 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the potential and limitations of Model Merging for Multi-Domain Adaptation in ASR
Mar 05, 2026Model merging is a scalable alternative to multi-task training that combines the capabilities of multiple specialised models into a single model. This is particularly attractive for large speech foundation models, which are typically adapted through domain-specific fine-tuning, resulting in multiple customised checkpoints, for which repeating full fine-tuning when new data becomes available is computationally prohibitive. In this work, we study model merging for multi-domain ASR and benchmark 11 merging algorithms for 10 European Portuguese domains, evaluating in-domain accuracy, robustness under distribution shift, as well as English and multilingual performance. We further propose BoostedTSV-M, a new merging algorithm based on TSV-M that mitigates rank collapse via singular-value boosting and improves numerical stability. Overall, our approach outperforms full fine-tuning on European Portuguese while preserving out-of-distribution generalisation in a single model.
CAMÕES: A Comprehensive Automatic Speech Recognition Benchmark for European Portuguese
Aug 27, 2025Existing resources for Automatic Speech Recognition in Portuguese are mostly focused on Brazilian Portuguese, leaving European Portuguese (EP) and other varieties under-explored. To bridge this gap, we introduce CAM\~OES, the first open framework for EP and other Portuguese varieties. It consists of (1) a comprehensive evaluation benchmark, including 46h of EP test data spanning multiple domains; and (2) a collection of state-of-the-art models. For the latter, we consider multiple foundation models, evaluating their zero-shot and fine-tuned performances, as well as E-Branchformer models trained from scratch. A curated set of 425h of EP was used for both fine-tuning and training. Our results show comparable performance for EP between fine-tuned foundation models and the E-Branchformer. Furthermore, the best-performing models achieve relative improvements above 35% WER, compared to the strongest zero-shot foundation model, establishing a new state-of-the-art for EP and other varieties.
On the Relevance of Clinical Assessment Tasks for the Automatic Detection of Parkinson's Disease Medication State from Speech
May 21, 2025The automatic identification of medication states of Parkinson's disease (PD) patients can assist clinicians in monitoring and scheduling personalized treatments, as well as studying the effects of medication in alleviating the motor symptoms that characterize the disease. This paper explores speech as a non-invasive and accessible biomarker for identifying PD medication states, introducing a novel approach that addresses this task from a speaker-independent perspective. While traditional machine learning models achieve competitive results, self-supervised speech representations prove essential for optimal performance, significantly surpassing knowledge-based acoustic descriptors. Experiments across diverse speech assessment tasks highlight the relevance of prosody and continuous speech in distinguishing medication states, reaching an F1-score of 88.2%. These findings may streamline clinicians' work and reduce patient effort in voice recordings.
Tackling Cognitive Impairment Detection from Speech: A submission to the PROCESS Challenge
Dec 30, 2024



This work describes our group's submission to the PROCESS Challenge 2024, with the goal of assessing cognitive decline through spontaneous speech, using three guided clinical tasks. This joint effort followed a holistic approach, encompassing both knowledge-based acoustic and text-based feature sets, as well as LLM-based macrolinguistic descriptors, pause-based acoustic biomarkers, and multiple neural representations (e.g., LongFormer, ECAPA-TDNN, and Trillson embeddings). Combining these feature sets with different classifiers resulted in a large pool of models, from which we selected those that provided the best balance between train, development, and individual class performance. Our results show that our best performing systems correspond to combinations of models that are complementary to each other, relying on acoustic and textual information from all three clinical tasks.
Unveiling Interpretability in Self-Supervised Speech Representations for Parkinson's Diagnosis
Dec 02, 2024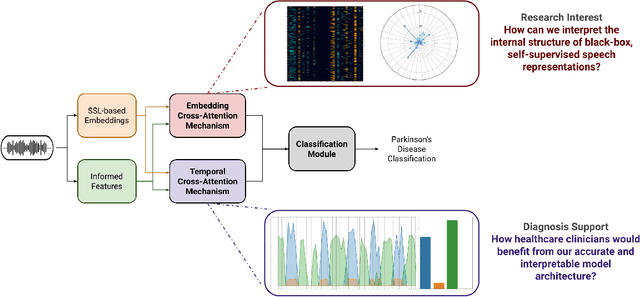
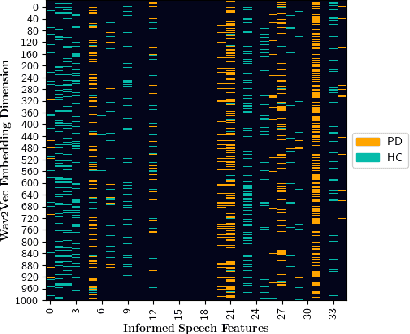
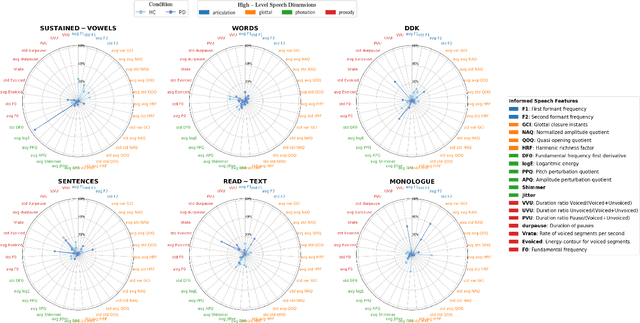
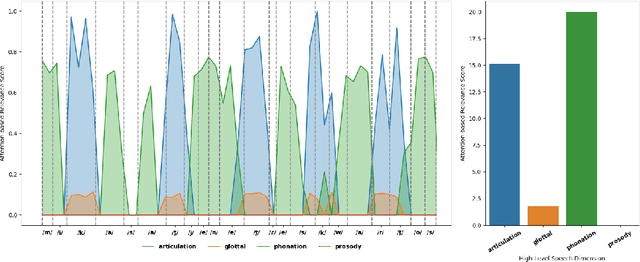
Recent works in pathological speech analysis have increasingly relied on powerful self-supervised speech representations, leading to promising results. However, the complex, black-box nature of these embeddings and the limited research on their interpretability significantly restrict their adoption for clinical diagnosis. To address this gap, we propose a novel, interpretable framework specifically designed to support Parkinson's Disease (PD) diagnosis. Through the design of simple yet effective cross-attention mechanisms for both embedding- and temporal-level analysis, the proposed framework offers interpretability from two distinct but complementary perspectives. Experimental findings across five well-established speech benchmarks for PD detection demonstrate the framework's capability to identify meaningful speech patterns within self-supervised representations for a wide range of assessment tasks. Fine-grained temporal analyses further underscore its potential to enhance the interpretability of deep-learning pathological speech models, paving the way for the development of more transparent, trustworthy, and clinically applicable computer-assisted diagnosis systems in this domain. Moreover, in terms of classification accuracy, our method achieves results competitive with state-of-the-art approaches, while also demonstrating robustness in cross-lingual scenarios when applied to spontaneous speech production.
AC-Mix: Self-Supervised Adaptation for Low-Resource Automatic Speech Recognition using Agnostic Contrastive Mixup
Oct 18, 2024Self-supervised learning (SSL) leverages large amounts of unlabelled data to learn rich speech representations, fostering improvements in automatic speech recognition (ASR), even when only a small amount of labelled data is available for fine-tuning. Despite the advances in SSL, a significant challenge remains when the data used for pre-training (source domain) mismatches the fine-tuning data (target domain). To tackle this domain mismatch challenge, we propose a new domain adaptation method for low-resource ASR focused on contrastive mixup for joint-embedding architectures named AC-Mix (agnostic contrastive mixup). In this approach, the SSL model is adapted through additional pre-training using mixed data views created by interpolating samples from the source and the target domains. Our proposed adaptation method consistently outperforms the baseline system, using approximately 11 hours of adaptation data and requiring only 1 hour of adaptation time on a single GPU with WavLM-Large.
Speech as a Biomarker for Disease Detection
Sep 16, 2024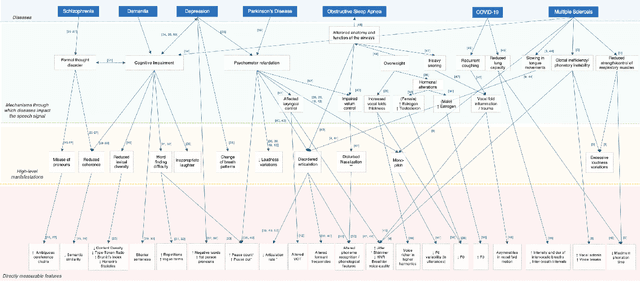
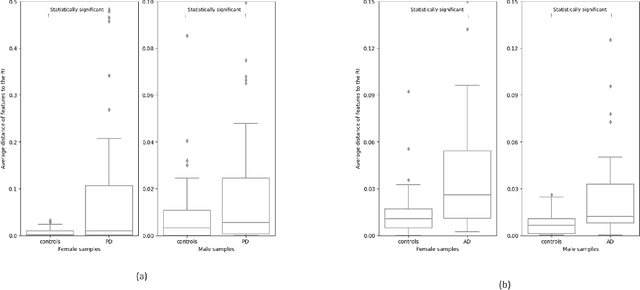

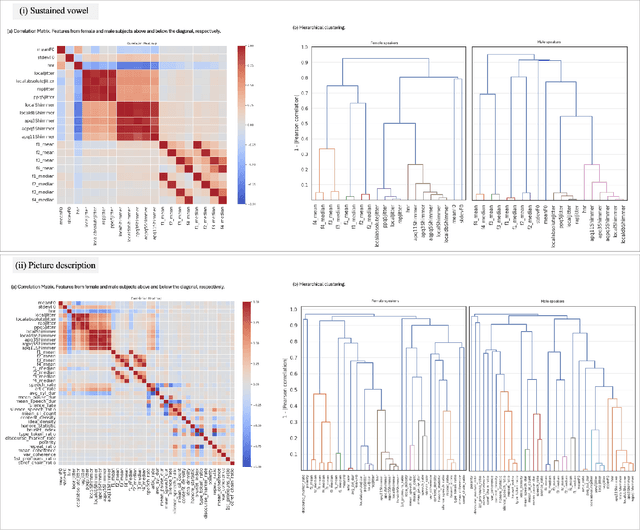
Speech is a rich biomarker that encodes substantial information about the health of a speaker, and thus it has been proposed for the detection of numerous diseases, achieving promising results. However, questions remain about what the models trained for the automatic detection of these diseases are actually learning and the basis for their predictions, which can significantly impact patients' lives. This work advocates for an interpretable health model, suitable for detecting several diseases, motivated by the observation that speech-affecting disorders often have overlapping effects on speech signals. A framework is presented that first defines "reference speech" and then leverages this definition for disease detection. Reference speech is characterized through reference intervals, i.e., the typical values of clinically meaningful acoustic and linguistic features derived from a reference population. This novel approach in the field of speech as a biomarker is inspired by the use of reference intervals in clinical laboratory science. Deviations of new speakers from this reference model are quantified and used as input to detect Alzheimer's and Parkinson's disease. The classification strategy explored is based on Neural Additive Models, a type of glass-box neural network, which enables interpretability. The proposed framework for reference speech characterization and disease detection is designed to support the medical community by providing clinically meaningful explanations that can serve as a valuable second opinion.
Improving Membership Inference in ASR Model Auditing with Perturbed Loss Features
May 02, 2024Membership Inference (MI) poses a substantial privacy threat to the training data of Automatic Speech Recognition (ASR) systems, while also offering an opportunity to audit these models with regard to user data. This paper explores the effectiveness of loss-based features in combination with Gaussian and adversarial perturbations to perform MI in ASR models. To the best of our knowledge, this approach has not yet been investigated. We compare our proposed features with commonly used error-based features and find that the proposed features greatly enhance performance for sample-level MI. For speaker-level MI, these features improve results, though by a smaller margin, as error-based features already obtained a high performance for this task. Our findings emphasise the importance of considering different feature sets and levels of access to target models for effective MI in ASR systems, providing valuable insights for auditing such models.
Privacy-oriented manipulation of speaker representations
Oct 10, 2023



Speaker embeddings are ubiquitous, with applications ranging from speaker recognition and diarization to speech synthesis and voice anonymisation. The amount of information held by these embeddings lends them versatility, but also raises privacy concerns. Speaker embeddings have been shown to contain information on age, sex, health and more, which speakers may want to keep private, especially when this information is not required for the target task. In this work, we propose a method for removing and manipulating private attributes from speaker embeddings that leverages a Vector-Quantized Variational Autoencoder architecture, combined with an adversarial classifier and a novel mutual information loss. We validate our model on two attributes, sex and age, and perform experiments with ignorant and fully-informed attackers, and with in-domain and out-of-domain data.
Memory-augmented conformer for improved end-to-end long-form ASR
Sep 22, 2023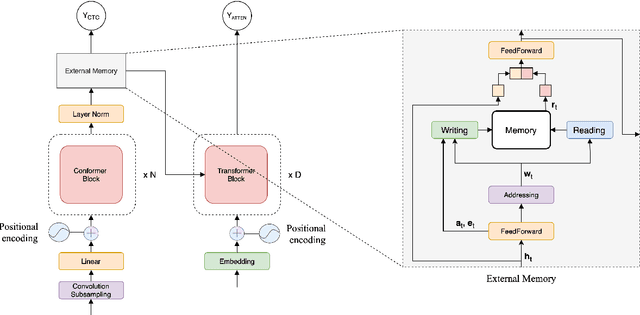
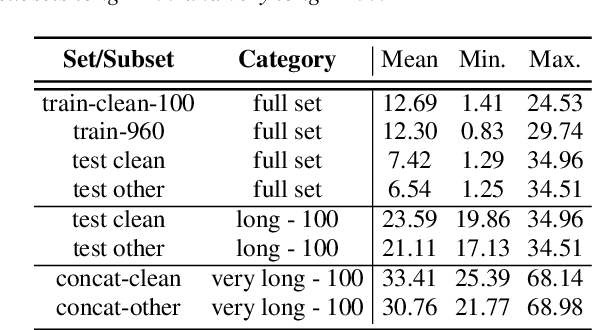
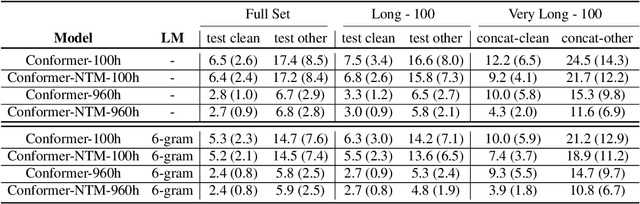
Conformers have recently been proposed as a promising modelling approach for automatic speech recognition (ASR), outperforming recurrent neural network-based approaches and transformers. Nevertheless, in general, the performance of these end-to-end models, especially attention-based models, is particularly degraded in the case of long utterances. To address this limitation, we propose adding a fully-differentiable memory-augmented neural network between the encoder and decoder of a conformer. This external memory can enrich the generalization for longer utterances since it allows the system to store and retrieve more information recurrently. Notably, we explore the neural Turing machine (NTM) that results in our proposed Conformer-NTM model architecture for ASR. Experimental results using Librispeech train-clean-100 and train-960 sets show that the proposed system outperforms the baseline conformer without memory for long utterances.