 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplay Attacks Against Audio Deepfake Detection
May 20, 2025

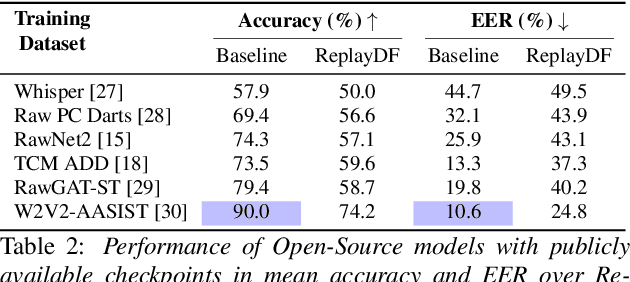
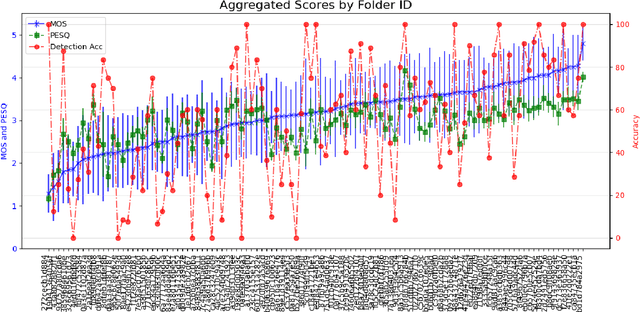
We show how replay attacks undermine audio deepfake detection: By playing and re-recording deepfake audio through various speakers and microphones, we make spoofed samples appear authentic to the detection model. To study this phenomenon in more detail, we introduce ReplayDF, a dataset of recordings derived from M-AILABS and MLAAD, featuring 109 speaker-microphone combinations across six languages and four TTS models. It includes diverse acoustic conditions, some highly challenging for detection. Our analysis of six open-source detection models across five datasets reveals significant vulnerability, with the top-performing W2V2-AASIST model's Equal Error Rate (EER) surging from 4.7% to 18.2%. Even with adaptive Room Impulse Response (RIR) retraining, performance remains compromised with an 11.0% EER. We release ReplayDF for non-commercial research use.
Reassessing Noise Augmentation Methods in the Context of Adversarial Speech
Sep 03, 2024In this study, we investigate if noise-augmented training can concurrently improve adversarial robustness in automatic speech recognition (ASR) systems. We conduct a comparative analysis of the adversarial robustness of four different state-of-the-art ASR architectures, where each of the ASR architectures is trained under three different augmentation conditions: one subject to background noise, speed variations, and reverberations, another subject to speed variations only, and a third without any form of data augmentation. The results demonstrate that noise augmentation not only improves model performance on noisy speech but also the model's robustness to adversarial attacks.
Improving Membership Inference in ASR Model Auditing with Perturbed Loss Features
May 02, 2024Membership Inference (MI) poses a substantial privacy threat to the training data of Automatic Speech Recognition (ASR) systems, while also offering an opportunity to audit these models with regard to user data. This paper explores the effectiveness of loss-based features in combination with Gaussian and adversarial perturbations to perform MI in ASR models. To the best of our knowledge, this approach has not yet been investigated. We compare our proposed features with commonly used error-based features and find that the proposed features greatly enhance performance for sample-level MI. For speaker-level MI, these features improve results, though by a smaller margin, as error-based features already obtained a high performance for this task. Our findings emphasise the importance of considering different feature sets and levels of access to target models for effective MI in ASR systems, providing valuable insights for auditing such models.
Exploratory Evaluation of Speech Content Masking
Jan 08, 2024Most recent speech privacy efforts have focused on anonymizing acoustic speaker attributes but there has not been as much research into protecting information from speech content. We introduce a toy problem that explores an emerging type of privacy called "content masking" which conceals selected words and phrases in speech. In our efforts to define this problem space, we evaluate an introductory baseline masking technique based on modifying sequences of discrete phone representations (phone codes) produced from a pre-trained vector-quantized variational autoencoder (VQ-VAE) and re-synthesized using WaveRNN. We investigate three different masking locations and three types of masking strategies: noise substitution, word deletion, and phone sequence reversal. Our work attempts to characterize how masking affects two downstream tasks: automatic speech recognition (ASR) and automatic speaker verification (ASV). We observe how the different masks types and locations impact these downstream tasks and discuss how these issues may influence privacy goals.
An Integrated Algorithm for Robust and Imperceptible Audio Adversarial Examples
Oct 05, 2023Audio adversarial examples are audio files that have been manipulated to fool an automatic speech recognition (ASR) system, while still sounding benign to a human listener. Most methods to generate such samples are based on a two-step algorithm: first, a viable adversarial audio file is produced, then, this is fine-tuned with respect to perceptibility and robustness. In this work, we present an integrated algorithm that uses psychoacoustic models and room impulse responses (RIR) in the generation step. The RIRs are dynamically created by a neural network during the generation process to simulate a physical environment to harden our examples against transformations experienced in over-the-air attacks. We compare the different approaches in three experiments: in a simulated environment and in a realistic over-the-air scenario to evaluate the robustness, and in a human study to evaluate the perceptibility. Our algorithms considering psychoacoustics only or in addition to the robustness show an improvement in the signal-to-noise ratio (SNR) as well as in the human perception study, at the cost of an increased word error rate (WER).
New Challenges for Content Privacy in Speech and Audio
Jan 21, 2023Privacy in speech and audio has many facets. A particularly under-developed area of privacy in this domain involves consideration for information related to content and context. Speech content can include words and their meaning or even stylistic markers, pathological speech, intonation patterns, or emotion. More generally, audio captured in-the-wild may contain background speech or reveal contextual information such as markers of location, room characteristics, paralinguistic sounds, or other audible events. Audio recording devices and speech technologies are becoming increasingly commonplace in everyday life. At the same time, commercialised speech and audio technologies do not provide consumers with a range of privacy choices. Even where privacy is regulated or protected by law, technical solutions to privacy assurance and enforcement fall short. This position paper introduces three important and timely research challenges for content privacy in speech and audio. We highlight current gaps and opportunities, and identify focus areas, that could have significant implications for developing ethical and safer speech technologies.
Introducing Model Inversion Attacks on Automatic Speaker Recognition
Jan 09, 2023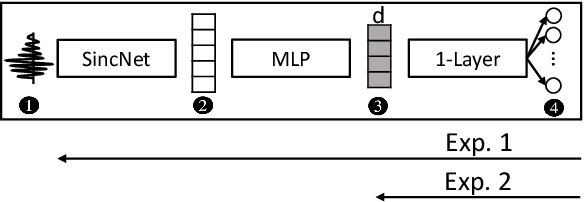
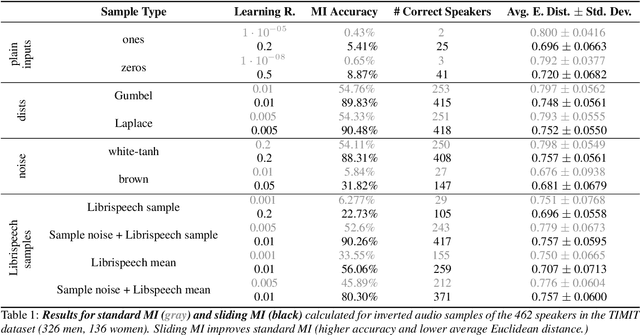
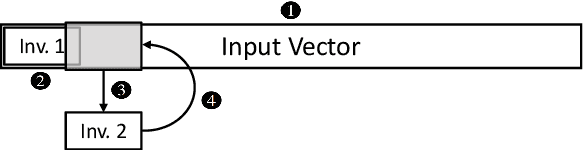
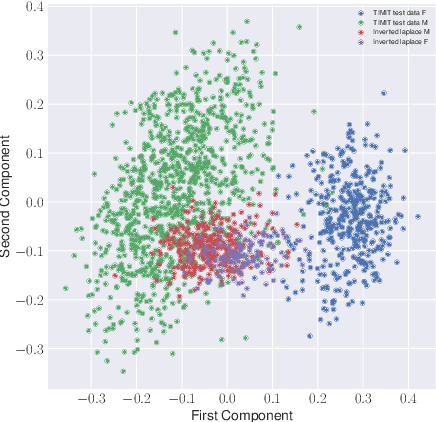
Model inversion (MI) attacks allow to reconstruct average per-class representations of a machine learning (ML) model's training data. It has been shown that in scenarios where each class corresponds to a different individual, such as face classifiers, this represents a severe privacy risk. In this work, we explore a new application for MI: the extraction of speakers' voices from a speaker recognition system. We present an approach to (1) reconstruct audio samples from a trained ML model and (2) extract intermediate voice feature representations which provide valuable insights into the speakers' biometrics. Therefore, we propose an extension of MI attacks which we call sliding model inversion. Our sliding MI extends standard MI by iteratively inverting overlapping chunks of the audio samples and thereby leveraging the sequential properties of audio data for enhanced inversion performance. We show that one can use the inverted audio data to generate spoofed audio samples to impersonate a speaker, and execute voice-protected commands for highly secured systems on their behalf. To the best of our knowledge, our work is the first one extending MI attacks to audio data, and our results highlight the security risks resulting from the extraction of the biometric data in that setup.
* for associated pdf, see https://www.isca-speech.org/archive/pdfs/spsc_2022/pizzi22_spsc.pdf