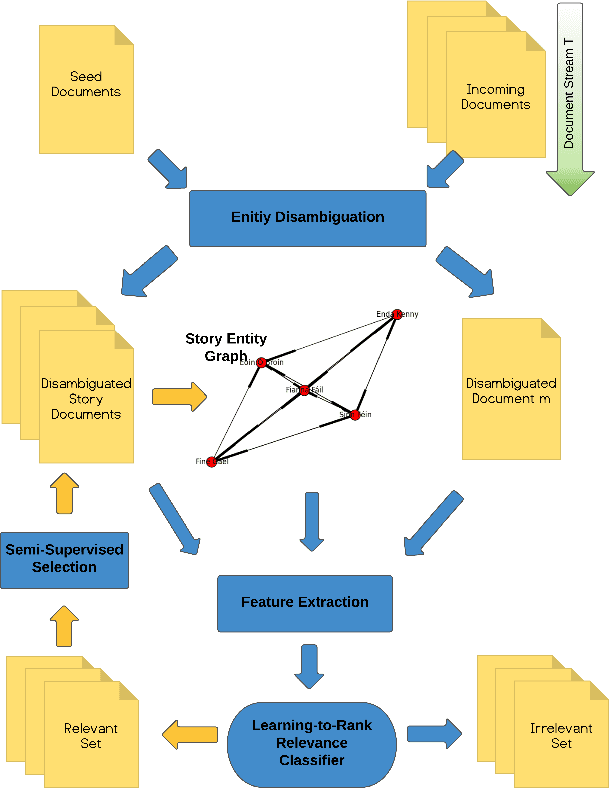
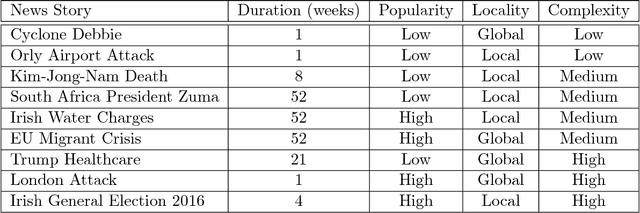
Following a particular news story online is an important but difficult task, as the relevant information is often scattered across different domains/sources (e.g., news articles, blogs, comments, tweets), presented in various formats and language styles, and may overlap with thousands of other stories. In this work we join the areas of topic tracking and entity disambiguation, and propose a framework named Story Disambiguation - a cross-domain story tracking approach that builds on real-time entity disambiguation and a learning-to-rank framework to represent and update the rich semantic structure of news stories. Given a target news story, specified by a seed set of documents, the goal is to effectively select new story-relevant documents from an incoming document stream. We represent stories as entity graphs and we model the story tracking problem as a learning-to-rank task. This enables us to track content with high accuracy, from multiple domains, in real-time. We study a range of text, entity and graph based features to understand which type of features are most effective for representing stories. We further propose new semi-supervised learning techniques to automatically update the story representation over time. Our empirical study shows that we outperform the accuracy of state-of-the-art methods for tracking mixed-domain document streams, while requiring fewer labeled data to seed the tracked stories. This is particularly the case for local news stories that are easily over shadowed by other trending stories, and for complex news stories with ambiguous content in noisy stream environments.
Distributed Entity Disambiguation with Per-Mention Learning
Apr 20, 2016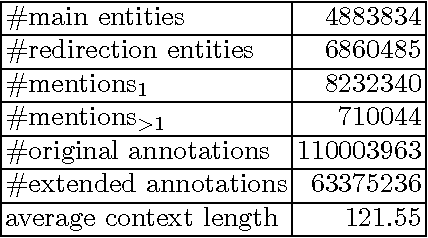
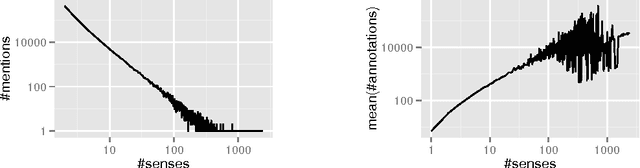
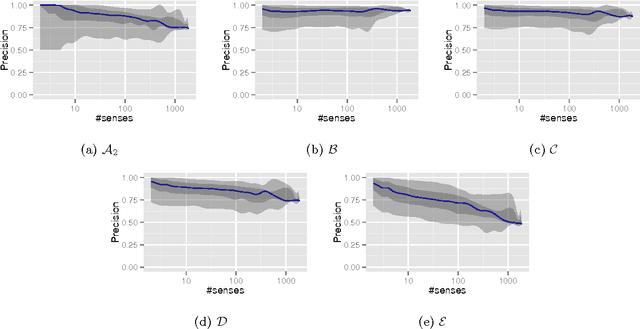
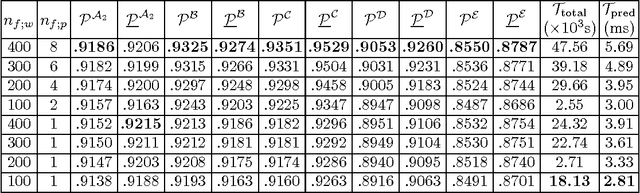
Entity disambiguation, or mapping a phrase to its canonical representation in a knowledge base, is a fundamental step in many natural language processing applications. Existing techniques based on global ranking models fail to capture the individual peculiarities of the words and hence, either struggle to meet the accuracy requirements of many real-world applications or they are too complex to satisfy real-time constraints of applications. In this paper, we propose a new disambiguation system that learns specialized features and models for disambiguating each ambiguous phrase in the English language. To train and validate the hundreds of thousands of learning models for this purpose, we use a Wikipedia hyperlink dataset with more than 170 million labelled annotations. We provide an extensive experimental evaluation to show that the accuracy of our approach compares favourably with respect to many state-of-the-art disambiguation systems. The training required for our approach can be easily distributed over a cluster. Furthermore, updating our system for new entities or calibrating it for special ones is a computationally fast process, that does not affect the disambiguation of the other entities.
A Machine Learning Approach to Predicting the Smoothed Complexity of Sorting Algorithms
Mar 23, 2015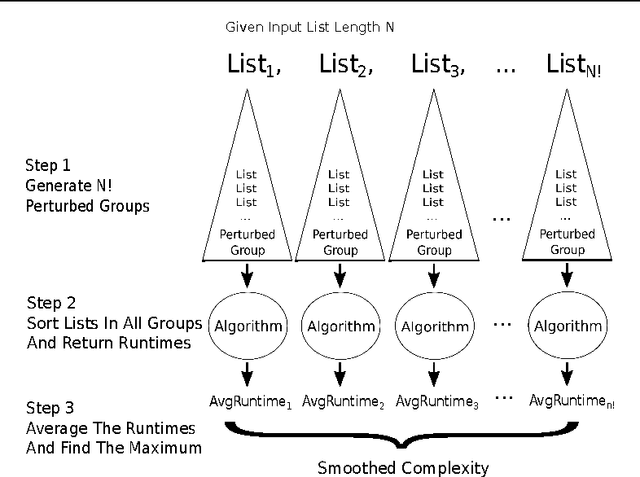
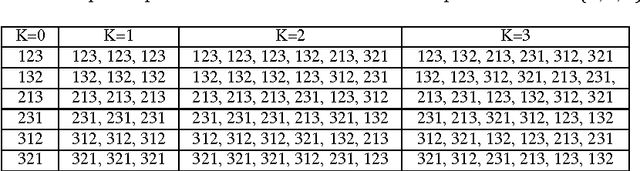

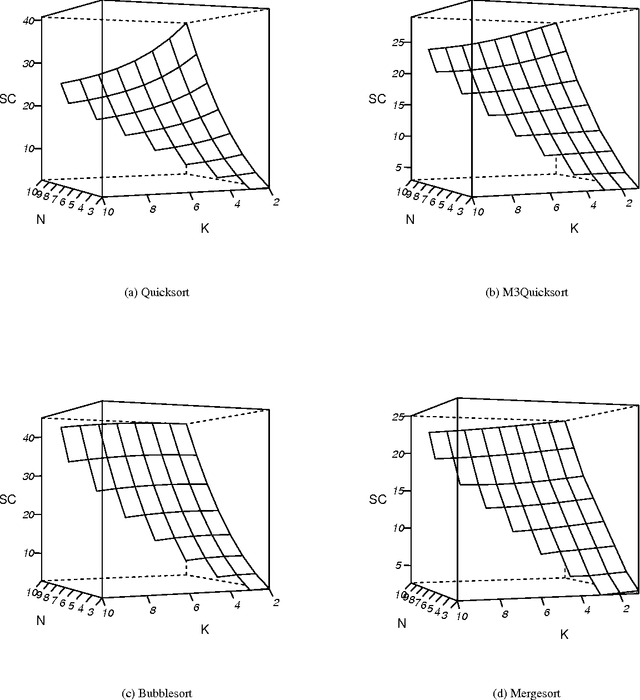
Smoothed analysis is a framework for analyzing the complexity of an algorithm, acting as a bridge between average and worst-case behaviour. For example, Quicksort and the Simplex algorithm are widely used in practical applications, despite their heavy worst-case complexity. Smoothed complexity aims to better characterize such algorithms. Existing theoretical bounds for the smoothed complexity of sorting algorithms are still quite weak. Furthermore, empirically computing the smoothed complexity via its original definition is computationally infeasible, even for modest input sizes. In this paper, we focus on accurately predicting the smoothed complexity of sorting algorithms, using machine learning techniques. We propose two regression models that take into account various properties of sorting algorithms and some of the known theoretical results in smoothed analysis to improve prediction quality. We show experimental results for predicting the smoothed complexity of Quicksort, Mergesort, and optimized Bubblesort for large input sizes, therefore filling the gap between known theoretical and empirical results.