 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers4NewsRec: A Transformer-based News Recommendation Framework
Oct 17, 2024



Pre-trained transformer models have shown great promise in various natural language processing tasks, including personalized news recommendations. To harness the power of these models, we introduce Transformers4NewsRec, a new Python framework built on the \textbf{Transformers} library. This framework is designed to unify and compare the performance of various news recommendation models, including deep neural networks and graph-based models. Transformers4NewsRec offers flexibility in terms of model selection, data preprocessing, and evaluation, allowing both quantitative and qualitative analysis.
Pure Spectral Graph Embeddings: Reinterpreting Graph Convolution for Top-N Recommendation
May 28, 2023The use of graph convolution in the development of recommender system algorithms has recently achieved state-of-the-art results in the collaborative filtering task (CF). While it has been demonstrated that the graph convolution operation is connected to a filtering operation on the graph spectral domain, the theoretical rationale for why this leads to higher performance on the collaborative filtering problem remains unknown. The presented work makes two contributions. First, we investigate the effect of using graph convolution throughout the user and item representation learning processes, demonstrating how the latent features learned are pushed from the filtering operation into the subspace spanned by the eigenvectors associated with the highest eigenvalues of the normalised adjacency matrix, and how vectors lying on this subspace are the optimal solutions for an objective function related to the sum of the prediction function over the training data. Then, we present an approach that directly leverages the eigenvectors to emulate the solution obtained through graph convolution, eliminating the requirement for a time-consuming gradient descent training procedure while also delivering higher performance on three real-world datasets.
Item Graph Convolution Collaborative Filtering for Inductive Recommendations
Mar 28, 2023Graph Convolutional Networks (GCN) have been recently employed as core component in the construction of recommender system algorithms, interpreting user-item interactions as the edges of a bipartite graph. However, in the absence of side information, the majority of existing models adopt an approach of randomly initialising the user embeddings and optimising them throughout the training process. This strategy makes these algorithms inherently transductive, curtailing their ability to generate predictions for users that were unseen at training time. To address this issue, we propose a convolution-based algorithm, which is inductive from the user perspective, while at the same time, depending only on implicit user-item interaction data. We propose the construction of an item-item graph through a weighted projection of the bipartite interaction network and to employ convolution to inject higher order associations into item embeddings, while constructing user representations as weighted sums of the items with which they have interacted. Despite not training individual embeddings for each user our approach achieves state of-the-art recommendation performance with respect to transductive baselines on four real-world datasets, showing at the same time robust inductive performance.
Bayesian Hierarchical Mixture Clustering using Multilevel Hierarchical Dirichlet Processes
Jun 05, 2019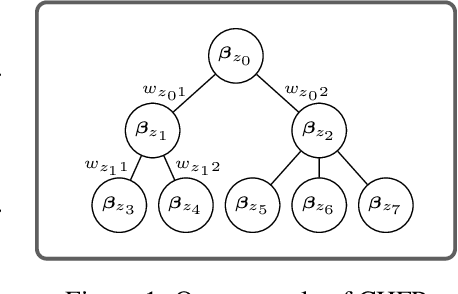


This paper focuses on the problem of hierarchical non-overlapping clustering of a dataset. In such a clustering, each data item is associated with exactly one leaf node and each internal node is associated with all the data items stored in the sub-tree beneath it, so that each level of the hierarchy corresponds to a partition of the dataset. We develop a novel Bayesian nonparametric method combining the nested Chinese Restaurant Process (nCRP) and the Hierarchical Dirichlet Process (HDP). Compared with other existing Bayesian approaches, our solution tackles data with complex latent mixture features which has not been previously explored in the literature. We discuss the details of the model and the inference procedure. Furthermore, experiments on three datasets show that our method achieves solid empirical results in comparison with existing algorithms.
Story Disambiguation: Tracking Evolving News Stories across News and Social Streams
Aug 16, 2018
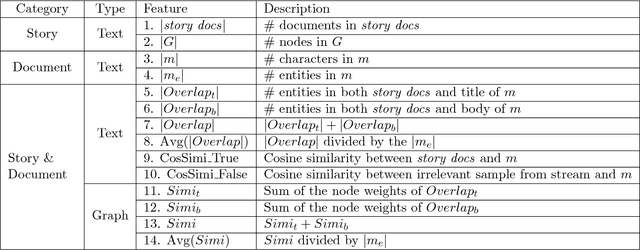
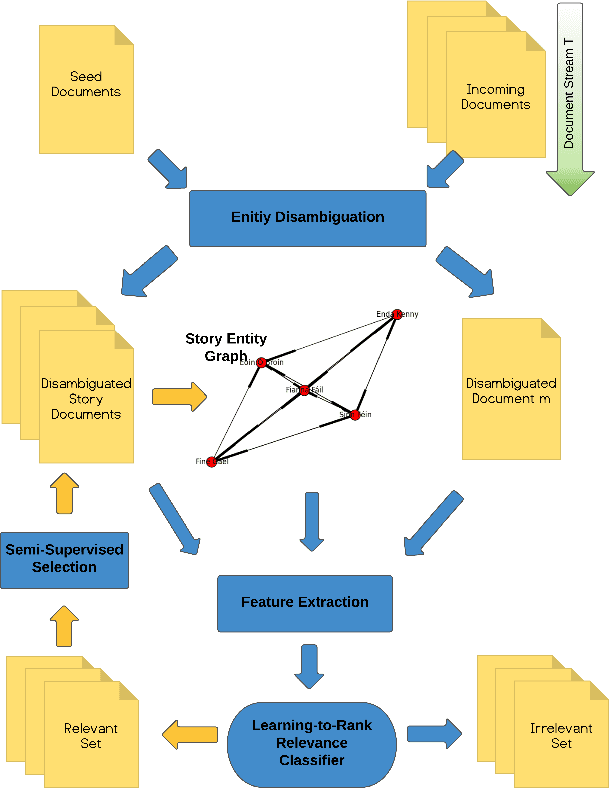
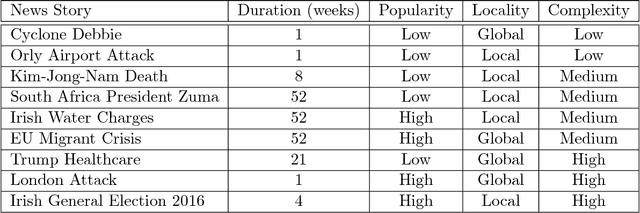
Following a particular news story online is an important but difficult task, as the relevant information is often scattered across different domains/sources (e.g., news articles, blogs, comments, tweets), presented in various formats and language styles, and may overlap with thousands of other stories. In this work we join the areas of topic tracking and entity disambiguation, and propose a framework named Story Disambiguation - a cross-domain story tracking approach that builds on real-time entity disambiguation and a learning-to-rank framework to represent and update the rich semantic structure of news stories. Given a target news story, specified by a seed set of documents, the goal is to effectively select new story-relevant documents from an incoming document stream. We represent stories as entity graphs and we model the story tracking problem as a learning-to-rank task. This enables us to track content with high accuracy, from multiple domains, in real-time. We study a range of text, entity and graph based features to understand which type of features are most effective for representing stories. We further propose new semi-supervised learning techniques to automatically update the story representation over time. Our empirical study shows that we outperform the accuracy of state-of-the-art methods for tracking mixed-domain document streams, while requiring fewer labeled data to seed the tracked stories. This is particularly the case for local news stories that are easily over shadowed by other trending stories, and for complex news stories with ambiguous content in noisy stream environments.