 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity Re-identification in Visual Storytelling via Contrastive Reinforcement Learning
Jul 09, 2025Visual storytelling systems, particularly large vision-language models, struggle to maintain character and object identity across frames, often failing to recognize when entities in different images represent the same individuals or objects, leading to inconsistent references and referential hallucinations. This occurs because models lack explicit training on when to establish entity connections across frames. We propose a contrastive reinforcement learning approach that trains models to discriminate between coherent image sequences and stories from unrelated images. We extend the Story Reasoning dataset with synthetic negative examples to teach appropriate entity connection behavior. We employ Direct Preference Optimization with a dual-component reward function that promotes grounding and re-identification of entities in real stories while penalizing incorrect entity connections in synthetic contexts. Using this contrastive framework, we fine-tune Qwen Storyteller (based on Qwen2.5-VL 7B). Evaluation shows improvements in grounding mAP from 0.27 to 0.31 (+14.8%), F1 from 0.35 to 0.41 (+17.1%). Pronoun grounding accuracy improved across all pronoun types except ``its'', and cross-frame character and object persistence increased across all frame counts, with entities appearing in 5 or more frames advancing from 29.3% to 33.3% (+13.7%). Well-structured stories, containing the chain-of-thought and grounded story, increased from 79.1% to 97.5% (+23.3%).
StoryReasoning Dataset: Using Chain-of-Thought for Scene Understanding and Grounded Story Generation
May 15, 2025Visual storytelling systems struggle to maintain character identity across frames and link actions to appropriate subjects, frequently leading to referential hallucinations. These issues can be addressed through grounding of characters, objects, and other entities on the visual elements. We propose StoryReasoning, a dataset containing 4,178 stories derived from 52,016 movie images, with both structured scene analyses and grounded stories. Each story maintains character and object consistency across frames while explicitly modeling multi-frame relationships through structured tabular representations. Our approach features cross-frame object re-identification using visual similarity and face recognition, chain-of-thought reasoning for explicit narrative modeling, and a grounding scheme that links textual elements to visual entities across multiple frames. We establish baseline performance by fine-tuning Qwen2.5-VL 7B, creating Qwen Storyteller, which performs end-to-end object detection, re-identification, and landmark detection while maintaining consistent object references throughout the story. Evaluation demonstrates a reduction from 4.06 to 3.56 (-12.3%) hallucinations on average per story when compared to a non-fine-tuned model.
GroundCap: A Visually Grounded Image Captioning Dataset
Feb 19, 2025Current image captioning systems lack the ability to link descriptive text to specific visual elements, making their outputs difficult to verify. While recent approaches offer some grounding capabilities, they cannot track object identities across multiple references or ground both actions and objects simultaneously. We propose a novel ID-based grounding system that enables consistent object reference tracking and action-object linking, and present GroundCap, a dataset containing 52,016 images from 77 movies, with 344 human-annotated and 52,016 automatically generated captions. Each caption is grounded on detected objects (132 classes) and actions (51 classes) using a tag system that maintains object identity while linking actions to the corresponding objects. Our approach features persistent object IDs for reference tracking, explicit action-object linking, and segmentation of background elements through K-means clustering. We propose gMETEOR, a metric combining caption quality with grounding accuracy, and establish baseline performance by fine-tuning Pixtral-12B. Human evaluation demonstrates our approach's effectiveness in producing verifiable descriptions with coherent object references.
Tackling Cognitive Impairment Detection from Speech: A submission to the PROCESS Challenge
Dec 30, 2024



This work describes our group's submission to the PROCESS Challenge 2024, with the goal of assessing cognitive decline through spontaneous speech, using three guided clinical tasks. This joint effort followed a holistic approach, encompassing both knowledge-based acoustic and text-based feature sets, as well as LLM-based macrolinguistic descriptors, pause-based acoustic biomarkers, and multiple neural representations (e.g., LongFormer, ECAPA-TDNN, and Trillson embeddings). Combining these feature sets with different classifiers resulted in a large pool of models, from which we selected those that provided the best balance between train, development, and individual class performance. Our results show that our best performing systems correspond to combinations of models that are complementary to each other, relying on acoustic and textual information from all three clinical tasks.
Story Generation from Visual Inputs: Techniques, Related Tasks, and Challenges
Jun 04, 2024



Creating engaging narratives from visual data is crucial for automated digital media consumption, assistive technologies, and interactive entertainment. This survey covers methodologies used in the generation of these narratives, focusing on their principles, strengths, and limitations. The survey also covers tasks related to automatic story generation, such as image and video captioning, and visual question answering, as well as story generation without visual inputs. These tasks share common challenges with visual story generation and have served as inspiration for the techniques used in the field. We analyze the main datasets and evaluation metrics, providing a critical perspective on their limitations.
Computational analysis of the language of pain: a systematic review
Apr 24, 2024



Objectives: This study aims to systematically review the literature on the computational processing of the language of pain, whether generated by patients or physicians, identifying current trends and challenges. Methods: Following the PRISMA guidelines, a comprehensive literature search was conducted to select relevant studies on the computational processing of the language of pain and answer pre-defined research questions. Data extraction and synthesis were performed to categorize selected studies according to their primary purpose and outcome, patient and pain population, textual data, computational methodology, and outcome targets. Results: Physician-generated language of pain, specifically from clinical notes, was the most used data. Tasks included patient diagnosis and triaging, identification of pain mentions, treatment response prediction, biomedical entity extraction, correlation of linguistic features with clinical states, and lexico-semantic analysis of pain narratives. Only one study included previous linguistic knowledge on pain utterances in their experimental setup. Most studies targeted their outcomes for physicians, either directly as clinical tools or as indirect knowledge. The least targeted stage of clinical pain care was self-management, in which patients are most involved. The least studied dimensions of pain were affective and sociocultural. Only two studies measured how physician performance on clinical tasks improved with the inclusion of the proposed algorithm. Discussion: This study found that future research should focus on analyzing patient-generated language of pain, developing patient-centered resources for self-management and patient-empowerment, exploring affective and sociocultural aspects of pain, and measuring improvements in physician performance when aided by the proposed tools.
Chronic pain patient narratives allow for the estimation of current pain intensity
Nov 17, 2022



Chronic pain is a multi-dimensional experience, and pain intensity plays an important part, impacting the patients emotional balance, psychology, and behaviour. Standard self-reporting tools, such as the Visual Analogue Scale for pain, fail to capture this burden. Moreover, this type of tools is susceptible to a degree of subjectivity, dependent on the patients clear understanding of how to use it, social biases, and their ability to translate a complex experience to a scale. To overcome these and other self-reporting challenges, pain intensity estimation has been previously studied based on facial expressions, electroencephalograms, brain imaging, and autonomic features. However, to the best of our knowledge, it has never been attempted to base this estimation on the patient narratives of the personal experience of chronic pain, which is what we propose in this work. Indeed, in the clinical assessment and management of chronic pain, verbal communication is essential to convey information to physicians that would otherwise not be easily accessible through standard reporting tools, since language, sociocultural, and psychosocial variables are intertwined. We show that language features from patient narratives indeed convey information relevant for pain intensity estimation, and that our computational models can take advantage of that. Specifically, our results show that patients with mild pain focus more on the use of verbs, whilst moderate and severe pain patients focus on adverbs, and nouns and adjectives, respectively, and that these differences allow for the distinction between these three pain classes.
Transfer-learning for video classification: Video Swin Transformer on multiple domains
Oct 18, 2022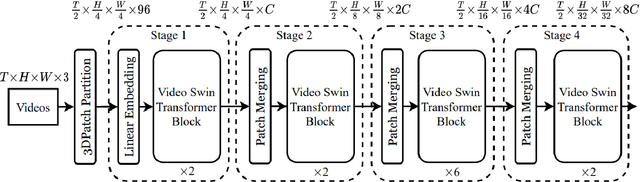
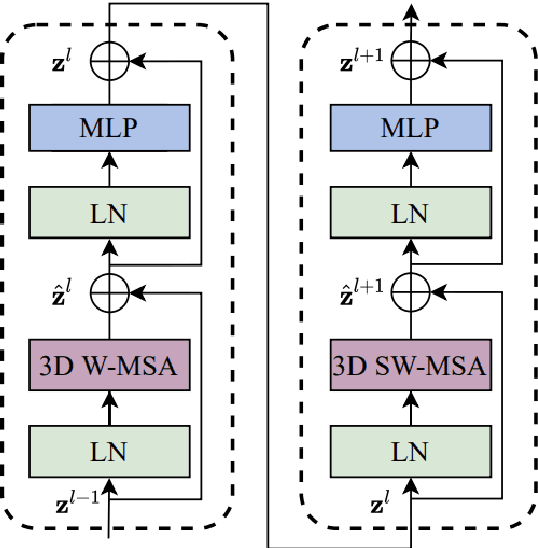
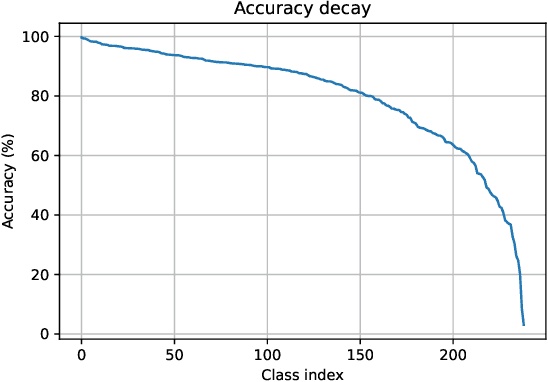
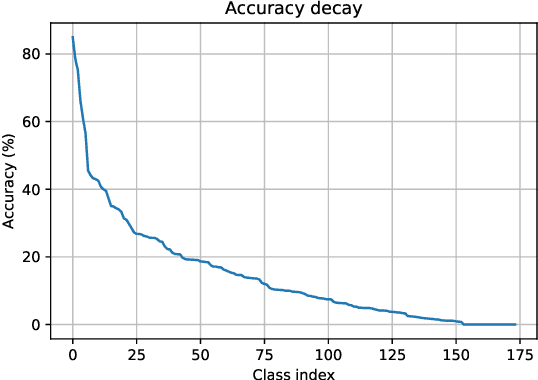
The computer vision community has seen a shift from convolutional-based to pure transformer architectures for both image and video tasks. Training a transformer from zero for these tasks usually requires a lot of data and computational resources. Video Swin Transformer (VST) is a pure-transformer model developed for video classification which achieves state-of-the-art results in accuracy and efficiency on several datasets. In this paper, we aim to understand if VST generalizes well enough to be used in an out-of-domain setting. We study the performance of VST on two large-scale datasets, namely FCVID and Something-Something using a transfer learning approach from Kinetics-400, which requires around 4x less memory than training from scratch. We then break down the results to understand where VST fails the most and in which scenarios the transfer-learning approach is viable. Our experiments show an 85\% top-1 accuracy on FCVID without retraining the whole model which is equal to the state-of-the-art for the dataset and a 21\% accuracy on Something-Something. The experiments also suggest that the performance of the VST decreases on average when the video duration increases which seems to be a consequence of a design choice of the model. From the results, we conclude that VST generalizes well enough to classify out-of-domain videos without retraining when the target classes are from the same type as the classes used to train the model. We observed this effect when we performed transfer-learning from Kinetics-400 to FCVID, where most datasets target mostly objects. On the other hand, if the classes are not from the same type, then the accuracy after the transfer-learning approach is expected to be poor. We observed this effect when we performed transfer-learning from Kinetics-400, where the classes represent mostly objects, to Something-Something, where the classes represent mostly actions.
Towards Learning Through Open-Domain Dialog
Feb 07, 2022The development of artificial agents able to learn through dialog without domain restrictions has the potential to allow machines to learn how to perform tasks in a similar manner to humans and change how we relate to them. However, research in this area is practically nonexistent. In this paper, we identify the modifications required for a dialog system to be able to learn from the dialog and propose generic approaches that can be used to implement those modifications. More specifically, we discuss how knowledge can be extracted from the dialog, used to update the agent's semantic network, and grounded in action and observation. This way, we hope to raise awareness for this subject, so that it can become a focus of research in the future.
Chronic Pain and Language: A Topic Modelling Approach to Personal Pain Descriptions
Sep 01, 2021
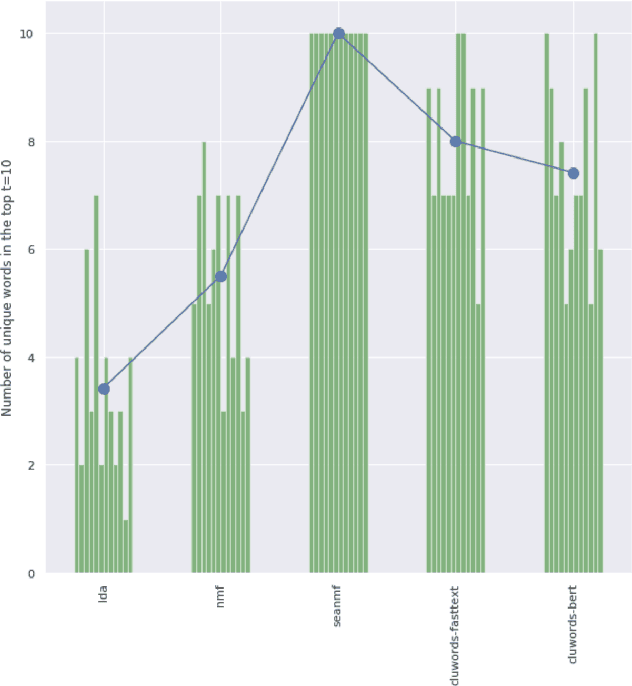
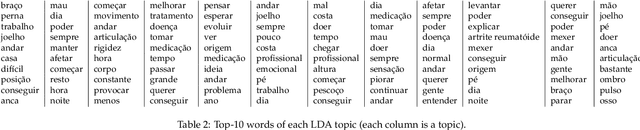
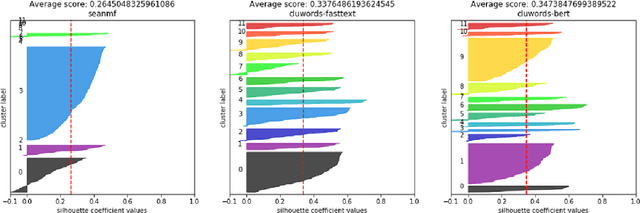
Chronic pain is recognized as a major health problem, with impacts not only at the economic, but also at the social, and individual levels. Being a private and subjective experience, it is impossible to externally and impartially experience, describe, and interpret chronic pain as a purely noxious stimulus that would directly point to a causal agent and facilitate its mitigation, contrary to acute pain, the assessment of which is usually straightforward. Verbal communication is, thus, key to convey relevant information to health professionals that would otherwise not be accessible to external entities, namely, intrinsic qualities about the painful experience and the patient. We propose and discuss a topic modelling approach to recognize patterns in verbal descriptions of chronic pain, and use these patterns to quantify and qualify experiences of pain. Our approaches allow for the extraction of novel insights on chronic pain experiences from the obtained topic models and latent spaces. We argue that our results are clinically relevant for the assessment and management of chronic pain.