 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStoryMovie: A Dataset for Semantic Alignment of Visual Stories with Movie Scripts and Subtitles
Feb 25, 2026Visual storytelling models that correctly ground entities in images may still hallucinate semantic relationships, generating incorrect dialogue attribution, character interactions, or emotional states. We introduce StoryMovie, a dataset of 1,757 stories aligned with movie scripts and subtitles through LCS matching. Our alignment pipeline synchronizes screenplay dialogue with subtitle timestamps, enabling dialogue attribution by linking character names from scripts to temporal positions from subtitles. Using this aligned content, we generate stories that maintain visual grounding tags while incorporating authentic character names, dialogue, and relationship dynamics. We fine-tune Qwen Storyteller3 on this dataset, building on prior work in visual grounding and entity re-identification. Evaluation using DeepSeek V3 as judge shows that Storyteller3 achieves an 89.9% win rate against base Qwen2.5-VL 7B on subtitle alignment. Compared to Storyteller, trained without script grounding, Storyteller3 achieves 48.5% versus 38.0%, confirming that semantic alignment progressively improves dialogue attribution beyond visual grounding alone.
Transfer-learning for video classification: Video Swin Transformer on multiple domains
Oct 18, 2022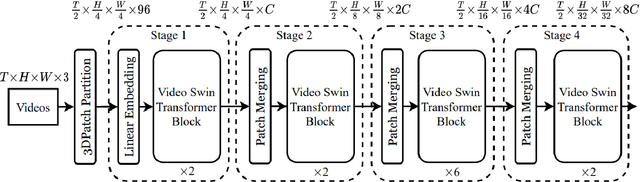
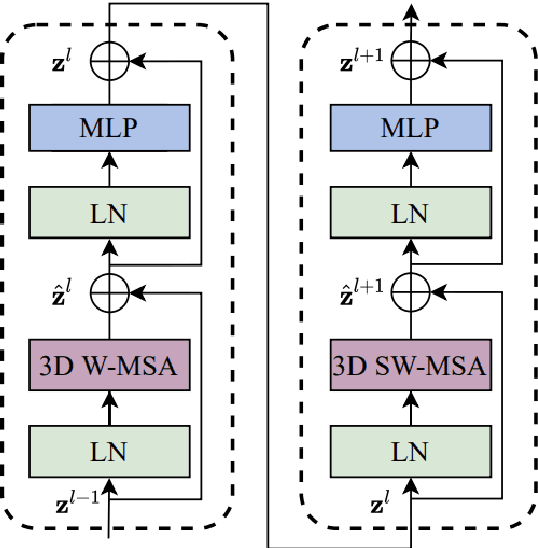
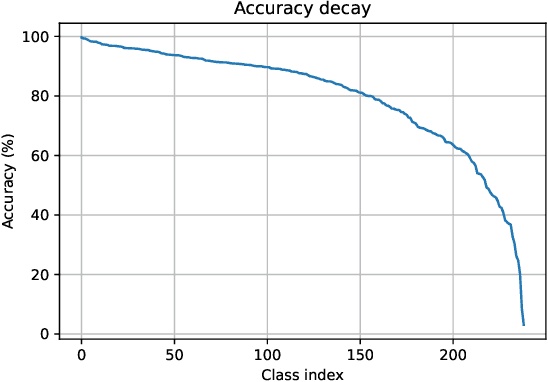
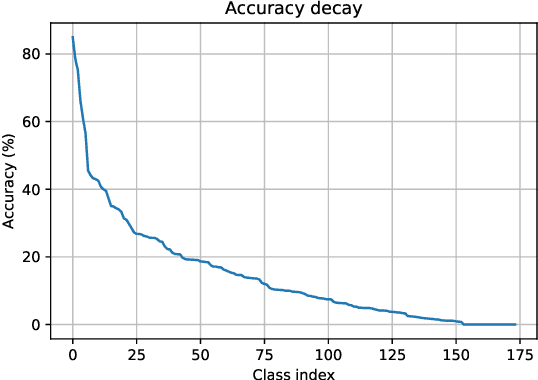
The computer vision community has seen a shift from convolutional-based to pure transformer architectures for both image and video tasks. Training a transformer from zero for these tasks usually requires a lot of data and computational resources. Video Swin Transformer (VST) is a pure-transformer model developed for video classification which achieves state-of-the-art results in accuracy and efficiency on several datasets. In this paper, we aim to understand if VST generalizes well enough to be used in an out-of-domain setting. We study the performance of VST on two large-scale datasets, namely FCVID and Something-Something using a transfer learning approach from Kinetics-400, which requires around 4x less memory than training from scratch. We then break down the results to understand where VST fails the most and in which scenarios the transfer-learning approach is viable. Our experiments show an 85\% top-1 accuracy on FCVID without retraining the whole model which is equal to the state-of-the-art for the dataset and a 21\% accuracy on Something-Something. The experiments also suggest that the performance of the VST decreases on average when the video duration increases which seems to be a consequence of a design choice of the model. From the results, we conclude that VST generalizes well enough to classify out-of-domain videos without retraining when the target classes are from the same type as the classes used to train the model. We observed this effect when we performed transfer-learning from Kinetics-400 to FCVID, where most datasets target mostly objects. On the other hand, if the classes are not from the same type, then the accuracy after the transfer-learning approach is expected to be poor. We observed this effect when we performed transfer-learning from Kinetics-400, where the classes represent mostly objects, to Something-Something, where the classes represent mostly actions.