 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot all broken defenses are equal: The dead angles of adversarial accuracy
Paper and Code


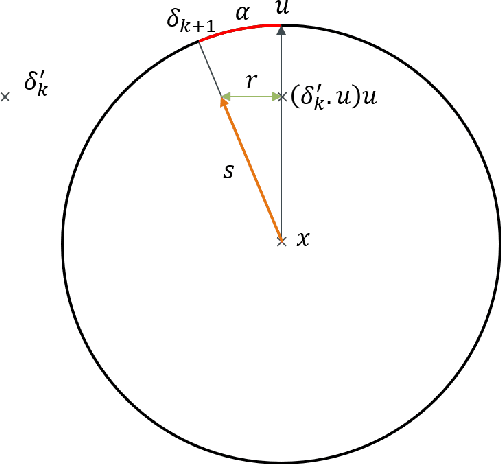

Robustness to adversarial attack is typically evaluated with adversarial accuracy. This metric is however too coarse to properly capture all robustness properties of machine learning models. Many defenses, when evaluated against a strong attack, do not provide accuracy improvements while still contributing partially to adversarial robustness. Popular certification methods suffer from the same issue, as they provide a lower bound to accuracy. To capture finer robustness properties we propose a new metric for L2 robustness, adversarial angular sparsity, which partially answers the question "how many adversarial examples are there around an input". We demonstrate its usefulness by evaluating both "strong" and "weak" defenses. We show that some state-of-the-art defenses, delivering very similar accuracy, can have very different sparsity on the inputs that they are not robust on. We also show that some weak defenses actually decrease robustness, while others strengthen it in a measure that accuracy cannot capture. These differences are predictive of how useful such defenses can become when combined with adversarial training.