 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-training Matrix Factorization for Parameter-frugal Neural Machine Translation
Paper and Code
Sep 27, 2019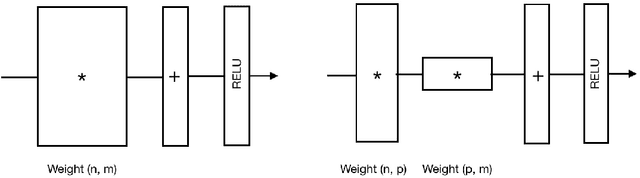
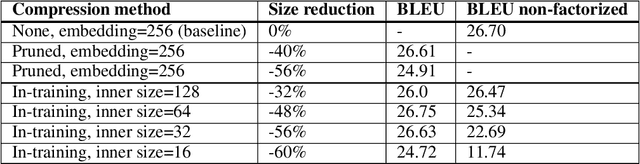
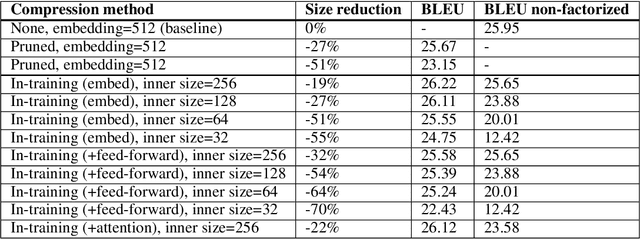
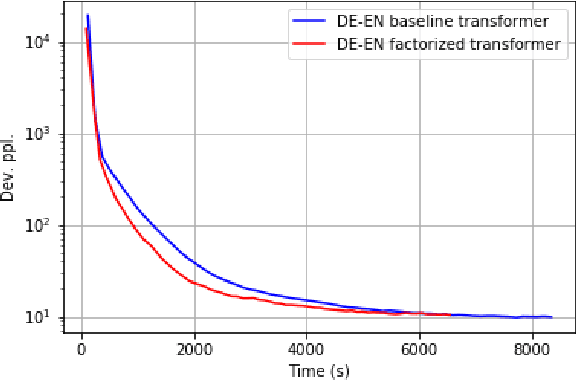
In this paper, we propose the use of in-training matrix factorization to reduce the model size for neural machine translation. Using in-training matrix factorization, parameter matrices may be decomposed into the products of smaller matrices, which can compress large machine translation architectures by vastly reducing the number of learnable parameters. We apply in-training matrix factorization to different layers of standard neural architectures and show that in-training factorization is capable of reducing nearly 50% of learnable parameters without any associated loss in BLEU score. Further, we find that in-training matrix factorization is especially powerful on embedding layers, providing a simple and effective method to curtail the number of parameters with minimal impact on model performance, and, at times, an increase in performance.