 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBagged Regularized $k$-Distances for Anomaly Detection
Dec 02, 2023We consider the paradigm of unsupervised anomaly detection, which involves the identification of anomalies within a dataset in the absence of labeled examples. Though distance-based methods are top-performing for unsupervised anomaly detection, they suffer heavily from the sensitivity to the choice of the number of the nearest neighbors. In this paper, we propose a new distance-based algorithm called bagged regularized $k$-distances for anomaly detection (BRDAD) converting the unsupervised anomaly detection problem into a convex optimization problem. Our BRDAD algorithm selects the weights by minimizing the surrogate risk, i.e., the finite sample bound of the empirical risk of the bagged weighted $k$-distances for density estimation (BWDDE). This approach enables us to successfully address the sensitivity challenge of the hyperparameter choice in distance-based algorithms. Moreover, when dealing with large-scale datasets, the efficiency issues can be addressed by the incorporated bagging technique in our BRDAD algorithm. On the theoretical side, we establish fast convergence rates of the AUC regret of our algorithm and demonstrate that the bagging technique significantly reduces the computational complexity. On the practical side, we conduct numerical experiments on anomaly detection benchmarks to illustrate the insensitivity of parameter selection of our algorithm compared with other state-of-the-art distance-based methods. Moreover, promising improvements are brought by applying the bagging technique in our algorithm on real-world datasets.
Under-bagging Nearest Neighbors for Imbalanced Classification
Sep 01, 2021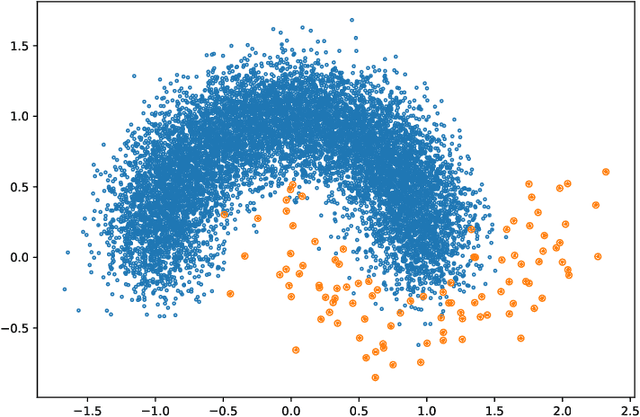
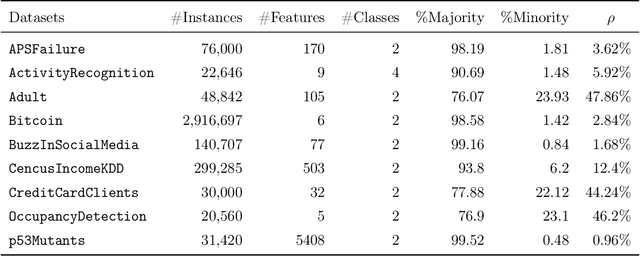
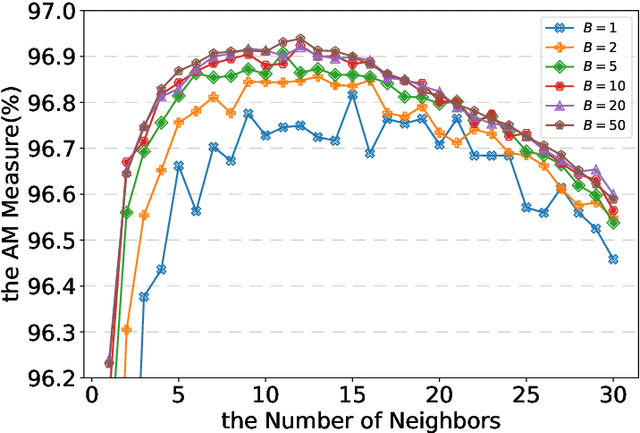
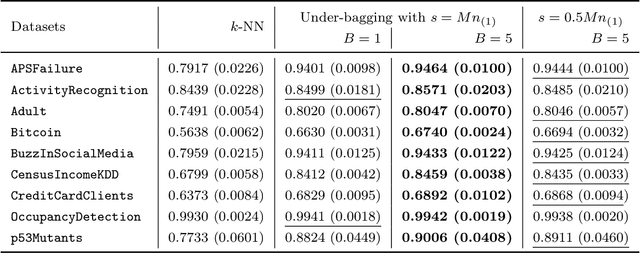
In this paper, we propose an ensemble learning algorithm called \textit{under-bagging $k$-nearest neighbors} (\textit{under-bagging $k$-NN}) for imbalanced classification problems. On the theoretical side, by developing a new learning theory analysis, we show that with properly chosen parameters, i.e., the number of nearest neighbors $k$, the expected sub-sample size $s$, and the bagging rounds $B$, optimal convergence rates for under-bagging $k$-NN can be achieved under mild assumptions w.r.t.~the arithmetic mean (AM) of recalls. Moreover, we show that with a relatively small $B$, the expected sub-sample size $s$ can be much smaller than the number of training data $n$ at each bagging round, and the number of nearest neighbors $k$ can be reduced simultaneously, especially when the data are highly imbalanced, which leads to substantially lower time complexity and roughly the same space complexity. On the practical side, we conduct numerical experiments to verify the theoretical results on the benefits of the under-bagging technique by the promising AM performance and efficiency of our proposed algorithm.
Gradient Boosted Binary Histogram Ensemble for Large-scale Regression
Jun 03, 2021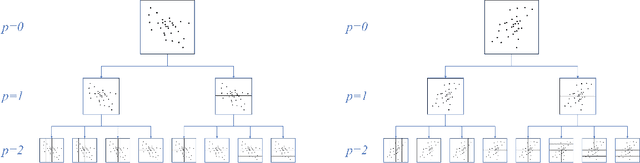
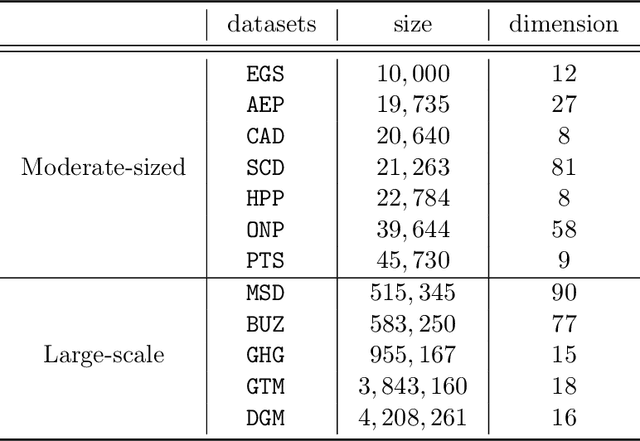
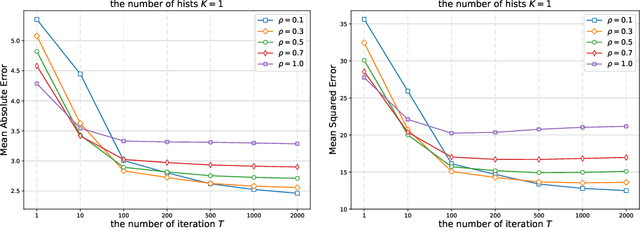
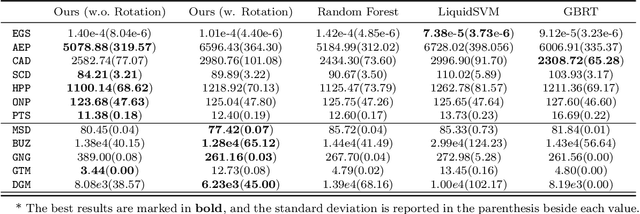
In this paper, we propose a gradient boosting algorithm for large-scale regression problems called \textit{Gradient Boosted Binary Histogram Ensemble} (GBBHE) based on binary histogram partition and ensemble learning. From the theoretical perspective, by assuming the H\"{o}lder continuity of the target function, we establish the statistical convergence rate of GBBHE in the space $C^{0,\alpha}$ and $C^{1,0}$, where a lower bound of the convergence rate for the base learner demonstrates the advantage of boosting. Moreover, in the space $C^{1,0}$, we prove that the number of iterations to achieve the fast convergence rate can be reduced by using ensemble regressor as the base learner, which improves the computational efficiency. In the experiments, compared with other state-of-the-art algorithms such as gradient boosted regression tree (GBRT), Breiman's forest, and kernel-based methods, our GBBHE algorithm shows promising performance with less running time on large-scale datasets.
Density-based Clustering with Best-scored Random Forest
Jun 24, 2019



Single-level density-based approach has long been widely acknowledged to be a conceptually and mathematically convincing clustering method. In this paper, we propose an algorithm called "best-scored clustering forest" that can obtain the optimal level and determine corresponding clusters. The terminology "best-scored" means to select one random tree with the best empirical performance out of a certain number of purely random tree candidates. From the theoretical perspective, we first show that consistency of our proposed algorithm can be guaranteed. Moreover, under certain mild restrictions on the underlying density functions and target clusters, even fast convergence rates can be achieved. Last but not least, comparisons with other state-of-the-art clustering methods in the numerical experiments demonstrate accuracy of our algorithm on both synthetic data and several benchmark real data sets.