 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Relevance of Clinical Assessment Tasks for the Automatic Detection of Parkinson's Disease Medication State from Speech
May 21, 2025The automatic identification of medication states of Parkinson's disease (PD) patients can assist clinicians in monitoring and scheduling personalized treatments, as well as studying the effects of medication in alleviating the motor symptoms that characterize the disease. This paper explores speech as a non-invasive and accessible biomarker for identifying PD medication states, introducing a novel approach that addresses this task from a speaker-independent perspective. While traditional machine learning models achieve competitive results, self-supervised speech representations prove essential for optimal performance, significantly surpassing knowledge-based acoustic descriptors. Experiments across diverse speech assessment tasks highlight the relevance of prosody and continuous speech in distinguishing medication states, reaching an F1-score of 88.2%. These findings may streamline clinicians' work and reduce patient effort in voice recordings.
Tackling Cognitive Impairment Detection from Speech: A submission to the PROCESS Challenge
Dec 30, 2024



This work describes our group's submission to the PROCESS Challenge 2024, with the goal of assessing cognitive decline through spontaneous speech, using three guided clinical tasks. This joint effort followed a holistic approach, encompassing both knowledge-based acoustic and text-based feature sets, as well as LLM-based macrolinguistic descriptors, pause-based acoustic biomarkers, and multiple neural representations (e.g., LongFormer, ECAPA-TDNN, and Trillson embeddings). Combining these feature sets with different classifiers resulted in a large pool of models, from which we selected those that provided the best balance between train, development, and individual class performance. Our results show that our best performing systems correspond to combinations of models that are complementary to each other, relying on acoustic and textual information from all three clinical tasks.
Unveiling Interpretability in Self-Supervised Speech Representations for Parkinson's Diagnosis
Dec 02, 2024
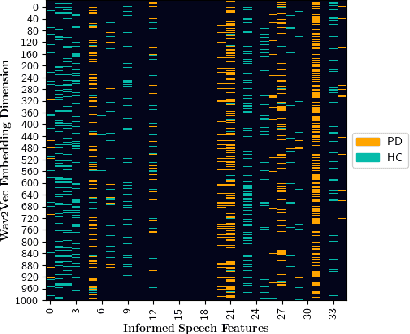
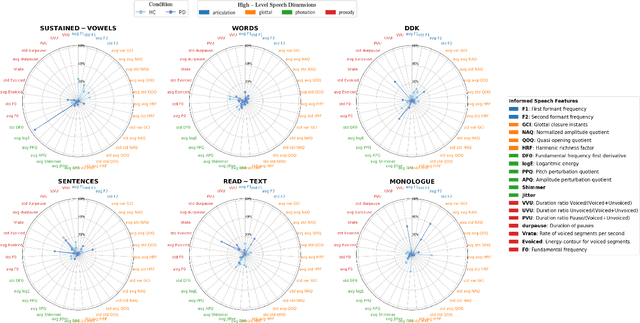
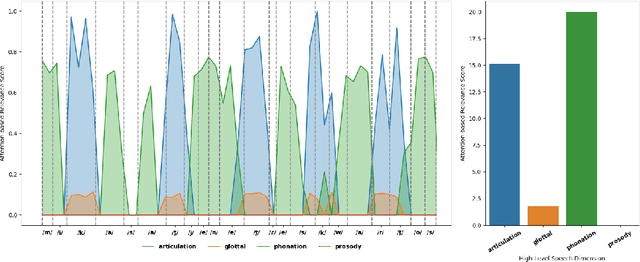
Recent works in pathological speech analysis have increasingly relied on powerful self-supervised speech representations, leading to promising results. However, the complex, black-box nature of these embeddings and the limited research on their interpretability significantly restrict their adoption for clinical diagnosis. To address this gap, we propose a novel, interpretable framework specifically designed to support Parkinson's Disease (PD) diagnosis. Through the design of simple yet effective cross-attention mechanisms for both embedding- and temporal-level analysis, the proposed framework offers interpretability from two distinct but complementary perspectives. Experimental findings across five well-established speech benchmarks for PD detection demonstrate the framework's capability to identify meaningful speech patterns within self-supervised representations for a wide range of assessment tasks. Fine-grained temporal analyses further underscore its potential to enhance the interpretability of deep-learning pathological speech models, paving the way for the development of more transparent, trustworthy, and clinically applicable computer-assisted diagnosis systems in this domain. Moreover, in terms of classification accuracy, our method achieves results competitive with state-of-the-art approaches, while also demonstrating robustness in cross-lingual scenarios when applied to spontaneous speech production.
Tailored Design of Audio-Visual Speech Recognition Models using Branchformers
Jul 09, 2024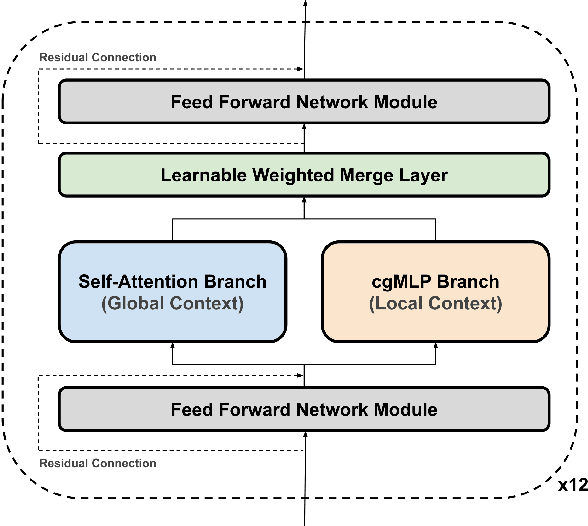

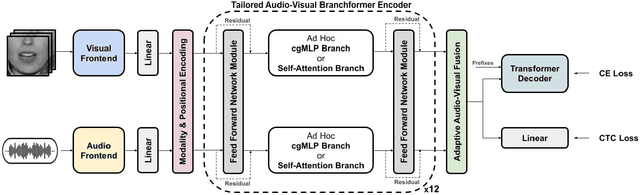

Recent advances in Audio-Visual Speech Recognition (AVSR) have led to unprecedented achievements in the field, improving the robustness of this type of system in adverse, noisy environments. In most cases, this task has been addressed through the design of models composed of two independent encoders, each dedicated to a specific modality. However, while recent works have explored unified audio-visual encoders, determining the optimal cross-modal architecture remains an ongoing challenge. Furthermore, such approaches often rely on models comprising vast amounts of parameters and high computational cost training processes. In this paper, we aim to bridge this research gap by introducing a novel audio-visual framework. Our proposed method constitutes, to the best of our knowledge, the first attempt to harness the flexibility and interpretability offered by encoder architectures, such as the Branchformer, in the design of parameter-efficient AVSR systems. To be more precise, the proposed framework consists of two steps: first, estimating audio- and video-only systems, and then designing a tailored audio-visual unified encoder based on the layer-level branch scores provided by the modality-specific models. Extensive experiments on English and Spanish AVSR benchmarks covering multiple data conditions and scenarios demonstrated the effectiveness of our proposed method. Results reflect how our tailored AVSR system is able to reach state-of-the-art recognition rates while significantly reducing the model complexity w.r.t. the prevalent approach in the field. Code and pre-trained models are available at https://github.com/david-gimeno/tailored-avsr.
Reading Order Independent Metrics for Information Extraction in Handwritten Documents
Apr 29, 2024



Information Extraction processes in handwritten documents tend to rely on obtaining an automatic transcription and performing Named Entity Recognition (NER) over such transcription. For this reason, in publicly available datasets, the performance of the systems is usually evaluated with metrics particular to each dataset. Moreover, most of the metrics employed are sensitive to reading order errors. Therefore, they do not reflect the expected final application of the system and introduce biases in more complex documents. In this paper, we propose and publicly release a set of reading order independent metrics tailored to Information Extraction evaluation in handwritten documents. In our experimentation, we perform an in-depth analysis of the behavior of the metrics to recommend what we consider to be the minimal set of metrics to evaluate a task correctly.
Comparison of Conventional Hybrid and CTC/Attention Decoders for Continuous Visual Speech Recognition
Feb 20, 2024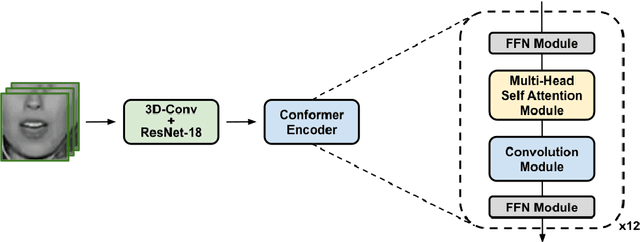
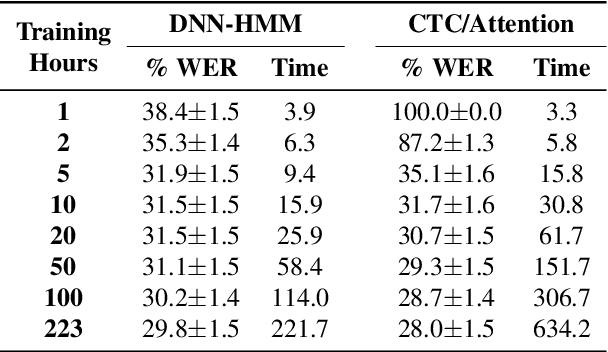
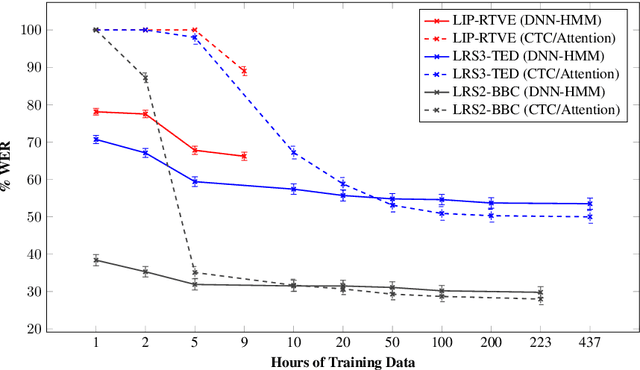
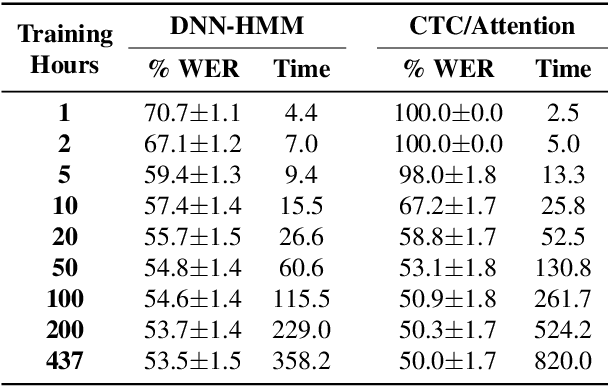
Thanks to the rise of deep learning and the availability of large-scale audio-visual databases, recent advances have been achieved in Visual Speech Recognition (VSR). Similar to other speech processing tasks, these end-to-end VSR systems are usually based on encoder-decoder architectures. While encoders are somewhat general, multiple decoding approaches have been explored, such as the conventional hybrid model based on Deep Neural Networks combined with Hidden Markov Models (DNN-HMM) or the Connectionist Temporal Classification (CTC) paradigm. However, there are languages and tasks in which data is scarce, and in this situation, there is not a clear comparison between different types of decoders. Therefore, we focused our study on how the conventional DNN-HMM decoder and its state-of-the-art CTC/Attention counterpart behave depending on the amount of data used for their estimation. We also analyzed to what extent our visual speech features were able to adapt to scenarios for which they were not explicitly trained, either considering a similar dataset or another collected for a different language. Results showed that the conventional paradigm reached recognition rates that improve the CTC/Attention model in data-scarcity scenarios along with a reduced training time and fewer parameters.
AnnoTheia: A Semi-Automatic Annotation Toolkit for Audio-Visual Speech Technologies
Feb 20, 2024



More than 7,000 known languages are spoken around the world. However, due to the lack of annotated resources, only a small fraction of them are currently covered by speech technologies. Albeit self-supervised speech representations, recent massive speech corpora collections, as well as the organization of challenges, have alleviated this inequality, most studies are mainly benchmarked on English. This situation is aggravated when tasks involving both acoustic and visual speech modalities are addressed. In order to promote research on low-resource languages for audio-visual speech technologies, we present AnnoTheia, a semi-automatic annotation toolkit that detects when a person speaks on the scene and the corresponding transcription. In addition, to show the complete process of preparing AnnoTheia for a language of interest, we also describe the adaptation of a pre-trained model for active speaker detection to Spanish, using a database not initially conceived for this type of task. The AnnoTheia toolkit, tutorials, and pre-trained models are available on GitHub.
Speaker-Adapted End-to-End Visual Speech Recognition for Continuous Spanish
Nov 21, 2023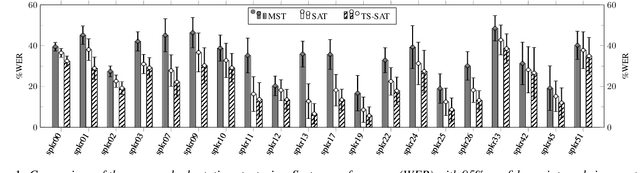
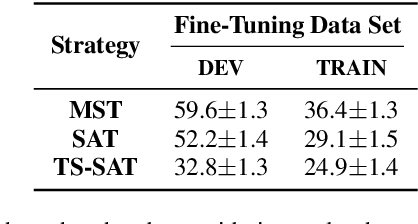
Different studies have shown the importance of visual cues throughout the speech perception process. In fact, the development of audiovisual approaches has led to advances in the field of speech technologies. However, although noticeable results have recently been achieved, visual speech recognition remains an open research problem. It is a task in which, by dispensing with the auditory sense, challenges such as visual ambiguities and the complexity of modeling silence must be faced. Nonetheless, some of these challenges can be alleviated when the problem is approached from a speaker-dependent perspective. Thus, this paper studies, using the Spanish LIP-RTVE database, how the estimation of specialized end-to-end systems for a specific person could affect the quality of speech recognition. First, different adaptation strategies based on the fine-tuning technique were proposed. Then, a pre-trained CTC/Attention architecture was used as a baseline throughout our experiments. Our findings showed that a two-step fine-tuning process, where the VSR system is first adapted to the task domain, provided significant improvements when the speaker adaptation was addressed. Furthermore, results comparable to the current state of the art were reached even when only a limited amount of data was available.
LIP-RTVE: An Audiovisual Database for Continuous Spanish in the Wild
Nov 21, 2023



Speech is considered as a multi-modal process where hearing and vision are two fundamentals pillars. In fact, several studies have demonstrated that the robustness of Automatic Speech Recognition systems can be improved when audio and visual cues are combined to represent the nature of speech. In addition, Visual Speech Recognition, an open research problem whose purpose is to interpret speech by reading the lips of the speaker, has been a focus of interest in the last decades. Nevertheless, in order to estimate these systems in the currently Deep Learning era, large-scale databases are required. On the other hand, while most of these databases are dedicated to English, other languages lack sufficient resources. Thus, this paper presents a semi-automatically annotated audiovisual database to deal with unconstrained natural Spanish, providing 13 hours of data extracted from Spanish television. Furthermore, baseline results for both speaker-dependent and speaker-independent scenarios are reported using Hidden Markov Models, a traditional paradigm that has been widely used in the field of Speech Technologies.
Analysis of Visual Features for Continuous Lipreading in Spanish
Nov 21, 2023



During a conversation, our brain is responsible for combining information obtained from multiple senses in order to improve our ability to understand the message we are perceiving. Different studies have shown the importance of presenting visual information in these situations. Nevertheless, lipreading is a complex task whose objective is to interpret speech when audio is not available. By dispensing with a sense as crucial as hearing, it will be necessary to be aware of the challenge that this lack presents. In this paper, we propose an analysis of different speech visual features with the intention of identifying which of them is the best approach to capture the nature of lip movements for natural Spanish and, in this way, dealing with the automatic visual speech recognition task. In order to estimate our system, we present an audiovisual corpus compiled from a subset of the RTVE database, which has been used in the Albayz\'in evaluations. We employ a traditional system based on Hidden Markov Models with Gaussian Mixture Models. Results show that, although the task is difficult, in restricted conditions we obtain recognition results which determine that using eigenlips in combination with deep features is the best visual approach.