 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrAda-GAN: A Private Adaptive Generative Adversarial Network with Bayes Network Structure
Nov 11, 2025We revisit the problem of generating synthetic data under differential privacy. To address the core limitations of marginal-based methods, we propose the Private Adaptive Generative Adversarial Network with Bayes Network Structure (PrAda-GAN), which integrates the strengths of both GAN-based and marginal-based approaches. Our method adopts a sequential generator architecture to capture complex dependencies among variables, while adaptively regularizing the learned structure to promote sparsity in the underlying Bayes network. Theoretically, we establish diminishing bounds on the parameter distance, variable selection error, and Wasserstein distance. Our analysis shows that leveraging dependency sparsity leads to significant improvements in convergence rates. Empirically, experiments on both synthetic and real-world datasets demonstrate that PrAda-GAN outperforms existing tabular data synthesis methods in terms of the privacy-utility trade-off.
Locally Private Nonparametric Contextual Multi-armed Bandits
Mar 11, 2025Motivated by privacy concerns in sequential decision-making on sensitive data, we address the challenge of nonparametric contextual multi-armed bandits (MAB) under local differential privacy (LDP). We develop a uniform-confidence-bound-type estimator, showing its minimax optimality supported by a matching minimax lower bound. We further consider the case where auxiliary datasets are available, subject also to (possibly heterogeneous) LDP constraints. Under the widely-used covariate shift framework, we propose a jump-start scheme to effectively utilize the auxiliary data, the minimax optimality of which is further established by a matching lower bound. Comprehensive experiments on both synthetic and real-world datasets validate our theoretical results and underscore the effectiveness of the proposed methods.
Better Locally Private Sparse Estimation Given Multiple Samples Per User
Aug 08, 2024



Previous studies yielded discouraging results for item-level locally differentially private linear regression with $s^*$-sparsity assumption, where the minimax rate for $nm$ samples is $\mathcal{O}(s^{*}d / nm\varepsilon^2)$. This can be challenging for high-dimensional data, where the dimension $d$ is extremely large. In this work, we investigate user-level locally differentially private sparse linear regression. We show that with $n$ users each contributing $m$ samples, the linear dependency of dimension $d$ can be eliminated, yielding an error upper bound of $\mathcal{O}(s^{*2} / nm\varepsilon^2)$. We propose a framework that first selects candidate variables and then conducts estimation in the narrowed low-dimensional space, which is extendable to general sparse estimation problems with tight error bounds. Experiments on both synthetic and real datasets demonstrate the superiority of the proposed methods. Both the theoretical and empirical results suggest that, with the same number of samples, locally private sparse estimation is better conducted when multiple samples per user are available.
ALTER: Augmentation for Large-Table-Based Reasoning
Jul 03, 2024



While extensive research has explored the use of large language models (LLMs) for table-based reasoning, most approaches struggle with scalability when applied to large tables. To maintain the superior comprehension abilities of LLMs in these scenarios, we introduce ALTER(Augmentation for Large-Table-Based Reasoning)-a framework designed to harness the latent augmentation potential in both free-form natural language (NL) questions, via the query augmentor, and semi-structured tabular data, through the table augmentor. By utilizing only a small subset of relevant data from the table and supplementing it with pre-augmented schema, semantic, and literal information, ALTER achieves outstanding performance on table-based reasoning benchmarks. We also provide a detailed analysis of large-table scenarios, comparing different methods and various partitioning principles. In these scenarios, our method outperforms all other approaches and exhibits robustness and efficiency against perturbations.
Locally Private Estimation with Public Features
May 22, 2024



We initiate the study of locally differentially private (LDP) learning with public features. We define semi-feature LDP, where some features are publicly available while the remaining ones, along with the label, require protection under local differential privacy. Under semi-feature LDP, we demonstrate that the mini-max convergence rate for non-parametric regression is significantly reduced compared to that of classical LDP. Then we propose HistOfTree, an estimator that fully leverages the information contained in both public and private features. Theoretically, HistOfTree reaches the mini-max optimal convergence rate. Empirically, HistOfTree achieves superior performance on both synthetic and real data. We also explore scenarios where users have the flexibility to select features for protection manually. In such cases, we propose an estimator and a data-driven parameter tuning strategy, leading to analogous theoretical and empirical results.
Bagged Regularized $k$-Distances for Anomaly Detection
Dec 02, 2023We consider the paradigm of unsupervised anomaly detection, which involves the identification of anomalies within a dataset in the absence of labeled examples. Though distance-based methods are top-performing for unsupervised anomaly detection, they suffer heavily from the sensitivity to the choice of the number of the nearest neighbors. In this paper, we propose a new distance-based algorithm called bagged regularized $k$-distances for anomaly detection (BRDAD) converting the unsupervised anomaly detection problem into a convex optimization problem. Our BRDAD algorithm selects the weights by minimizing the surrogate risk, i.e., the finite sample bound of the empirical risk of the bagged weighted $k$-distances for density estimation (BWDDE). This approach enables us to successfully address the sensitivity challenge of the hyperparameter choice in distance-based algorithms. Moreover, when dealing with large-scale datasets, the efficiency issues can be addressed by the incorporated bagging technique in our BRDAD algorithm. On the theoretical side, we establish fast convergence rates of the AUC regret of our algorithm and demonstrate that the bagging technique significantly reduces the computational complexity. On the practical side, we conduct numerical experiments on anomaly detection benchmarks to illustrate the insensitivity of parameter selection of our algorithm compared with other state-of-the-art distance-based methods. Moreover, promising improvements are brought by applying the bagging technique in our algorithm on real-world datasets.
Optimal Locally Private Nonparametric Classification with Public Data
Nov 21, 2023



In this work, we investigate the problem of public data-assisted non-interactive LDP (Local Differential Privacy) learning with a focus on non-parametric classification. Under the posterior drift assumption, we for the first time derive the mini-max optimal convergence rate with LDP constraint. Then, we present a novel approach, the locally private classification tree, which attains the mini-max optimal convergence rate. Furthermore, we design a data-driven pruning procedure that avoids parameter tuning and produces a fast converging estimator. Comprehensive experiments conducted on synthetic and real datasets show the superior performance of our proposed method. Both our theoretical and experimental findings demonstrate the effectiveness of public data compared to private data, which leads to practical suggestions for prioritizing non-private data collection.
Frequency Principle in Deep Learning Beyond Gradient-descent-based Training
Jan 04, 2021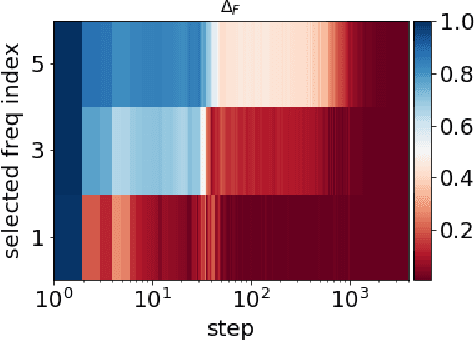
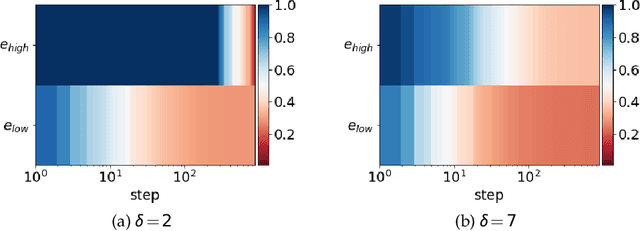
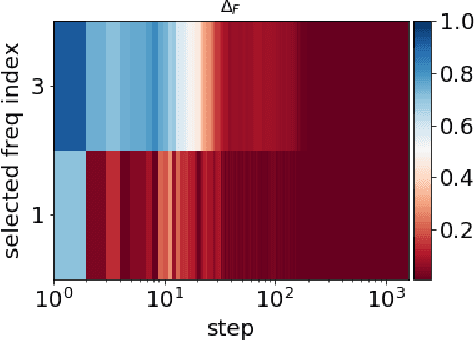
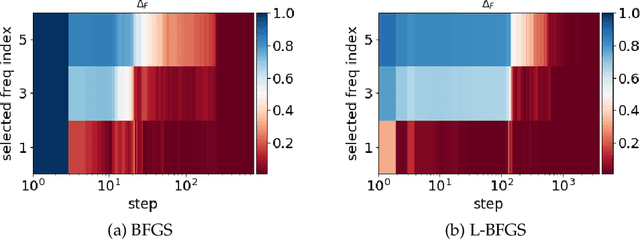
Frequency perspective recently makes progress in understanding deep learning. It has been widely verified in both empirical and theoretical studies that deep neural networks (DNNs) often fit the target function from low to high frequency, namely Frequency Principle (F-Principle). F-Principle sheds light on the strength and the weakness of DNNs and inspires a series of subsequent works, including theoretical studies, empirical studies and the design of efficient DNN structures etc. Previous works examine the F-Principle in gradient-descent-based training. It remains unclear whether gradient-descent-based training is a necessary condition for the F-Principle. In this paper, we show that the F-Principle exists stably in the training process of DNNs with non-gradient-descent-based training, including optimization algorithms with gradient information, such as conjugate gradient and BFGS, and algorithms without gradient information, such as Powell's method and Particle Swarm Optimization. These empirical studies show the universality of the F-Principle and provide hints for further study of F-Principle.