 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocally Private Nonparametric Contextual Multi-armed Bandits
Mar 11, 2025Motivated by privacy concerns in sequential decision-making on sensitive data, we address the challenge of nonparametric contextual multi-armed bandits (MAB) under local differential privacy (LDP). We develop a uniform-confidence-bound-type estimator, showing its minimax optimality supported by a matching minimax lower bound. We further consider the case where auxiliary datasets are available, subject also to (possibly heterogeneous) LDP constraints. Under the widely-used covariate shift framework, we propose a jump-start scheme to effectively utilize the auxiliary data, the minimax optimality of which is further established by a matching lower bound. Comprehensive experiments on both synthetic and real-world datasets validate our theoretical results and underscore the effectiveness of the proposed methods.
Contextual Dynamic Pricing: Algorithms, Optimality, and Local Differential Privacy Constraints
Jun 04, 2024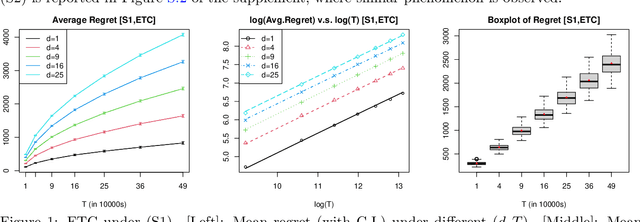
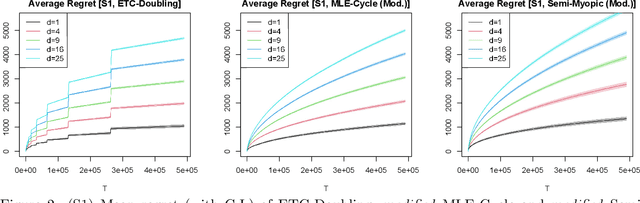
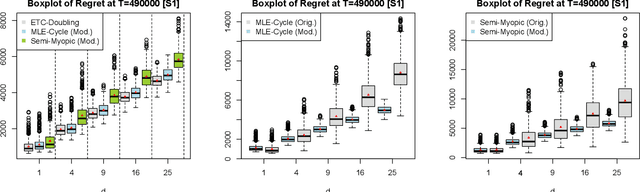
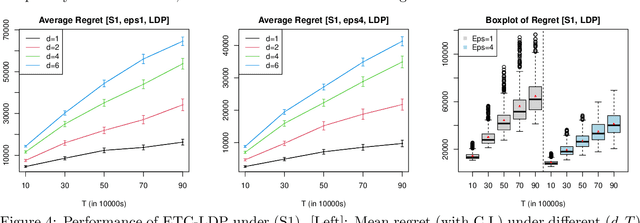
We study the contextual dynamic pricing problem where a firm sells products to $T$ sequentially arriving consumers that behave according to an unknown demand model. The firm aims to maximize its revenue, i.e. minimize its regret over a clairvoyant that knows the model in advance. The demand model is a generalized linear model (GLM), allowing for a stochastic feature vector in $\mathbb R^d$ that encodes product and consumer information. We first show that the optimal regret upper bound is of order $\sqrt{dT}$, up to a logarithmic factor, improving upon existing upper bounds in the literature by a $\sqrt{d}$ factor. This sharper rate is materialised by two algorithms: a confidence bound-type (supCB) algorithm and an explore-then-commit (ETC) algorithm. A key insight of our theoretical result is an intrinsic connection between dynamic pricing and the contextual multi-armed bandit problem with many arms based on a careful discretization. We further study contextual dynamic pricing under the local differential privacy (LDP) constraints. In particular, we propose a stochastic gradient descent based ETC algorithm that achieves an optimal regret upper bound of order $d\sqrt{T}/\epsilon$, up to a logarithmic factor, where $\epsilon>0$ is the privacy parameter. The regret upper bounds with and without LDP constraints are accompanied by newly constructed minimax lower bounds, which further characterize the cost of privacy. Extensive numerical experiments and a real data application on online lending are conducted to illustrate the efficiency and practical value of the proposed algorithms in dynamic pricing.
Probing Deep Speaker Embeddings for Speaker-related Tasks
Dec 14, 2022



Deep speaker embeddings have shown promising results in speaker recognition, as well as in other speaker-related tasks. However, some issues are still under explored, for instance, the information encoded in these representations and their influence on downstream tasks. Four deep speaker embeddings are studied in this paper, namely, d-vector, x-vector, ResNetSE-34 and ECAPA-TDNN. Inspired by human voice mechanisms, we explored possibly encoded information from perspectives of identity, contents and channels; Based on this, experiments were conducted on three categories of speaker-related tasks to further explore impacts of different deep embeddings, including discriminative tasks (speaker verification and diarization), guiding tasks (target speaker detection and extraction) and regulating tasks (multi-speaker text-to-speech). Results show that all deep embeddings encoded channel and content information in addition to speaker identity, but the extent could vary and their performance on speaker-related tasks can be tremendously different: ECAPA-TDNN is dominant in discriminative tasks, and d-vector leads the guiding tasks, while regulating task is less sensitive to the choice of speaker representations. These may benefit future research utilizing speaker embeddings.
Speaker-Aware Mixture of Mixtures Training for Weakly Supervised Speaker Extraction
Apr 15, 2022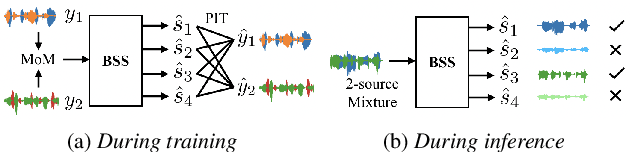

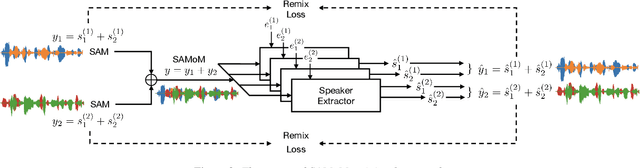
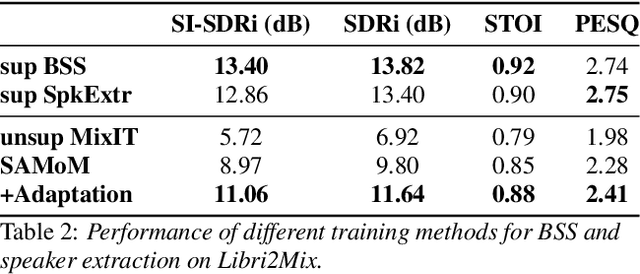
Dominant researches adopt supervised training for speaker extraction, while the scarcity of ideally clean corpus and channel mismatch problem are rarely considered. To this end, we propose speaker-aware mixture of mixtures training (SAMoM), utilizing the consistency of speaker identity among target source, enrollment utterance and target estimate to weakly supervise the training of a deep speaker extractor. In SAMoM, the input is constructed by mixing up different speaker-aware mixtures (SAMs), each contains multiple speakers with their identities known and enrollment utterances available. Informed by enrollment utterances, target speech is extracted from the input one by one, such that the estimated targets can approximate the original SAMs after a remix in accordance with the identity consistency. Moreover, using SAMoM in a semi-supervised setting with a certain amount of clean sources enables application in noisy scenarios. Extensive experiments on Libri2Mix show that the proposed method achieves promising results without access to any clean sources (11.06dB SI-SDRi). With a domain adaptation, our approach even outperformed supervised framework in a cross-domain evaluation on AISHELL-1.
Target Confusion in End-to-end Speaker Extraction: Analysis and Approaches
Apr 04, 2022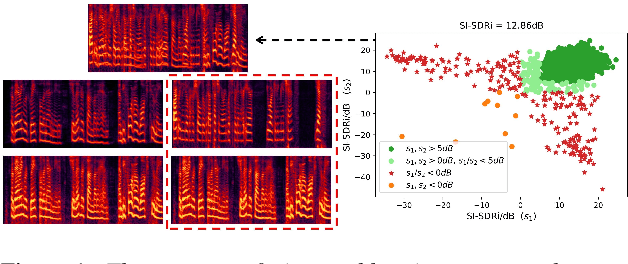
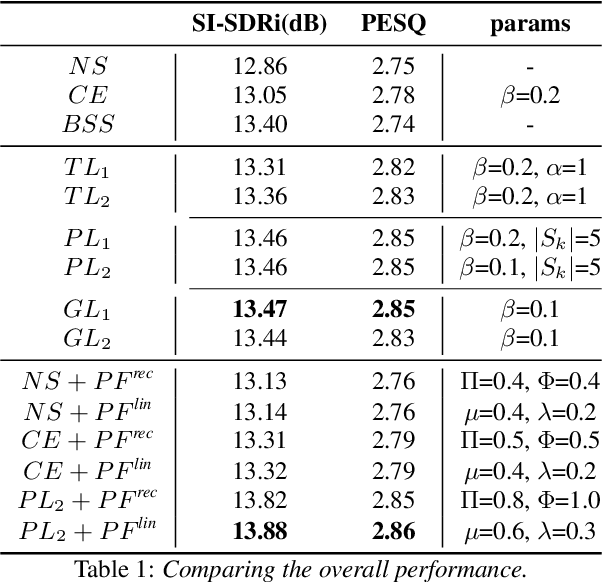


Recently, end-to-end speaker extraction has attracted increasing attention and shown promising results. However, its performance is often inferior to that of a blind source separation (BSS) counterpart with a similar network architecture, due to the auxiliary speaker encoder may sometimes generate ambiguous speaker embeddings. Such ambiguous guidance information may confuse the separation network and hence lead to wrong extraction results, which deteriorates the overall performance. We refer to this as the target confusion problem. In this paper, we conduct an analysis of such an issue and solve it in two stages. In the training phase, we propose to integrate metric learning methods to improve the distinguishability of embeddings produced by the speaker encoder. While for inference, a novel post-filtering strategy is designed to revise the wrong results. Specifically, we first identify these confusion samples by measuring the similarities between output estimates and enrollment utterances, after which the true target sources are recovered by a subtraction operation. Experiments show that performance improvement of more than 1dB SI-SDRi can be brought, which validates the effectiveness of our methods and emphasizes the impact of the target confusion problem.