 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting N-Gram Models: Their Impact in Modern Neural Networks for Handwritten Text Recognition
Paper and Code

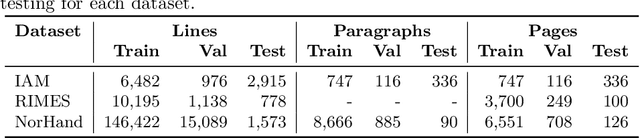

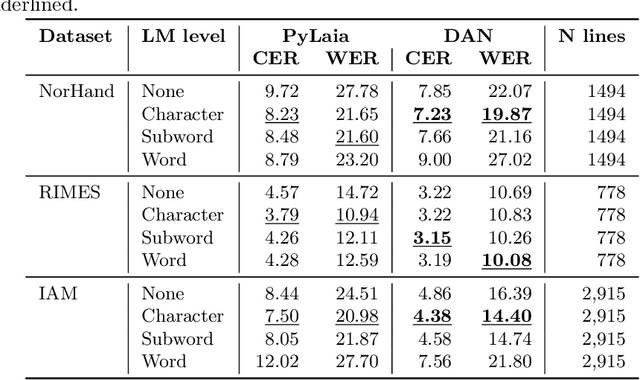
In recent advances in automatic text recognition (ATR), deep neural networks have demonstrated the ability to implicitly capture language statistics, potentially reducing the need for traditional language models. This study directly addresses whether explicit language models, specifically n-gram models, still contribute to the performance of state-of-the-art deep learning architectures in the field of handwriting recognition. We evaluate two prominent neural network architectures, PyLaia and DAN, with and without the integration of explicit n-gram language models. Our experiments on three datasets - IAM, RIMES, and NorHand v2 - at both line and page level, investigate optimal parameters for n-gram models, including their order, weight, smoothing methods and tokenization level. The results show that incorporating character or subword n-gram models significantly improves the performance of ATR models on all datasets, challenging the notion that deep learning models alone are sufficient for optimal performance. In particular, the combination of DAN with a character language model outperforms current benchmarks, confirming the value of hybrid approaches in modern document analysis systems.