 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFalAR: A Large-scale Speaker-Annotated European Portuguese Speech Corpus of Parliamentary Sessions
May 26, 2026State-of-the-art performance for Automatic Speech Recognition (ASR) largely depends on the availability of large-scale labeled corpora. This creates a demand for increased data collection efforts, particularly for under-represented languages and dialectal varieties. Due to having considerably fewer speakers (around 11 million), European Portuguese (EP) is overshadowed by Brazilian Portuguese (BP) (around 200 million speakers) in currently available large-scale speech data resources, resulting in under-performing speech-based systems for EP users. To address this gap, and following similar data collection efforts for other languages, we present FalAR, a large-scale, speaker-annotated speech corpus of European Portuguese parliamentary sessions. Spanning approximately 20 years, FalAR comprises 5,800 hours of speech data. In addition, 4,850 hours have speaker identity annotations, for a total of 1,180 speakers with associated metadata including age, gender, political affiliation, and parliamentary role. The corpus was built using a state-of-the-art EP CAMÕES ASR model for transcription-reference alignment. In this paper, we describe the data collection process, together with the main characteristics of the FalAR corpus. Furthermore, we evaluate the trade-off between data quantity and alignment accuracy on ASR performance, with our experiments demonstrating that incorporating FalAR as pre-training data yields up to 14% relative WER improvement over baseline models.
CAMÕES: A Comprehensive Automatic Speech Recognition Benchmark for European Portuguese
Aug 27, 2025Existing resources for Automatic Speech Recognition in Portuguese are mostly focused on Brazilian Portuguese, leaving European Portuguese (EP) and other varieties under-explored. To bridge this gap, we introduce CAM\~OES, the first open framework for EP and other Portuguese varieties. It consists of (1) a comprehensive evaluation benchmark, including 46h of EP test data spanning multiple domains; and (2) a collection of state-of-the-art models. For the latter, we consider multiple foundation models, evaluating their zero-shot and fine-tuned performances, as well as E-Branchformer models trained from scratch. A curated set of 425h of EP was used for both fine-tuning and training. Our results show comparable performance for EP between fine-tuned foundation models and the E-Branchformer. Furthermore, the best-performing models achieve relative improvements above 35% WER, compared to the strongest zero-shot foundation model, establishing a new state-of-the-art for EP and other varieties.
On the Relevance of Clinical Assessment Tasks for the Automatic Detection of Parkinson's Disease Medication State from Speech
May 21, 2025The automatic identification of medication states of Parkinson's disease (PD) patients can assist clinicians in monitoring and scheduling personalized treatments, as well as studying the effects of medication in alleviating the motor symptoms that characterize the disease. This paper explores speech as a non-invasive and accessible biomarker for identifying PD medication states, introducing a novel approach that addresses this task from a speaker-independent perspective. While traditional machine learning models achieve competitive results, self-supervised speech representations prove essential for optimal performance, significantly surpassing knowledge-based acoustic descriptors. Experiments across diverse speech assessment tasks highlight the relevance of prosody and continuous speech in distinguishing medication states, reaching an F1-score of 88.2%. These findings may streamline clinicians' work and reduce patient effort in voice recordings.
Tackling Cognitive Impairment Detection from Speech: A submission to the PROCESS Challenge
Dec 30, 2024



This work describes our group's submission to the PROCESS Challenge 2024, with the goal of assessing cognitive decline through spontaneous speech, using three guided clinical tasks. This joint effort followed a holistic approach, encompassing both knowledge-based acoustic and text-based feature sets, as well as LLM-based macrolinguistic descriptors, pause-based acoustic biomarkers, and multiple neural representations (e.g., LongFormer, ECAPA-TDNN, and Trillson embeddings). Combining these feature sets with different classifiers resulted in a large pool of models, from which we selected those that provided the best balance between train, development, and individual class performance. Our results show that our best performing systems correspond to combinations of models that are complementary to each other, relying on acoustic and textual information from all three clinical tasks.
Using Self-Supervised Feature Extractors with Attention for Automatic COVID-19 Detection from Speech
Jun 30, 2021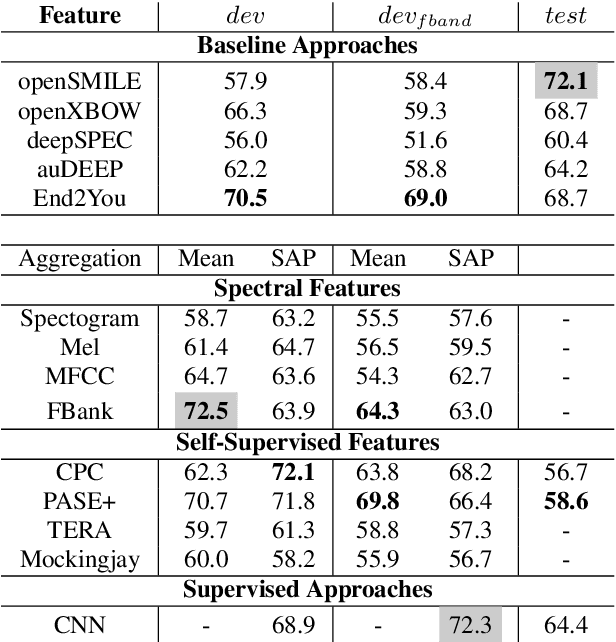
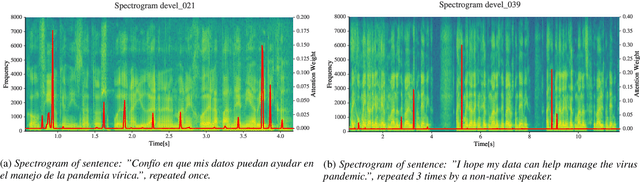
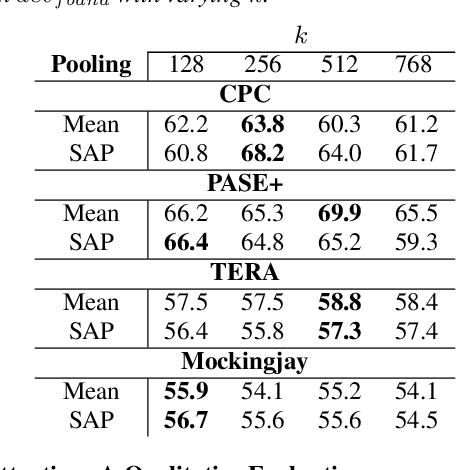
The ComParE 2021 COVID-19 Speech Sub-challenge provides a test-bed for the evaluation of automatic detectors of COVID-19 from speech. Such models can be of value by providing test triaging capabilities to health authorities, working alongside traditional testing methods. Herein, we leverage the usage of pre-trained, problem agnostic, speech representations and evaluate their use for this task. We compare the obtained results against a CNN architecture trained from scratch and traditional frequency-domain representations. We also evaluate the usage of Self-Attention Pooling as an utterance-level information aggregation method. Experimental results demonstrate that models trained on features extracted from self-supervised models perform similarly or outperform fully-supervised models and models based on handcrafted features. Our best model improves the Unweighted Average Recall (UAR) from 69.0\% to 72.3\% on a development set comprised of only full-band examples and achieves 64.4\% on the test set. Furthermore, we study where the network is attending, attempting to draw some conclusions regarding its explainability. In this relatively small dataset, we find the network attends especially to vowels and aspirates.