 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStory Disambiguation: Tracking Evolving News Stories across News and Social Streams
Aug 16, 2018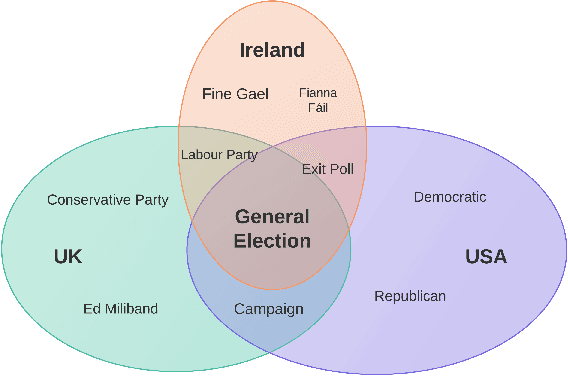
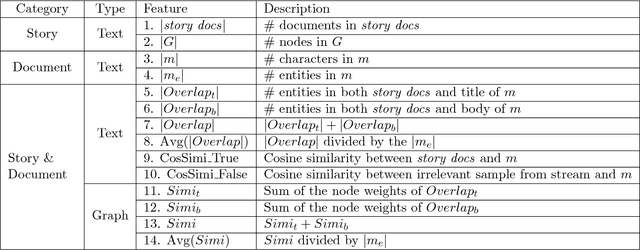
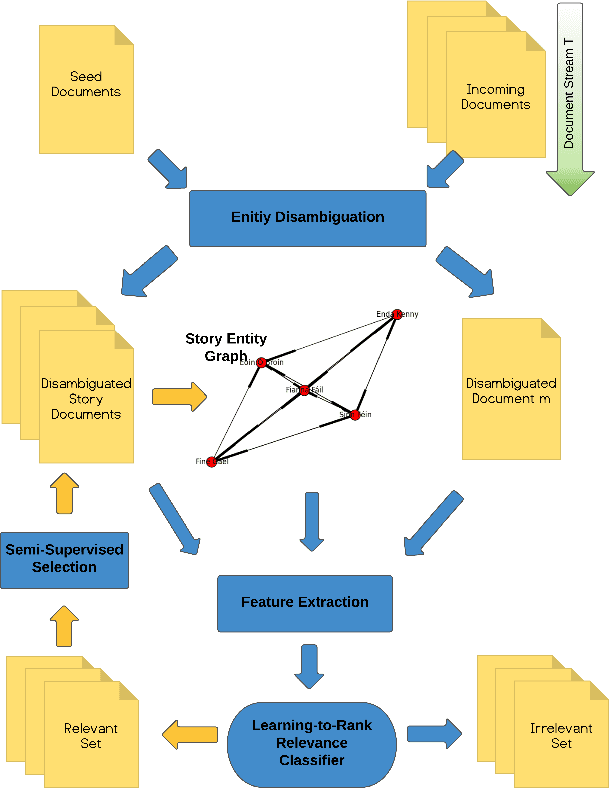
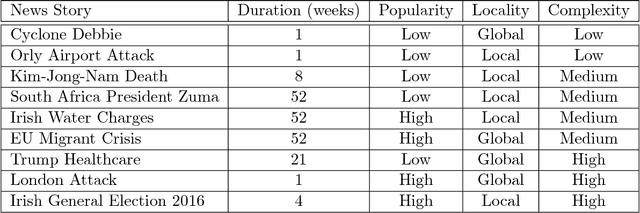
Following a particular news story online is an important but difficult task, as the relevant information is often scattered across different domains/sources (e.g., news articles, blogs, comments, tweets), presented in various formats and language styles, and may overlap with thousands of other stories. In this work we join the areas of topic tracking and entity disambiguation, and propose a framework named Story Disambiguation - a cross-domain story tracking approach that builds on real-time entity disambiguation and a learning-to-rank framework to represent and update the rich semantic structure of news stories. Given a target news story, specified by a seed set of documents, the goal is to effectively select new story-relevant documents from an incoming document stream. We represent stories as entity graphs and we model the story tracking problem as a learning-to-rank task. This enables us to track content with high accuracy, from multiple domains, in real-time. We study a range of text, entity and graph based features to understand which type of features are most effective for representing stories. We further propose new semi-supervised learning techniques to automatically update the story representation over time. Our empirical study shows that we outperform the accuracy of state-of-the-art methods for tracking mixed-domain document streams, while requiring fewer labeled data to seed the tracked stories. This is particularly the case for local news stories that are easily over shadowed by other trending stories, and for complex news stories with ambiguous content in noisy stream environments.