 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting N-Gram Models: Their Impact in Modern Neural Networks for Handwritten Text Recognition
Apr 30, 2024
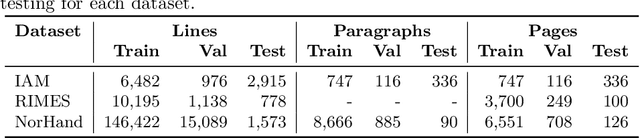

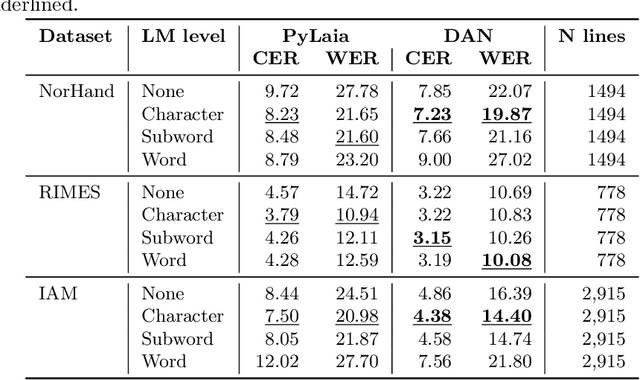
In recent advances in automatic text recognition (ATR), deep neural networks have demonstrated the ability to implicitly capture language statistics, potentially reducing the need for traditional language models. This study directly addresses whether explicit language models, specifically n-gram models, still contribute to the performance of state-of-the-art deep learning architectures in the field of handwriting recognition. We evaluate two prominent neural network architectures, PyLaia and DAN, with and without the integration of explicit n-gram language models. Our experiments on three datasets - IAM, RIMES, and NorHand v2 - at both line and page level, investigate optimal parameters for n-gram models, including their order, weight, smoothing methods and tokenization level. The results show that incorporating character or subword n-gram models significantly improves the performance of ATR models on all datasets, challenging the notion that deep learning models alone are sufficient for optimal performance. In particular, the combination of DAN with a character language model outperforms current benchmarks, confirming the value of hybrid approaches in modern document analysis systems.
Reading Order Independent Metrics for Information Extraction in Handwritten Documents
Apr 29, 2024



Information Extraction processes in handwritten documents tend to rely on obtaining an automatic transcription and performing Named Entity Recognition (NER) over such transcription. For this reason, in publicly available datasets, the performance of the systems is usually evaluated with metrics particular to each dataset. Moreover, most of the metrics employed are sensitive to reading order errors. Therefore, they do not reflect the expected final application of the system and introduce biases in more complex documents. In this paper, we propose and publicly release a set of reading order independent metrics tailored to Information Extraction evaluation in handwritten documents. In our experimentation, we perform an in-depth analysis of the behavior of the metrics to recommend what we consider to be the minimal set of metrics to evaluate a task correctly.
Improving Automatic Text Recognition with Language Models in the PyLaia Open-Source Library
Apr 29, 2024



PyLaia is one of the most popular open-source software for Automatic Text Recognition (ATR), delivering strong performance in terms of speed and accuracy. In this paper, we outline our recent contributions to the PyLaia library, focusing on the incorporation of reliable confidence scores and the integration of statistical language modeling during decoding. Our implementation provides an easy way to combine PyLaia with n-grams language models at different levels. One of the highlights of this work is that language models are completely auto-tuned: they can be built and used easily without any expert knowledge, and without requiring any additional data. To demonstrate the significance of our contribution, we evaluate PyLaia's performance on twelve datasets, both with and without language modelling. The results show that decoding with small language models improves the Word Error Rate by 13% and the Character Error Rate by 12% in average. Additionally, we conduct an analysis of confidence scores and highlight the importance of calibration techniques. Our implementation is publicly available in the official PyLaia repository at https://gitlab.teklia.com/atr/pylaia, and twelve open-source models are released on Hugging Face.
The Socface Project: Large-Scale Collection, Processing, and Analysis of a Century of French Censuses
Apr 29, 2024This paper presents a complete processing workflow for extracting information from French census lists from 1836 to 1936. These lists contain information about individuals living in France and their households. We aim at extracting all the information contained in these tables using automatic handwritten table recognition. At the end of the Socface project, in which our work is taking place, the extracted information will be redistributed to the departmental archives, and the nominative lists will be freely available to the public, allowing anyone to browse hundreds of millions of records. The extracted data will be used by demographers to analyze social change over time, significantly improving our understanding of French economic and social structures. For this project, we developed a complete processing workflow: large-scale data collection from French departmental archives, collaborative annotation of documents, training of handwritten table text and structure recognition models, and mass processing of millions of images. We present the tools we have developed to easily collect and process millions of pages. We also show that it is possible to process such a wide variety of tables with a single table recognition model that uses the image of the entire page to recognize information about individuals, categorize them and automatically group them into households. The entire process has been successfully used to process the documents of a departmental archive, representing more than 450,000 images.
Handwritten Text Recognition from Crowdsourced Annotations
Jun 19, 2023In this paper, we explore different ways of training a model for handwritten text recognition when multiple imperfect or noisy transcriptions are available. We consider various training configurations, such as selecting a single transcription, retaining all transcriptions, or computing an aggregated transcription from all available annotations. In addition, we evaluate the impact of quality-based data selection, where samples with low agreement are removed from the training set. Our experiments are carried out on municipal registers of the city of Belfort (France) written between 1790 and 1946. % results The results show that computing a consensus transcription or training on multiple transcriptions are good alternatives. However, selecting training samples based on the degree of agreement between annotators introduces a bias in the training data and does not improve the results. Our dataset is publicly available on Zenodo: https://zenodo.org/record/8041668.
Large Scale Genealogical Information Extraction From Handwritten Quebec Parish Records
Apr 27, 2023This paper presents a complete workflow designed for extracting information from Quebec handwritten parish registers. The acts in these documents contain individual and family information highly valuable for genetic, demographic and social studies of the Quebec population. From an image of parish records, our workflow is able to identify the acts and extract personal information. The workflow is divided into successive steps: page classification, text line detection, handwritten text recognition, named entity recognition and act detection and classification. For all these steps, different machine learning models are compared. Once the information is extracted, validation rules designed by experts are then applied to standardize the extracted information and ensure its consistency with the type of act (birth, marriage, and death). This validation step is able to reject records that are considered invalid or merged. The full workflow has been used to process over two million pages of Quebec parish registers from the 19-20th centuries. On a sample comprising 65% of registers, 3.2 million acts were recognized. Verification of the birth and death acts from this sample shows that 74% of them are considered complete and valid. These records will be integrated into the BALSAC database and linked together to recreate family and genealogical relations at large scale.
Key-value information extraction from full handwritten pages
Apr 26, 2023



We propose a Transformer-based approach for information extraction from digitized handwritten documents. Our approach combines, in a single model, the different steps that were so far performed by separate models: feature extraction, handwriting recognition and named entity recognition. We compare this integrated approach with traditional two-stage methods that perform handwriting recognition before named entity recognition, and present results at different levels: line, paragraph, and page. Our experiments show that attention-based models are especially interesting when applied on full pages, as they do not require any prior segmentation step. Finally, we show that they are able to learn from key-value annotations: a list of important words with their corresponding named entities. We compare our models to state-of-the-art methods on three public databases (IAM, ESPOSALLES, and POPP) and outperform previous performances on all three datasets.
SIMARA: a database for key-value information extraction from full pages
Apr 26, 2023



We propose a new database for information extraction from historical handwritten documents. The corpus includes 5,393 finding aids from six different series, dating from the 18th-20th centuries. Finding aids are handwritten documents that contain metadata describing older archives. They are stored in the National Archives of France and are used by archivists to identify and find archival documents. Each document is annotated at page-level, and contains seven fields to retrieve. The localization of each field is not available in such a way that this dataset encourages research on segmentation-free systems for information extraction. We propose a model based on the Transformer architecture trained for end-to-end information extraction and provide three sets for training, validation and testing, to ensure fair comparison with future works. The database is freely accessible at https://zenodo.org/record/7868059.