 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser Hesitation and Negative Transfer in Multi-Behavior Recommendation
Nov 08, 2025Multi-behavior recommendation aims to integrate users' interactions across various behavior types (e.g., view, favorite, add-to-cart, purchase) to more comprehensively characterize user preferences. However, existing methods lack in-depth modeling when dealing with interactions that generate only auxiliary behaviors without triggering the target behavior. In fact, these weak signals contain rich latent information and can be categorized into two types: (1) positive weak signals-items that have not triggered the target behavior but exhibit frequent auxiliary interactions, reflecting users' hesitation tendencies toward these items; and (2) negative weak signals-auxiliary behaviors that result from misoperations or interaction noise, which deviate from true preferences and may cause negative transfer effects. To more effectively identify and utilize these weak signals, we propose a recommendation framework focused on weak signal learning, termed HNT. Specifically, HNT models weak signal features from two dimensions: positive and negative effects. By learning the characteristics of auxiliary behaviors that lead to target behaviors, HNT identifies similar auxiliary behaviors that did not trigger the target behavior and constructs a hesitation set of related items as weak positive samples to enhance preference modeling, thereby capturing users' latent hesitation intentions. Meanwhile, during auxiliary feature fusion, HNT incorporates latent negative transfer effect modeling to distinguish and suppress interference caused by negative representations through item similarity learning. Experiments on three real-world datasets demonstrate that HNT improves HR@10 and NDCG@10 by 12.57% and 14.37%, respectively, compared to the best baseline methods.
Deep Attention-Based Alignment Network for Melody Generation from Incomplete Lyrics
Jan 23, 2023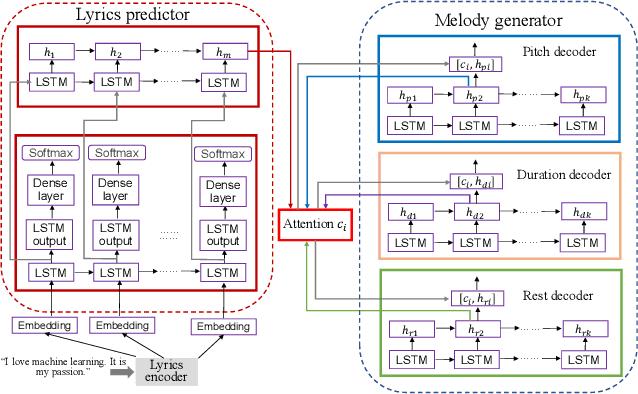
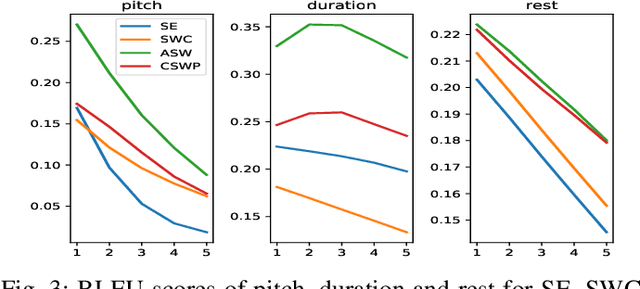
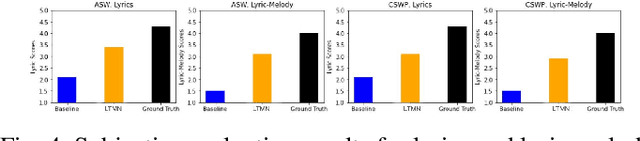
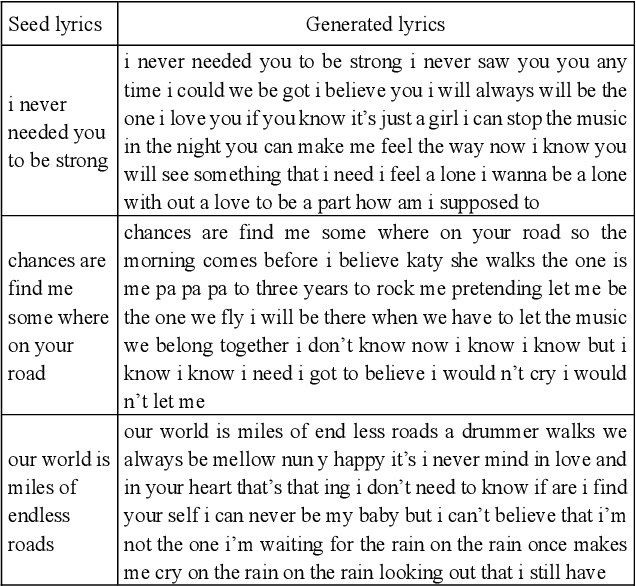
We propose a deep attention-based alignment network, which aims to automatically predict lyrics and melody with given incomplete lyrics as input in a way similar to the music creation of humans. Most importantly, a deep neural lyrics-to-melody net is trained in an encoder-decoder way to predict possible pairs of lyrics-melody when given incomplete lyrics (few keywords). The attention mechanism is exploited to align the predicted lyrics with the melody during the lyrics-to-melody generation. The qualitative and quantitative evaluation metrics reveal that the proposed method is indeed capable of generating proper lyrics and corresponding melody for composing new songs given a piece of incomplete seed lyrics.
Variational Autoencoder with CCA for Audio-Visual Cross-Modal Retrieval
Dec 05, 2021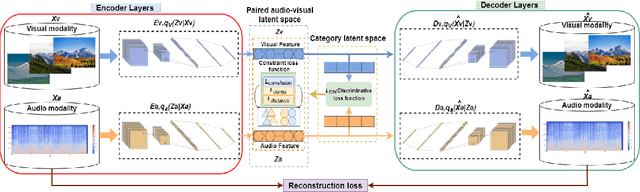


Cross-modal retrieval is to utilize one modality as a query to retrieve data from another modality, which has become a popular topic in information retrieval, machine learning, and database. How to effectively measure the similarity between different modality data is the major challenge of cross-modal retrieval. Although several reasearch works have calculated the correlation between different modality data via learning a common subspace representation, the encoder's ability to extract features from multi-modal information is not satisfactory. In this paper, we present a novel variational autoencoder (VAE) architecture for audio-visual cross-modal retrieval, by learning paired audio-visual correlation embedding and category correlation embedding as constraints to reinforce the mutuality of audio-visual information. On the one hand, audio encoder and visual encoder separately encode audio data and visual data into two different latent spaces. Further, two mutual latent spaces are respectively constructed by canonical correlation analysis (CCA). On the other hand, probabilistic modeling methods is used to deal with possible noise and missing information in the data. Additionally, in this way, the cross-modal discrepancy from intra-modal and inter-modal information are simultaneously eliminated in the joint embedding subspace. We conduct extensive experiments over two benchmark datasets. The experimental outcomes exhibit that the proposed architecture is effective in learning audio-visual correlation and is appreciably better than the existing cross-modal retrieval methods.
Automatic Neural Lyrics and Melody Composition
Nov 12, 2020
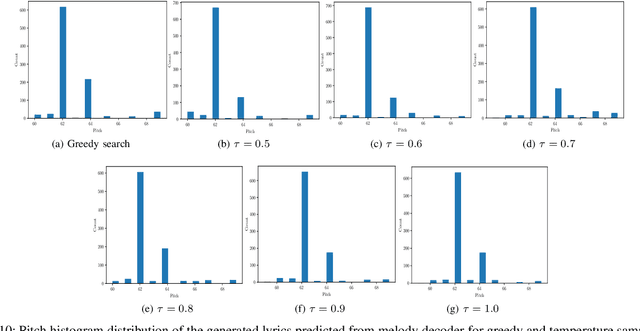
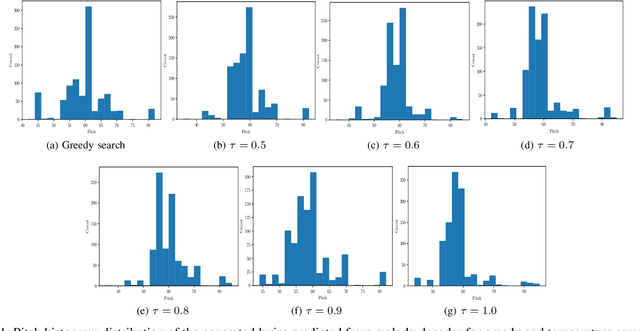
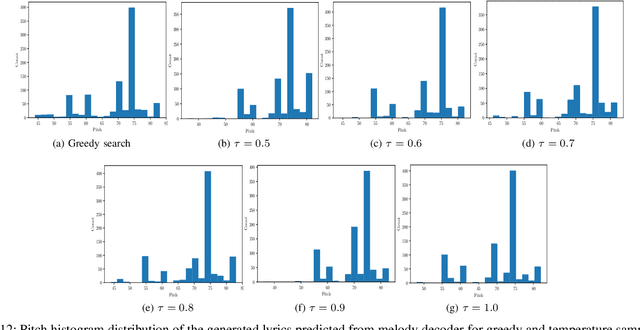
In this paper, we propose a technique to address the most challenging aspect of algorithmic songwriting process, which enables the human community to discover original lyrics, and melodies suitable for the generated lyrics. The proposed songwriting system, Automatic Neural Lyrics and Melody Composition (AutoNLMC) is an attempt to make the whole process of songwriting automatic using artificial neural networks. Our lyric to vector (lyric2vec) model trained on a large set of lyric-melody pairs dataset parsed at syllable, word and sentence levels are large scale embedding models enable us to train data driven model such as recurrent neural networks for popular English songs. AutoNLMC is a encoder-decoder sequential recurrent neural network model consisting of a lyric generator, a lyric encoder and melody decoder trained end-to-end. AutoNLMC is designed to generate both lyrics and corresponding melody automatically for an amateur or a person without music knowledge. It can also take lyrics from professional lyric writer to generate matching melodies. The qualitative and quantitative evaluation measures revealed that the proposed method is indeed capable of generating original lyrics and corresponding melody for composing new songs.
Ensemble Super-Resolution with A Reference Dataset
May 12, 2019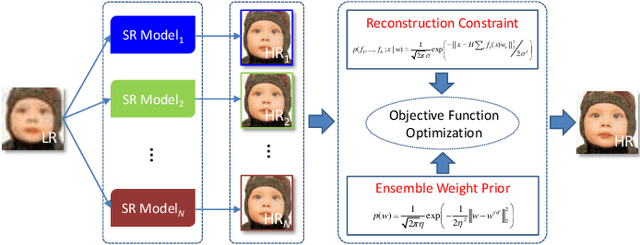


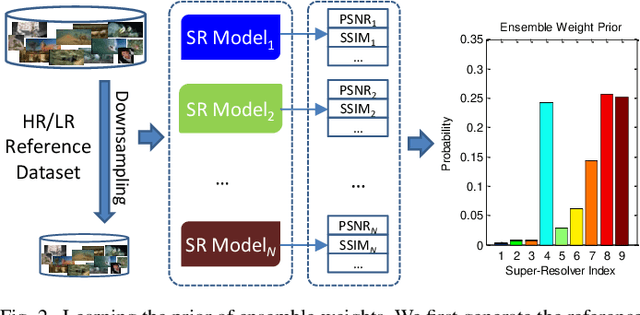
By developing sophisticated image priors or designing deep(er) architectures, a variety of image Super-Resolution (SR) approaches have been proposed recently and achieved very promising performance. A natural question that arises is whether these methods can be reformulated into a unifying framework and whether this framework assists in SR reconstruction? In this paper, we present a simple but effective single image SR method based on ensemble learning, which can produce a better performance than that could be obtained from any of SR methods to be ensembled (or called component super-resolvers). Based on the assumption that better component super-resolver should have larger ensemble weight when performing SR reconstruction, we present a Maximum A Posteriori (MAP) estimation framework for the inference of optimal ensemble weights. Specially, we introduce a reference dataset, which is composed of High-Resolution (HR) and Low-Resolution (LR) image pairs, to measure the super-resolution abilities (prior knowledge) of different component super-resolvers. To obtain the optimal ensemble weights, we propose to incorporate the reconstruction constraint, which states that the degenerated HR image should be equal to the LR observation one, as well as the prior knowledge of ensemble weights into the MAP estimation framework. Moreover, the proposed optimization problem can be solved by an analytical solution. We study the performance of the proposed method by comparing with different competitive approaches, including four state-of-the-art non-deep learning based methods, four latest deep learning based methods and one ensemble learning based method, and prove its effectiveness and superiority on three public datasets.
Context-Patch Face Hallucination Based on Thresholding Locality-constrained Representation and Reproducing Learning
Sep 15, 2018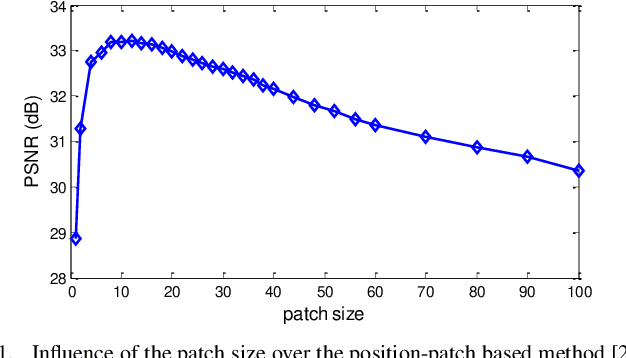
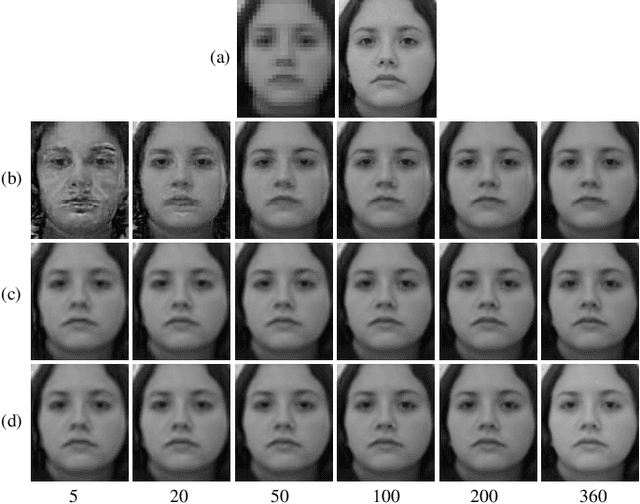


Face hallucination is a technique that reconstruct high-resolution (HR) faces from low-resolution (LR) faces, by using the prior knowledge learned from HR/LR face pairs. Most state-of-the-arts leverage position-patch prior knowledge of human face to estimate the optimal representation coefficients for each image patch. However, they focus only the position information and usually ignore the context information of image patch. In addition, when they are confronted with misalignment or the Small Sample Size (SSS) problem, the hallucination performance is very poor. To this end, this study incorporates the contextual information of image patch and proposes a powerful and efficient context-patch based face hallucination approach, namely Thresholding Locality-constrained Representation and Reproducing learning (TLcR-RL). Under the context-patch based framework, we advance a thresholding based representation method to enhance the reconstruction accuracy and reduce the computational complexity. To further improve the performance of the proposed algorithm, we propose a promotion strategy called reproducing learning. By adding the estimated HR face to the training set, which can simulates the case that the HR version of the input LR face is present in the training set, thus iteratively enhancing the final hallucination result. Experiments demonstrate that the proposed TLcR-RL method achieves a substantial increase in the hallucinated results, both subjectively and objectively. Additionally, the proposed framework is more robust to face misalignment and the SSS problem, and its hallucinated HR face is still very good when the LR test face is from the real-world. The MATLAB source code is available at https://github.com/junjun-jiang/TLcR-RL
Deep CNN Denoiser and Multi-layer Neighbor Component Embedding for Face Hallucination
Jun 28, 2018

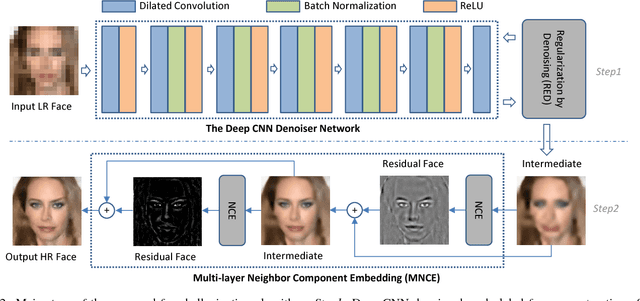
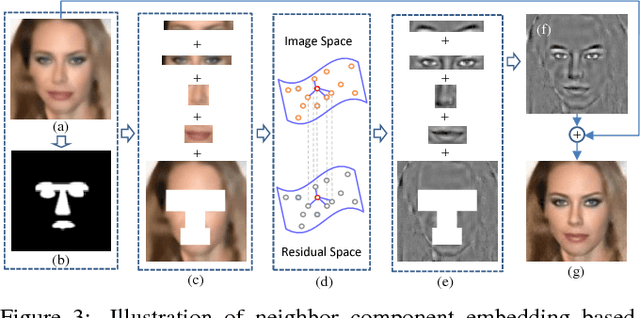
Most of the current face hallucination methods, whether they are shallow learning-based or deep learning-based, all try to learn a relationship model between Low-Resolution (LR) and High-Resolution (HR) spaces with the help of a training set. They mainly focus on modeling image prior through either model-based optimization or discriminative inference learning. However, when the input LR face is tiny, the learned prior knowledge is no longer effective and their performance will drop sharply. To solve this problem, in this paper we propose a general face hallucination method that can integrate model-based optimization and discriminative inference. In particular, to exploit the model based prior, the Deep Convolutional Neural Networks (CNN) denoiser prior is plugged into the super-resolution optimization model with the aid of image-adaptive Laplacian regularization. Additionally, we further develop a high-frequency details compensation method by dividing the face image to facial components and performing face hallucination in a multi-layer neighbor embedding manner. Experiments demonstrate that the proposed method can achieve promising super-resolution results for tiny input LR faces.
Category-Based Deep CCA for Fine-Grained Venue Discovery from Multimodal Data
May 08, 2018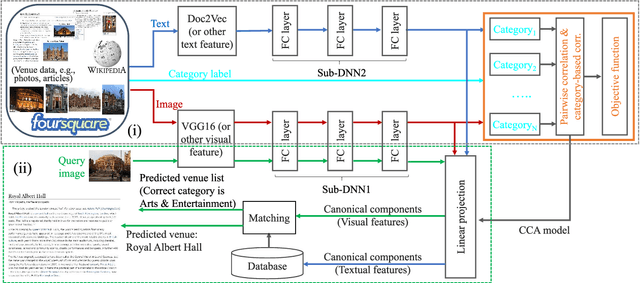
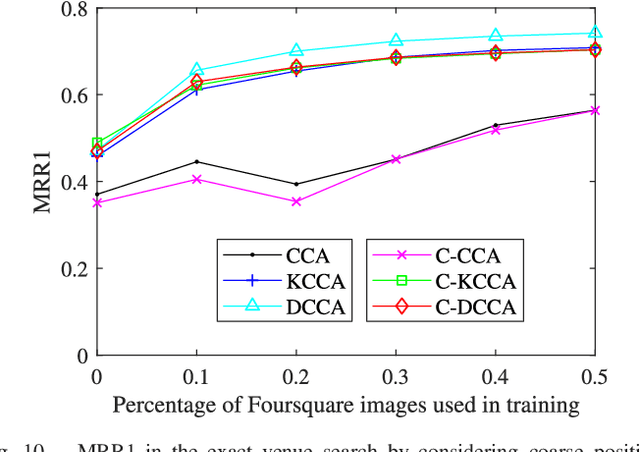
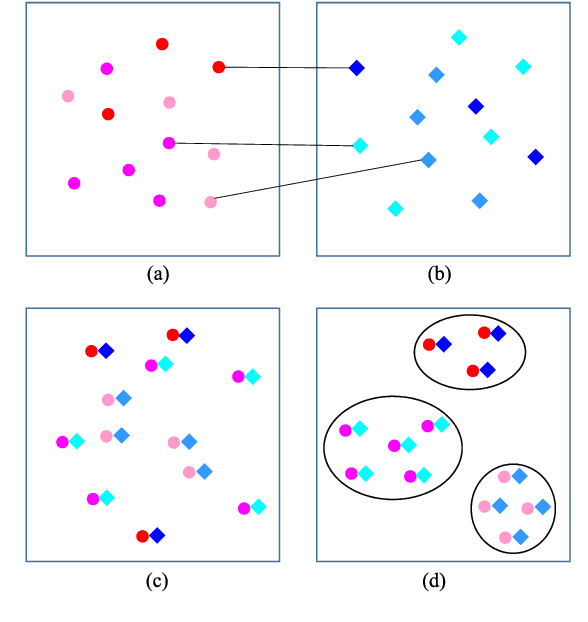
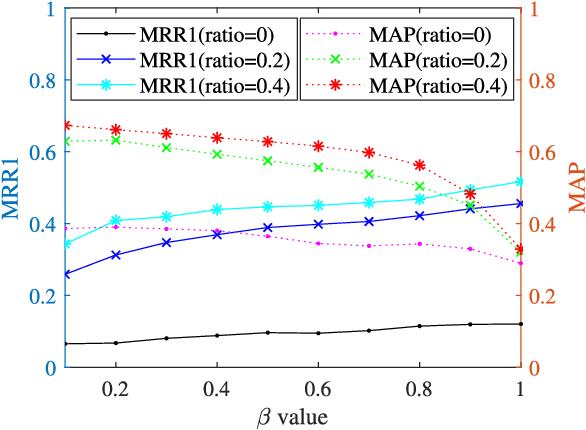
In this work, travel destination and business location are taken as venues. Discovering a venue by a photo is very important for context-aware applications. Unfortunately, few efforts paid attention to complicated real images such as venue photos generated by users. Our goal is fine-grained venue discovery from heterogeneous social multimodal data. To this end, we propose a novel deep learning model, Category-based Deep Canonical Correlation Analysis (C-DCCA). Given a photo as input, this model performs (i) exact venue search (find the venue where the photo was taken), and (ii) group venue search (find relevant venues with the same category as that of the photo), by the cross-modal correlation between the input photo and textual description of venues. In this model, data in different modalities are projected to a same space via deep networks. Pairwise correlation (between different modal data from the same venue) for exact venue search and category-based correlation (between different modal data from different venues with the same category) for group venue search are jointly optimized. Because a photo cannot fully reflect rich text description of a venue, the number of photos per venue in the training phase is increased to capture more aspects of a venue. We build a new venue-aware multimodal dataset by integrating Wikipedia featured articles and Foursquare venue photos. Experimental results on this dataset confirm the feasibility of the proposed method. Moreover, the evaluation over another publicly available dataset confirms that the proposed method outperforms state-of-the-arts for cross-modal retrieval between image and text.
Towards Deep Modeling of Music Semantics using EEG Regularizers
Dec 15, 2017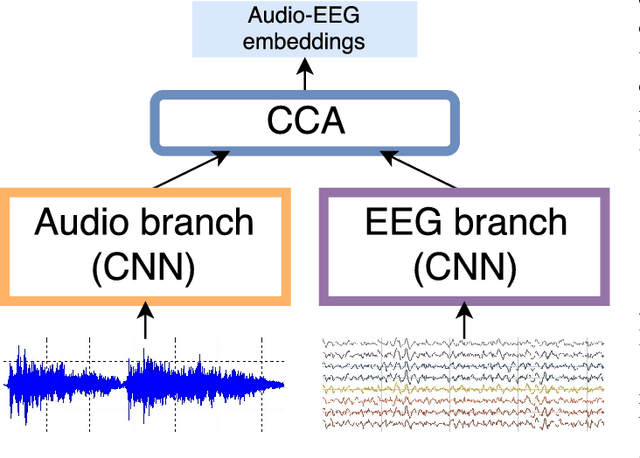
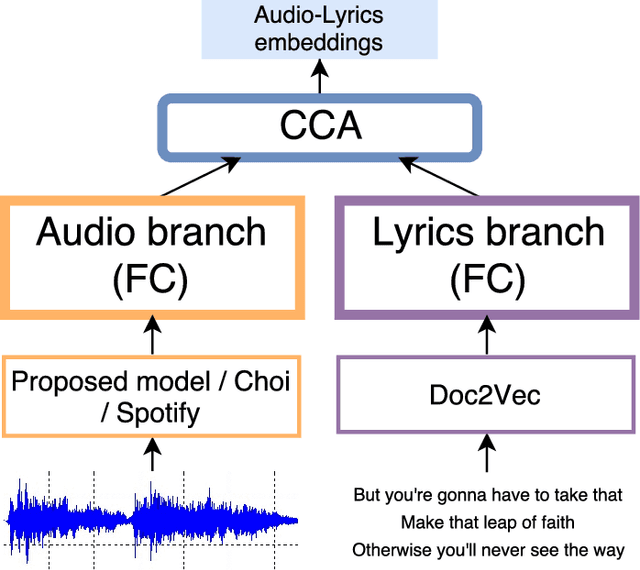
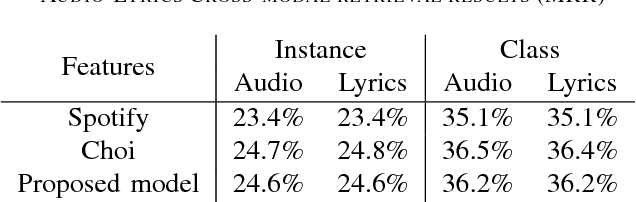
Modeling of music audio semantics has been previously tackled through learning of mappings from audio data to high-level tags or latent unsupervised spaces. The resulting semantic spaces are theoretically limited, either because the chosen high-level tags do not cover all of music semantics or because audio data itself is not enough to determine music semantics. In this paper, we propose a generic framework for semantics modeling that focuses on the perception of the listener, through EEG data, in addition to audio data. We implement this framework using a novel end-to-end 2-view Neural Network (NN) architecture and a Deep Canonical Correlation Analysis (DCCA) loss function that forces the semantic embedding spaces of both views to be maximally correlated. We also detail how the EEG dataset was collected and use it to train our proposed model. We evaluate the learned semantic space in a transfer learning context, by using it as an audio feature extractor in an independent dataset and proxy task: music audio-lyrics cross-modal retrieval. We show that our embedding model outperforms Spotify features and performs comparably to a state-of-the-art embedding model that was trained on 700 times more data. We further discuss improvements to the model that are likely to improve its performance.