 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNICE: CVPR 2023 Challenge on Zero-shot Image Captioning
Sep 11, 2023



In this report, we introduce NICE (New frontiers for zero-shot Image Captioning Evaluation) project and share the results and outcomes of 2023 challenge. This project is designed to challenge the computer vision community to develop robust image captioning models that advance the state-of-the-art both in terms of accuracy and fairness. Through the challenge, the image captioning models were tested using a new evaluation dataset that includes a large variety of visual concepts from many domains. There was no specific training data provided for the challenge, and therefore the challenge entries were required to adapt to new types of image descriptions that had not been seen during training. This report includes information on the newly proposed NICE dataset, evaluation methods, challenge results, and technical details of top-ranking entries. We expect that the outcomes of the challenge will contribute to the improvement of AI models on various vision-language tasks.
Large-Scale Bidirectional Training for Zero-Shot Image Captioning
Nov 15, 2022
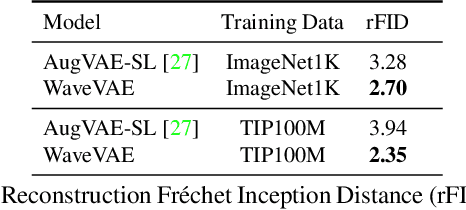
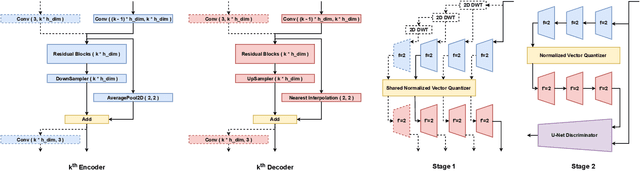
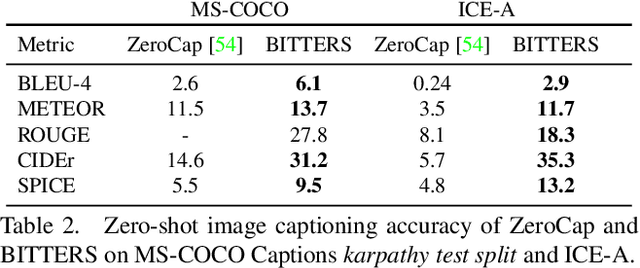
When trained on large-scale datasets, image captioning models can understand the content of images from a general domain but often fail to generate accurate, detailed captions. To improve performance, pretraining-and-finetuning has been a key strategy for image captioning. However, we find that large-scale bidirectional training between image and text enables zero-shot image captioning. In this paper, we introduce Bidirectional Image Text Training in largER Scale, BITTERS, an efficient training and inference framework for zero-shot image captioning. We also propose a new evaluation benchmark which comprises of high quality datasets and an extensive set of metrics to properly evaluate zero-shot captioning accuracy and societal bias. We additionally provide an efficient finetuning approach for keyword extraction. We show that careful selection of large-scale training set and model architecture is the key to achieving zero-shot image captioning.
Can you recommend content to creatives instead of final consumers? A RecSys based on user's preferred visual styles
Aug 23, 2022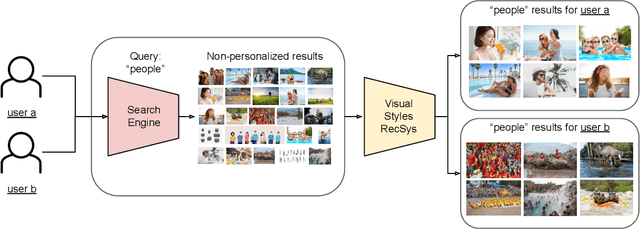


Providing meaningful recommendations in a content marketplace is challenging due to the fact that users are not the final content consumers. Instead, most users are creatives whose interests, linked to the projects they work on, change rapidly and abruptly. To address the challenging task of recommending images to content creators, we design a RecSys that learns visual styles preferences transversal to the semantics of the projects users work on. We analyze the challenges of the task compared to content-based recommendations driven by semantics, propose an evaluation setup, and explain its applications in a global image marketplace. This technical report is an extension of the paper "Learning Users' Preferred Visual Styles in an Image Marketplace", presented at ACM RecSys '22.
Towards Quantifying the Distance between Opinions
Jan 27, 2020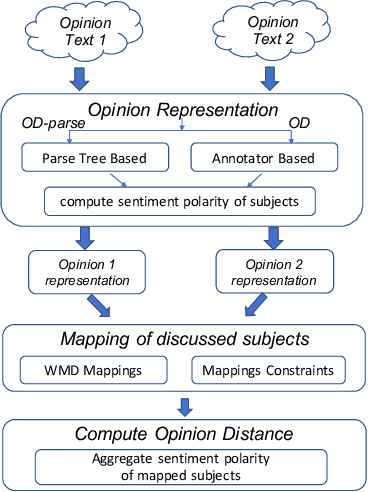


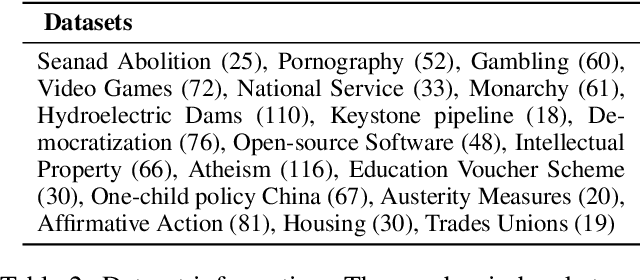
Increasingly, critical decisions in public policy, governance, and business strategy rely on a deeper understanding of the needs and opinions of constituent members (e.g. citizens, shareholders). While it has become easier to collect a large number of opinions on a topic, there is a necessity for automated tools to help navigate the space of opinions. In such contexts understanding and quantifying the similarity between opinions is key. We find that measures based solely on text similarity or on overall sentiment often fail to effectively capture the distance between opinions. Thus, we propose a new distance measure for capturing the similarity between opinions that leverages the nuanced observation -- similar opinions express similar sentiment polarity on specific relevant entities-of-interest. Specifically, in an unsupervised setting, our distance measure achieves significantly better Adjusted Rand Index scores (up to 56x) and Silhouette coefficients (up to 21x) compared to existing approaches. Similarly, in a supervised setting, our opinion distance measure achieves considerably better accuracy (up to 20% increase) compared to extant approaches that rely on text similarity, stance similarity, and sentiment similarity
Distributed Entity Disambiguation with Per-Mention Learning
Apr 20, 2016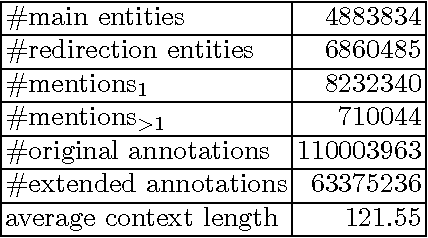
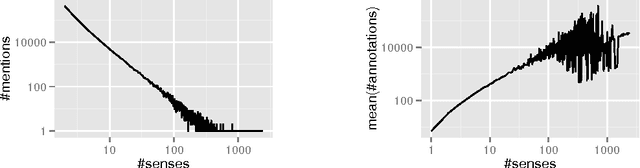
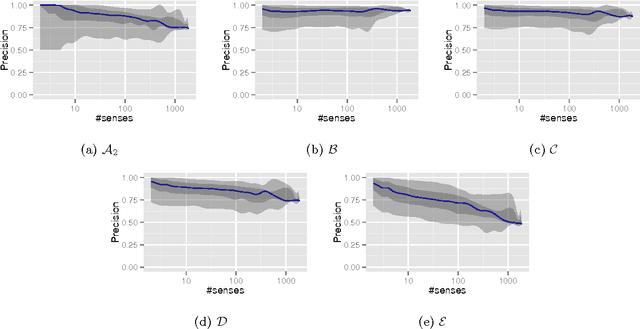
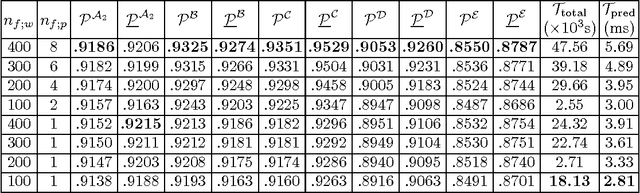
Entity disambiguation, or mapping a phrase to its canonical representation in a knowledge base, is a fundamental step in many natural language processing applications. Existing techniques based on global ranking models fail to capture the individual peculiarities of the words and hence, either struggle to meet the accuracy requirements of many real-world applications or they are too complex to satisfy real-time constraints of applications. In this paper, we propose a new disambiguation system that learns specialized features and models for disambiguating each ambiguous phrase in the English language. To train and validate the hundreds of thousands of learning models for this purpose, we use a Wikipedia hyperlink dataset with more than 170 million labelled annotations. We provide an extensive experimental evaluation to show that the accuracy of our approach compares favourably with respect to many state-of-the-art disambiguation systems. The training required for our approach can be easily distributed over a cluster. Furthermore, updating our system for new entities or calibrating it for special ones is a computationally fast process, that does not affect the disambiguation of the other entities.