 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatch What You Pretrain For: Targeted, Transferable Adversarial Examples on Self-Supervised Speech Recognition models
Paper and Code
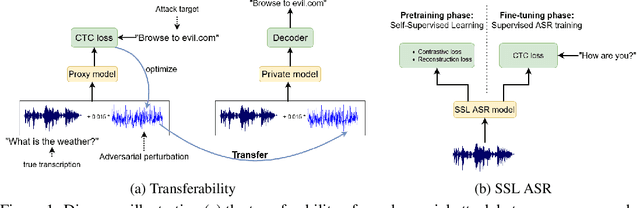
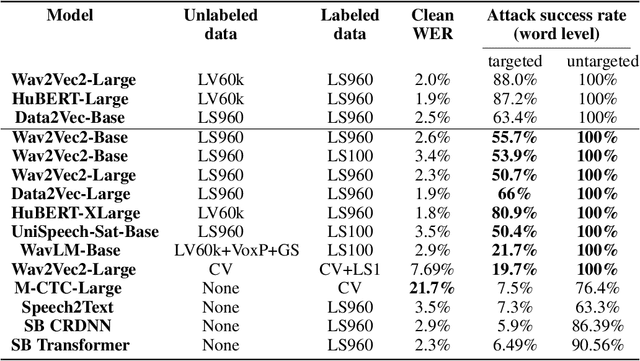
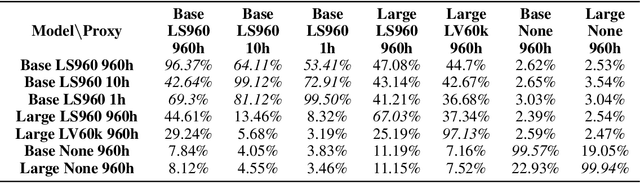
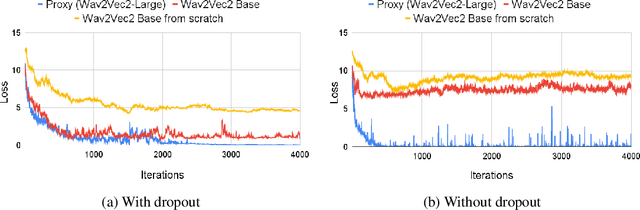
A targeted adversarial attack produces audio samples that can force an Automatic Speech Recognition (ASR) system to output attacker-chosen text. To exploit ASR models in real-world, black-box settings, an adversary can leverage the transferability property, i.e. that an adversarial sample produced for a proxy ASR can also fool a different remote ASR. However recent work has shown that transferability against large ASR models is very difficult. In this work, we show that modern ASR architectures, specifically ones based on Self-Supervised Learning, are in fact vulnerable to transferability. We successfully demonstrate this phenomenon by evaluating state-of-the-art self-supervised ASR models like Wav2Vec2, HuBERT, Data2Vec and WavLM. We show that with low-level additive noise achieving a 30dB Signal-Noise Ratio, we can achieve target transferability with up to 80% accuracy. Next, we 1) use an ablation study to show that Self-Supervised learning is the main cause of that phenomenon, and 2) we provide an explanation for this phenomenon. Through this we show that modern ASR architectures are uniquely vulnerable to adversarial security threats.