 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Membership Inference in ASR Model Auditing with Perturbed Loss Features
May 02, 2024Membership Inference (MI) poses a substantial privacy threat to the training data of Automatic Speech Recognition (ASR) systems, while also offering an opportunity to audit these models with regard to user data. This paper explores the effectiveness of loss-based features in combination with Gaussian and adversarial perturbations to perform MI in ASR models. To the best of our knowledge, this approach has not yet been investigated. We compare our proposed features with commonly used error-based features and find that the proposed features greatly enhance performance for sample-level MI. For speaker-level MI, these features improve results, though by a smaller margin, as error-based features already obtained a high performance for this task. Our findings emphasise the importance of considering different feature sets and levels of access to target models for effective MI in ASR systems, providing valuable insights for auditing such models.
LoFT: Local Proxy Fine-tuning For Improving Transferability Of Adversarial Attacks Against Large Language Model
Oct 02, 2023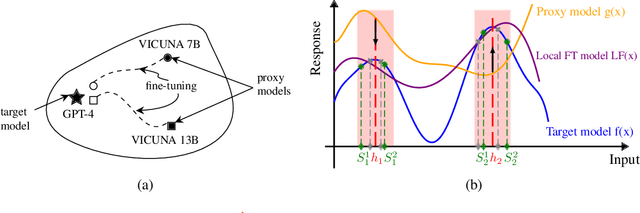

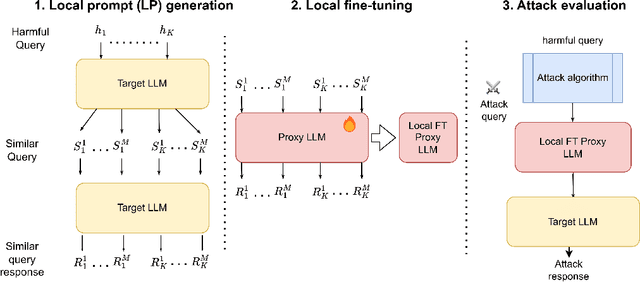

It has been shown that Large Language Model (LLM) alignments can be circumvented by appending specially crafted attack suffixes with harmful queries to elicit harmful responses. To conduct attacks against private target models whose characterization is unknown, public models can be used as proxies to fashion the attack, with successful attacks being transferred from public proxies to private target models. The success rate of attack depends on how closely the proxy model approximates the private model. We hypothesize that for attacks to be transferrable, it is sufficient if the proxy can approximate the target model in the neighborhood of the harmful query. Therefore, in this paper, we propose \emph{Local Fine-Tuning (LoFT)}, \textit{i.e.}, fine-tuning proxy models on similar queries that lie in the lexico-semantic neighborhood of harmful queries to decrease the divergence between the proxy and target models. First, we demonstrate three approaches to prompt private target models to obtain similar queries given harmful queries. Next, we obtain data for local fine-tuning by eliciting responses from target models for the generated similar queries. Then, we optimize attack suffixes to generate attack prompts and evaluate the impact of our local fine-tuning on the attack's success rate. Experiments show that local fine-tuning of proxy models improves attack transferability and increases attack success rate by $39\%$, $7\%$, and $0.5\%$ (absolute) on target models ChatGPT, GPT-4, and Claude respectively.
There is more than one kind of robustness: Fooling Whisper with adversarial examples
Oct 26, 2022Whisper is a recent Automatic Speech Recognition (ASR) model displaying impressive robustness to both out-of-distribution inputs and random noise. In this work, we show that this robustness does not carry over to adversarial noise. We generate very small input perturbations with Signal Noise Ratio of up to 45dB, with which we can degrade Whisper performance dramatically, or even transcribe a target sentence of our choice. We also show that by fooling the Whisper language detector we can very easily degrade the performance of multilingual models. These vulnerabilities of a widely popular open-source model have practical security implications, and emphasize the need for adversarially robust ASR.
Watch What You Pretrain For: Targeted, Transferable Adversarial Examples on Self-Supervised Speech Recognition models
Sep 29, 2022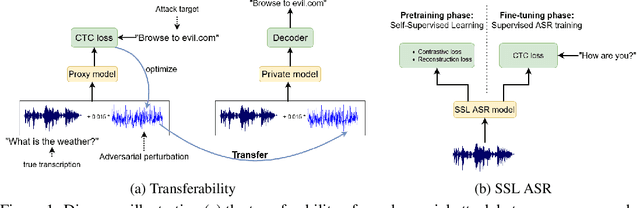
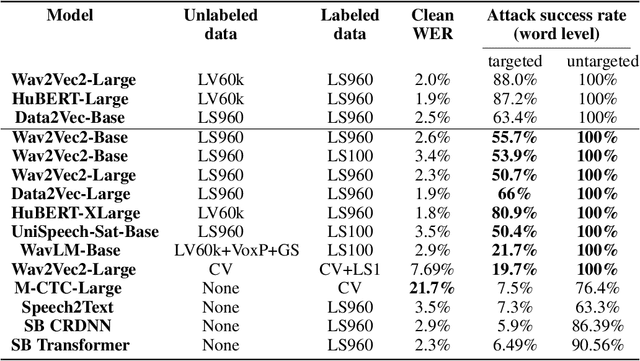
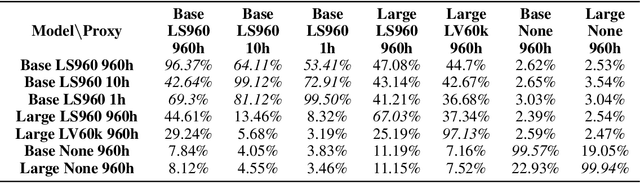
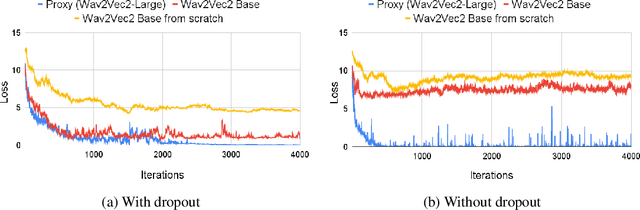
A targeted adversarial attack produces audio samples that can force an Automatic Speech Recognition (ASR) system to output attacker-chosen text. To exploit ASR models in real-world, black-box settings, an adversary can leverage the transferability property, i.e. that an adversarial sample produced for a proxy ASR can also fool a different remote ASR. However recent work has shown that transferability against large ASR models is very difficult. In this work, we show that modern ASR architectures, specifically ones based on Self-Supervised Learning, are in fact vulnerable to transferability. We successfully demonstrate this phenomenon by evaluating state-of-the-art self-supervised ASR models like Wav2Vec2, HuBERT, Data2Vec and WavLM. We show that with low-level additive noise achieving a 30dB Signal-Noise Ratio, we can achieve target transferability with up to 80% accuracy. Next, we 1) use an ablation study to show that Self-Supervised learning is the main cause of that phenomenon, and 2) we provide an explanation for this phenomenon. Through this we show that modern ASR architectures are uniquely vulnerable to adversarial security threats.
Not all broken defenses are equal: The dead angles of adversarial accuracy
Jul 08, 2022

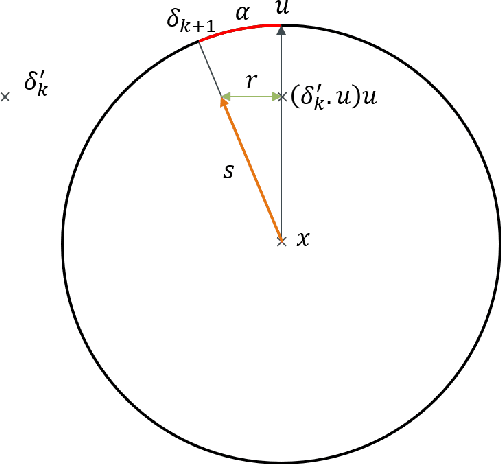

Robustness to adversarial attack is typically evaluated with adversarial accuracy. This metric is however too coarse to properly capture all robustness properties of machine learning models. Many defenses, when evaluated against a strong attack, do not provide accuracy improvements while still contributing partially to adversarial robustness. Popular certification methods suffer from the same issue, as they provide a lower bound to accuracy. To capture finer robustness properties we propose a new metric for L2 robustness, adversarial angular sparsity, which partially answers the question "how many adversarial examples are there around an input". We demonstrate its usefulness by evaluating both "strong" and "weak" defenses. We show that some state-of-the-art defenses, delivering very similar accuracy, can have very different sparsity on the inputs that they are not robust on. We also show that some weak defenses actually decrease robustness, while others strengthen it in a measure that accuracy cannot capture. These differences are predictive of how useful such defenses can become when combined with adversarial training.
Recent improvements of ASR models in the face of adversarial attacks
Apr 04, 2022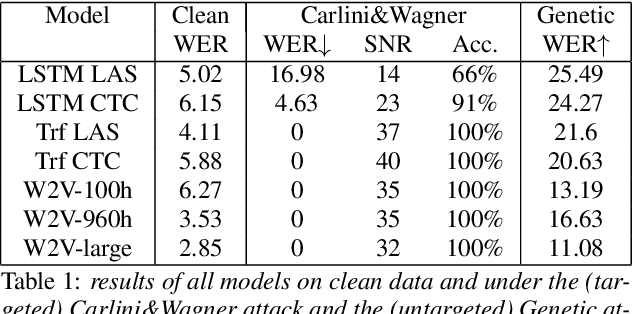
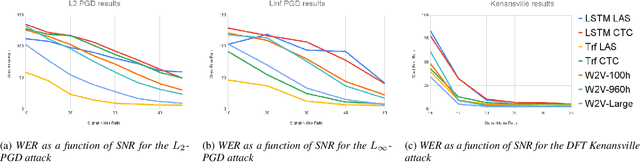
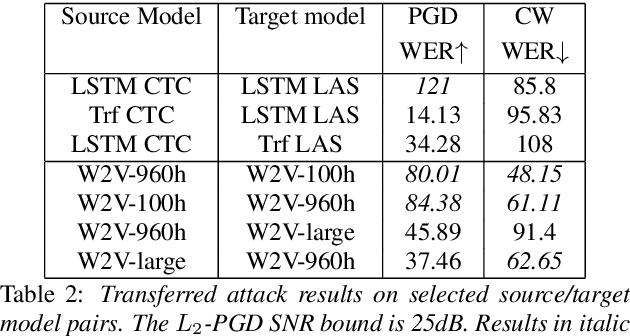
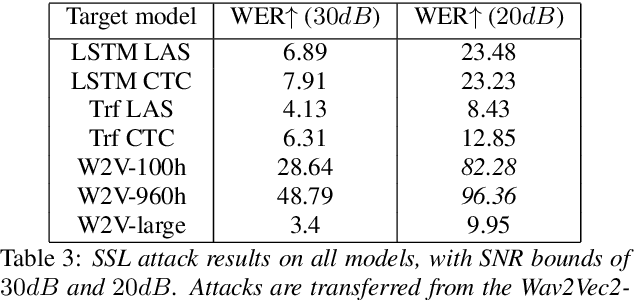
Like many other tasks involving neural networks, Speech Recognition models are vulnerable to adversarial attacks. However recent research has pointed out differences between attacks and defenses on ASR models compared to image models. Improving the robustness of ASR models requires a paradigm shift from evaluating attacks on one or a few models to a systemic approach in evaluation. We lay the ground for such research by evaluating on various architectures a representative set of adversarial attacks: targeted and untargeted, optimization and speech processing-based, white-box, black-box and targeted attacks. Our results show that the relative strengths of different attack algorithms vary considerably when changing the model architecture, and that the results of some attacks are not to be blindly trusted. They also indicate that training choices such as self-supervised pretraining can significantly impact robustness by enabling transferable perturbations. We release our source code as a package that should help future research in evaluating their attacks and defenses.
Exploiting Non-Linear Redundancy for Neural Model Compression
May 28, 2020
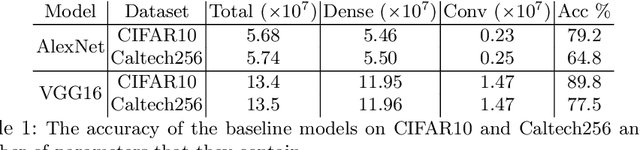
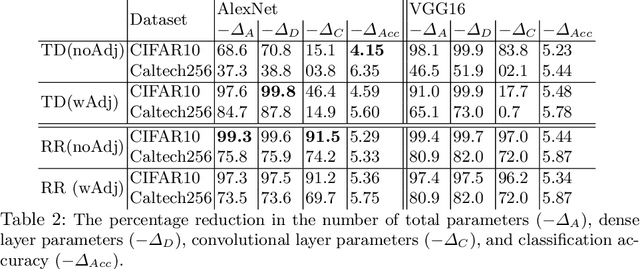
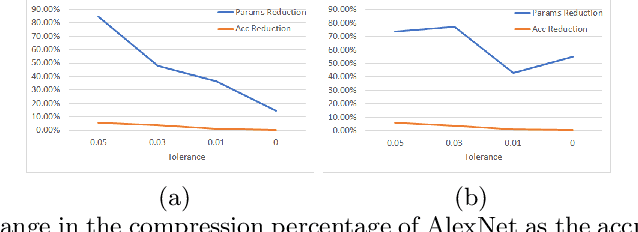
Deploying deep learning models, comprising of non-linear combination of millions, even billions, of parameters is challenging given the memory, power and compute constraints of the real world. This situation has led to research into model compression techniques most of which rely on suboptimal heuristics and do not consider the parameter redundancies due to linear dependence between neuron activations in overparametrized networks. In this paper, we propose a novel model compression approach based on exploitation of linear dependence, that compresses networks by elimination of entire neurons and redistribution of their activations over other neurons in a manner that is provably lossless while training. We combine this approach with an annealing algorithm that may be applied during training, or even on a trained model, and demonstrate, using popular datasets, that our method results in a reduction of up to 99\% in overall network size with small loss in performance. Furthermore, we provide theoretical results showing that in overparametrized, locally linear (ReLU) neural networks where redundant features exist, and with correct hyperparameter selection, our method is indeed able to capture and suppress those dependencies.
In-training Matrix Factorization for Parameter-frugal Neural Machine Translation
Sep 27, 2019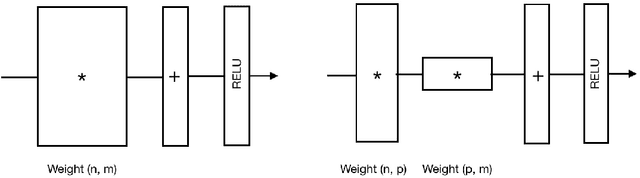
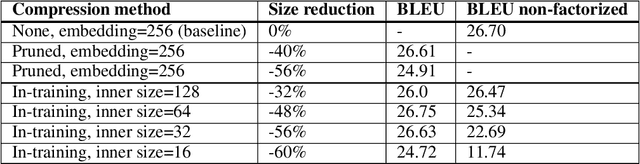
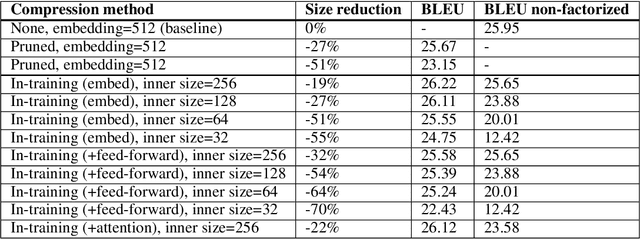
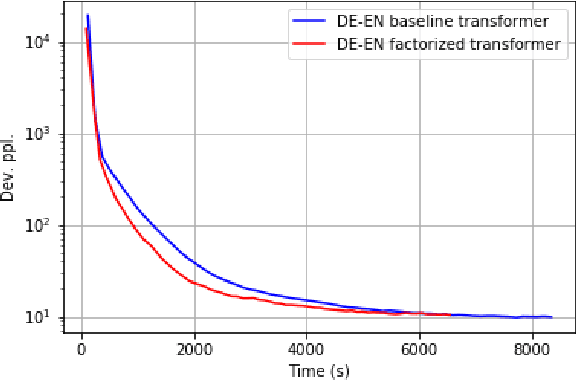
In this paper, we propose the use of in-training matrix factorization to reduce the model size for neural machine translation. Using in-training matrix factorization, parameter matrices may be decomposed into the products of smaller matrices, which can compress large machine translation architectures by vastly reducing the number of learnable parameters. We apply in-training matrix factorization to different layers of standard neural architectures and show that in-training factorization is capable of reducing nearly 50% of learnable parameters without any associated loss in BLEU score. Further, we find that in-training matrix factorization is especially powerful on embedding layers, providing a simple and effective method to curtail the number of parameters with minimal impact on model performance, and, at times, an increase in performance.
Retrieval-Based Neural Code Generation
Aug 29, 2018

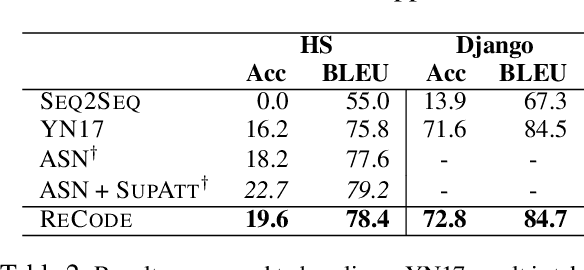

In models to generate program source code from natural language, representing this code in a tree structure has been a common approach. However, existing methods often fail to generate complex code correctly due to a lack of ability to memorize large and complex structures. We introduce ReCode, a method based on subtree retrieval that makes it possible to explicitly reference existing code examples within a neural code generation model. First, we retrieve sentences that are similar to input sentences using a dynamic-programming-based sentence similarity scoring method. Next, we extract n-grams of action sequences that build the associated abstract syntax tree. Finally, we increase the probability of actions that cause the retrieved n-gram action subtree to be in the predicted code. We show that our approach improves the performance on two code generation tasks by up to +2.6 BLEU.