 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMINDGAMES: A Live Arena for Evaluating Social and Strategic Reasoning in Multi-Agent LLMs
May 28, 2026Large language models (LLMs) are increasingly deployed as interactive agents, yet their capacity for social and strategic reasoning over extended interaction remains poorly understood. Existing evaluations rely on static vignettes or single-game benchmarks that cannot capture the sustained, multi-faceted reasoning that real-world multi-agent settings demand. We introduce Mindgames, a multi-game arena and evaluation platform for LLM agents that operationalizes complementary reasoning demands relevant to ``theory of mind'': belief attribution under hidden information, opponent modeling through repeated strategic interaction, cooperative inference under knowledge asymmetries, and sustained deception in social deduction. Built on TextArena, Mindgames provides a unified interaction interface, TrueSkill-based rating, and full trajectory logging across four game environments. We instantiate Mindgames through a 2025 competition cycle hosted at a major AI conference, which assessed 944 submitted agents from 76 teams across four games: Colonel Blotto, Iterated Prisoner's Dilemma, Codenames, and Secret Mafia. Our analysis surfaces both agent-level and evaluation-level limitations: brittle rule adherence remains a major bottleneck, top-performing systems repeatedly rely on explicit structural scaffolding, and leaderboard validity differs sharply across environments. In particular, failure-heavy environments can reward robustness to opponent errors as much as strategic ability, with Secret Mafia exhibiting a pronounced error-survival confound in this cycle. We release a dataset of 29,571 multi-agent games with turn-level observations, actions, and rewards, together with MG-Ref, a deterministic offline tournament protocol that scores new agents against a frozen reference pool of top-ranked, low-error Stage~II submissions under the same error-attribution lens used in this analysis.
D$^{2}$-VPR: A Parameter-efficient Visual-foundation-model-based Visual Place Recognition Method via Knowledge Distillation and Deformable Aggregation
Nov 16, 2025Visual Place Recognition (VPR) aims to determine the geographic location of a query image by retrieving its most visually similar counterpart from a geo-tagged reference database. Recently, the emergence of the powerful visual foundation model, DINOv2, trained in a self-supervised manner on massive datasets, has significantly improved VPR performance. This improvement stems from DINOv2's exceptional feature generalization capabilities but is often accompanied by increased model complexity and computational overhead that impede deployment on resource-constrained devices. To address this challenge, we propose $D^{2}$-VPR, a $D$istillation- and $D$eformable-based framework that retains the strong feature extraction capabilities of visual foundation models while significantly reducing model parameters and achieving a more favorable performance-efficiency trade-off. Specifically, first, we employ a two-stage training strategy that integrates knowledge distillation and fine-tuning. Additionally, we introduce a Distillation Recovery Module (DRM) to better align the feature spaces between the teacher and student models, thereby minimizing knowledge transfer losses to the greatest extent possible. Second, we design a Top-Down-attention-based Deformable Aggregator (TDDA) that leverages global semantic features to dynamically and adaptively adjust the Regions of Interest (ROI) used for aggregation, thereby improving adaptability to irregular structures. Extensive experiments demonstrate that our method achieves competitive performance compared to state-of-the-art approaches. Meanwhile, it reduces the parameter count by approximately 64.2% and FLOPs by about 62.6% (compared to CricaVPR).Code is available at https://github.com/tony19980810/D2VPR.
Feel the Difference? A Comparative Analysis of Emotional Arcs in Real and LLM-Generated CBT Sessions
Aug 28, 2025Synthetic therapy dialogues generated by large language models (LLMs) are increasingly used in mental health NLP to simulate counseling scenarios, train models, and supplement limited real-world data. However, it remains unclear whether these synthetic conversations capture the nuanced emotional dynamics of real therapy. In this work, we conduct the first comparative analysis of emotional arcs between real and LLM-generated Cognitive Behavioral Therapy dialogues. We adapt the Utterance Emotion Dynamics framework to analyze fine-grained affective trajectories across valence, arousal, and dominance dimensions. Our analysis spans both full dialogues and individual speaker roles (counselor and client), using real sessions transcribed from public videos and synthetic dialogues from the CACTUS dataset. We find that while synthetic dialogues are fluent and structurally coherent, they diverge from real conversations in key emotional properties: real sessions exhibit greater emotional variability,more emotion-laden language, and more authentic patterns of reactivity and regulation. Moreover, emotional arc similarity between real and synthetic speakers is low, especially for clients. These findings underscore the limitations of current LLM-generated therapy data and highlight the importance of emotional fidelity in mental health applications. We introduce RealCBT, a curated dataset of real CBT sessions, to support future research in this space.
A Unified RCS Modeling of Typical Targets for 3GPP ISAC Channel Standardization and Experimental Analysis
May 27, 2025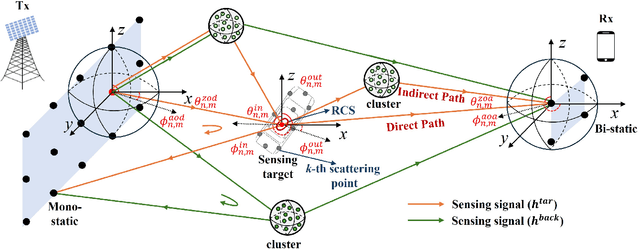
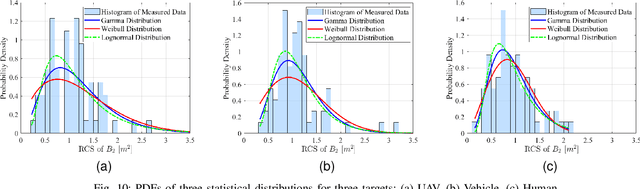
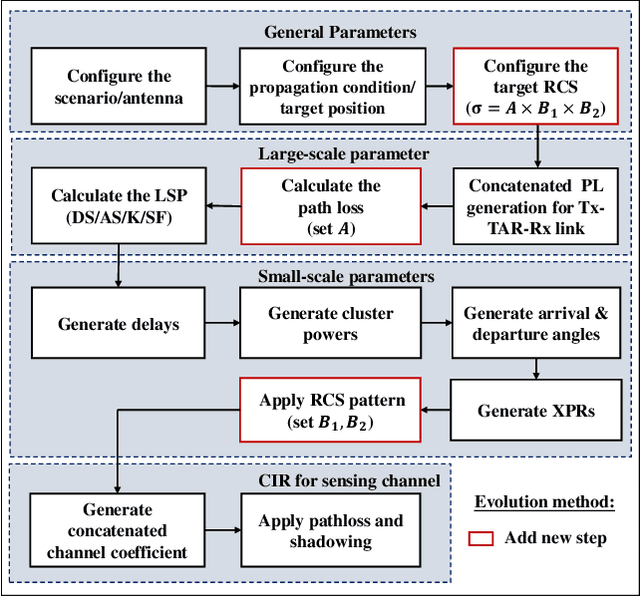
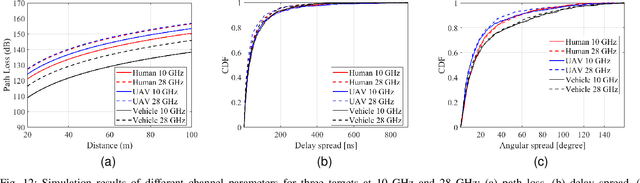
Accurate radar cross section (RCS) modeling is crucial for characterizing target scattering and improving the precision of Integrated Sensing and Communication (ISAC) channel modeling. Existing RCS models are typically designed for specific target types, leading to increased complexity and lack of generalization. This makes it difficult to standardize RCS models for 3GPP ISAC channels, which need to account for multiple typical target types simultaneously. Furthermore, 3GPP models must support both system-level and link-level simulations, requiring the integration of large-scale and small-scale scattering characteristics. To address these challenges, this paper proposes a unified RCS modeling framework that consolidates these two aspects. The model decomposes RCS into three components: (1) a large-scale power factor representing overall scattering strength, (2) a small-scale angular-dependent component describing directional scattering, and (3) a random component accounting for variations across target instances. We validate the model through mono-static RCS measurements for UAV, human, and vehicle targets across five frequency bands. The results demonstrate that the proposed model can effectively capture RCS variations for different target types. Finally, the model is incorporated into an ISAC channel simulation platform to assess the impact of target RCS characteristics on path loss, delay spread, and angular spread, providing valuable insights for future ISAC system design.
Research and Experimental Validation for 3GPP ISAC Channel Modeling Standardization
Apr 14, 2025Integrated Sensing and Communication (ISAC) is considered a key technology in 6G networks. An accurate sensing channel model is crucial for the design and sensing performance evaluation of ISAC systems. The widely used Geometry-Based Stochastic Model (GBSM), typically applied in standardized channel modeling, mainly focuses on the statistical fading characteristics of the channel. However, it fails to capture the characteristics of targets in ISAC systems, such as their positions and velocities, as well as the impact of the targets on the background. To address this issue, this paper proposes an extended GBSM (E-GBSM) sensing channel model that incorporates newly discovered channel characteristics into a unified modeling framework. In this framework, the sensing channel is divided into target and background channels. For the target channel, the model introduces a concatenated modeling approach, while for the background channel, a parameter called the power control factor is introduced to assess impact of the target on the background channel, making the modeling framework applicable to both mono-static and bi-static sensing modes. To validate the proposed model's effectiveness, measurements of target and background channels are conducted in both indoor and outdoor scenarios, covering various sensing targets such as metal plates, reconfigurable intelligent surfaces, human bodies, UAVs, and vehicles. The experimental results provide important theoretical support and empirical data for the standardization of ISAC channel modeling.
InpDiffusion: Image Inpainting Localization via Conditional Diffusion Models
Jan 06, 2025
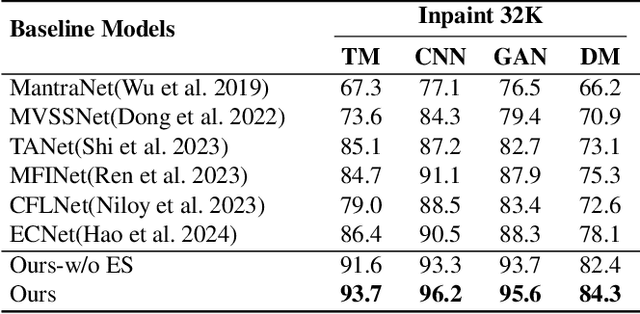


As artificial intelligence advances rapidly, particularly with the advent of GANs and diffusion models, the accuracy of Image Inpainting Localization (IIL) has become increasingly challenging. Current IIL methods face two main challenges: a tendency towards overconfidence, leading to incorrect predictions; and difficulty in detecting subtle tampering boundaries in inpainted images. In response, we propose a new paradigm that treats IIL as a conditional mask generation task utilizing diffusion models. Our method, InpDiffusion, utilizes the denoising process enhanced by the integration of image semantic conditions to progressively refine predictions. During denoising, we employ edge conditions and introduce a novel edge supervision strategy to enhance the model's perception of edge details in inpainted objects. Balancing the diffusion model's stochastic sampling with edge supervision of tampered image regions mitigates the risk of incorrect predictions from overconfidence and prevents the loss of subtle boundaries that can result from overly stochastic processes. Furthermore, we propose an innovative Dual-stream Multi-scale Feature Extractor (DMFE) for extracting multi-scale features, enhancing feature representation by considering both semantic and edge conditions of the inpainted images. Extensive experiments across challenging datasets demonstrate that the InpDiffusion significantly outperforms existing state-of-the-art methods in IIL tasks, while also showcasing excellent generalization capabilities and robustness.
Cascaded channel modeling and experimental validation for RIS assisted communication system
Dec 10, 2024



Reconfigurable Intelligent Surface (RIS) is considered as a promising technology for 6G due to its ability to actively modify the electromagnetic propagation environment. Accurate channel modeling is essential for the design and evaluation of RIS assisted communication systems. Most current research models the RIS channel as a cascade of Tx-RIS and RIS-Rx sub-channels. However, most validation efforts regarding this assumption focus on large-scale path loss. To further explore this, in this paper, we derive and extend a convolution expression of RIS cascaded channel model based on the previously proposed Geometry-based Stochastic Model (GBSM)-based RIS cascaded channels. This model follows the 3GPP standard framework and leverages parameters such as angles, delays, and path powers defined in the GBSM model to more accurately reflect the smallscale characteristics of RIS multipath cascades. To verify the accuracy of this model, we conduct measurements of the TxRIS-Rx channel, Tx-RIS, and RIS-Rx sub-channels in a factory environment at 6.9 GHz, using the measured data to demonstrate the models validity and applicability in real-world scenarios. Validation with measured data shows that the proposed model accurately describes the characteristics of the RIS cascaded channel in terms of delay, angle, and power in complex multipath environments, providing important references for the design and deployment of RIS systems.
Learning to Prune Instances of Steiner Tree Problem in Graphs
Aug 25, 2022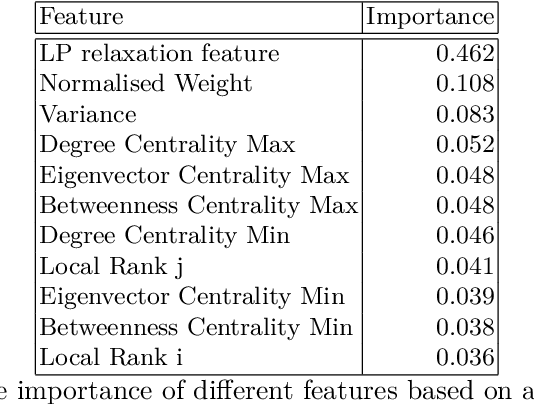
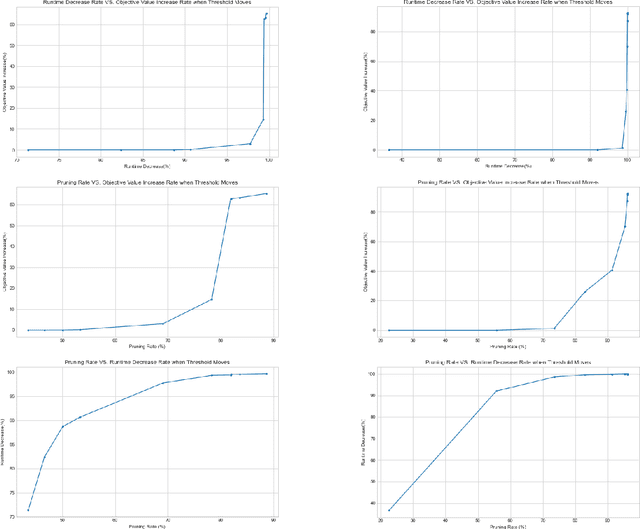
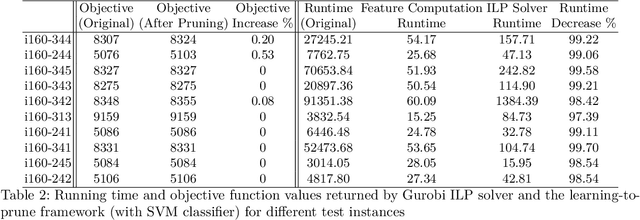
We consider the Steiner tree problem on graphs where we are given a set of nodes and the goal is to find a tree sub-graph of minimum weight that contains all nodes in the given set, potentially including additional nodes. This is a classical NP-hard combinatorial optimisation problem. In recent years, a machine learning framework called learning-to-prune has been successfully used for solving a diverse range of combinatorial optimisation problems. In this paper, we use this learning framework on the Steiner tree problem and show that even on this problem, the learning-to-prune framework results in computing near-optimal solutions at a fraction of the time required by commercial ILP solvers. Our results underscore the potential of the learning-to-prune framework in solving various combinatorial optimisation problems.
Variational Autoencoder with CCA for Audio-Visual Cross-Modal Retrieval
Dec 05, 2021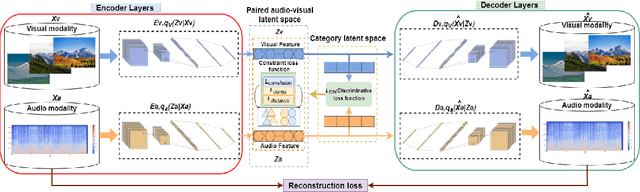


Cross-modal retrieval is to utilize one modality as a query to retrieve data from another modality, which has become a popular topic in information retrieval, machine learning, and database. How to effectively measure the similarity between different modality data is the major challenge of cross-modal retrieval. Although several reasearch works have calculated the correlation between different modality data via learning a common subspace representation, the encoder's ability to extract features from multi-modal information is not satisfactory. In this paper, we present a novel variational autoencoder (VAE) architecture for audio-visual cross-modal retrieval, by learning paired audio-visual correlation embedding and category correlation embedding as constraints to reinforce the mutuality of audio-visual information. On the one hand, audio encoder and visual encoder separately encode audio data and visual data into two different latent spaces. Further, two mutual latent spaces are respectively constructed by canonical correlation analysis (CCA). On the other hand, probabilistic modeling methods is used to deal with possible noise and missing information in the data. Additionally, in this way, the cross-modal discrepancy from intra-modal and inter-modal information are simultaneously eliminated in the joint embedding subspace. We conduct extensive experiments over two benchmark datasets. The experimental outcomes exhibit that the proposed architecture is effective in learning audio-visual correlation and is appreciably better than the existing cross-modal retrieval methods.
DL-AMP and DBTO: An Automatic Merge Planning and Trajectory Optimization and Its Application in Autonomous Driving
Jul 30, 2021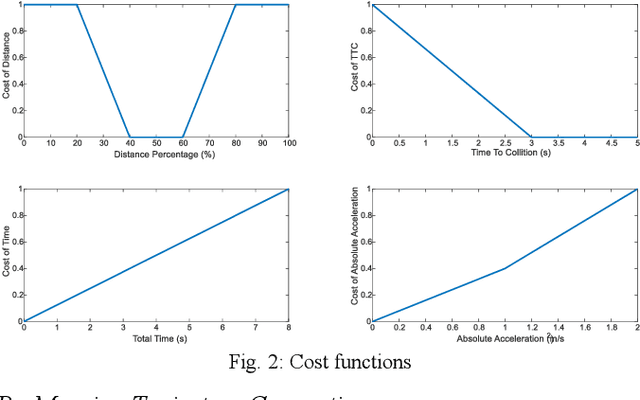
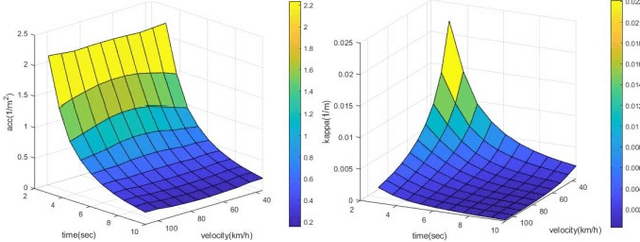

This paper presents an automatic merging algorithm for autonomous driving vehicles, which decouples the specific motion planning problem into a Dual-Layer Automatic Merge Planning (DL_AMP) and a Descent-Based Trajectory Optimization (DBTO). This work leads to great improvements in finding the best merge opportunity, lateral and longitudinal merge planning and control, trajectory postprocessing and driving comfort.