 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker-Aware Mixture of Mixtures Training for Weakly Supervised Speaker Extraction
Paper and Code
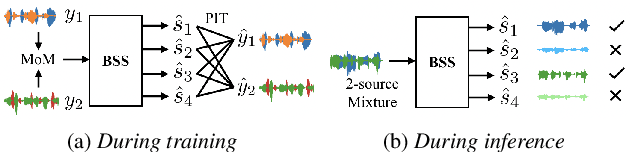

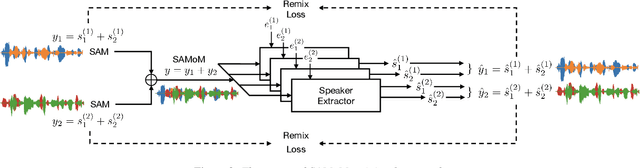
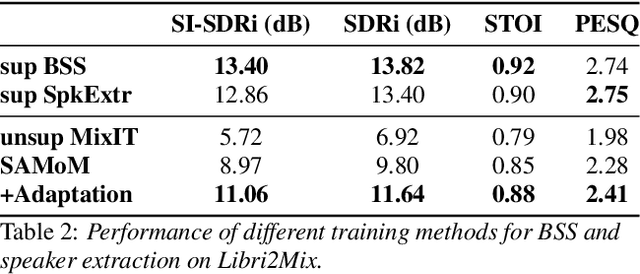
Dominant researches adopt supervised training for speaker extraction, while the scarcity of ideally clean corpus and channel mismatch problem are rarely considered. To this end, we propose speaker-aware mixture of mixtures training (SAMoM), utilizing the consistency of speaker identity among target source, enrollment utterance and target estimate to weakly supervise the training of a deep speaker extractor. In SAMoM, the input is constructed by mixing up different speaker-aware mixtures (SAMs), each contains multiple speakers with their identities known and enrollment utterances available. Informed by enrollment utterances, target speech is extracted from the input one by one, such that the estimated targets can approximate the original SAMs after a remix in accordance with the identity consistency. Moreover, using SAMoM in a semi-supervised setting with a certain amount of clean sources enables application in noisy scenarios. Extensive experiments on Libri2Mix show that the proposed method achieves promising results without access to any clean sources (11.06dB SI-SDRi). With a domain adaptation, our approach even outperformed supervised framework in a cross-domain evaluation on AISHELL-1.