 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFalAR: A Large-scale Speaker-Annotated European Portuguese Speech Corpus of Parliamentary Sessions
May 26, 2026State-of-the-art performance for Automatic Speech Recognition (ASR) largely depends on the availability of large-scale labeled corpora. This creates a demand for increased data collection efforts, particularly for under-represented languages and dialectal varieties. Due to having considerably fewer speakers (around 11 million), European Portuguese (EP) is overshadowed by Brazilian Portuguese (BP) (around 200 million speakers) in currently available large-scale speech data resources, resulting in under-performing speech-based systems for EP users. To address this gap, and following similar data collection efforts for other languages, we present FalAR, a large-scale, speaker-annotated speech corpus of European Portuguese parliamentary sessions. Spanning approximately 20 years, FalAR comprises 5,800 hours of speech data. In addition, 4,850 hours have speaker identity annotations, for a total of 1,180 speakers with associated metadata including age, gender, political affiliation, and parliamentary role. The corpus was built using a state-of-the-art EP CAMÕES ASR model for transcription-reference alignment. In this paper, we describe the data collection process, together with the main characteristics of the FalAR corpus. Furthermore, we evaluate the trade-off between data quantity and alignment accuracy on ASR performance, with our experiments demonstrating that incorporating FalAR as pre-training data yields up to 14% relative WER improvement over baseline models.
CAMÕES: A Comprehensive Automatic Speech Recognition Benchmark for European Portuguese
Aug 27, 2025Existing resources for Automatic Speech Recognition in Portuguese are mostly focused on Brazilian Portuguese, leaving European Portuguese (EP) and other varieties under-explored. To bridge this gap, we introduce CAM\~OES, the first open framework for EP and other Portuguese varieties. It consists of (1) a comprehensive evaluation benchmark, including 46h of EP test data spanning multiple domains; and (2) a collection of state-of-the-art models. For the latter, we consider multiple foundation models, evaluating their zero-shot and fine-tuned performances, as well as E-Branchformer models trained from scratch. A curated set of 425h of EP was used for both fine-tuning and training. Our results show comparable performance for EP between fine-tuned foundation models and the E-Branchformer. Furthermore, the best-performing models achieve relative improvements above 35% WER, compared to the strongest zero-shot foundation model, establishing a new state-of-the-art for EP and other varieties.
MEDAL: A Framework for Benchmarking LLMs as Multilingual Open-Domain Chatbots and Dialogue Evaluators
May 28, 2025As the capabilities of chatbots and their underlying LLMs continue to dramatically improve, evaluating their performance has increasingly become a major blocker to their further development. A major challenge is the available benchmarking datasets, which are largely static, outdated, and lacking in multilingual coverage, limiting their ability to capture subtle linguistic and cultural variations. This paper introduces MEDAL, an automated multi-agent framework for generating, evaluating, and curating more representative and diverse open-domain dialogue evaluation benchmarks. Our approach leverages several state-of-the-art LLMs to generate user-chatbot multilingual dialogues, conditioned on varied seed contexts. A strong LLM (GPT-4.1) is then used for a multidimensional analysis of the performance of the chatbots, uncovering noticeable cross-lingual performance differences. Guided by this large-scale evaluation, we curate a new meta-evaluation multilingual benchmark and human-annotate samples with nuanced quality judgments. This benchmark is then used to assess the ability of several reasoning and non-reasoning LLMs to act as evaluators of open-domain dialogues. We find that current LLMs struggle to detect nuanced issues, particularly those involving empathy and reasoning.
Unveiling Biases while Embracing Sustainability: Assessing the Dual Challenges of Automatic Speech Recognition Systems
Mar 02, 2025In this paper, we present a bias and sustainability focused investigation of Automatic Speech Recognition (ASR) systems, namely Whisper and Massively Multilingual Speech (MMS), which have achieved state-of-the-art (SOTA) performances. Despite their improved performance in controlled settings, there remains a critical gap in understanding their efficacy and equity in real-world scenarios. We analyze ASR biases w.r.t. gender, accent, and age group, as well as their effect on downstream tasks. In addition, we examine the environmental impact of ASR systems, scrutinizing the use of large acoustic models on carbon emission and energy consumption. We also provide insights into our empirical analyses, offering a valuable contribution to the claims surrounding bias and sustainability in ASR systems.
Tackling Cognitive Impairment Detection from Speech: A submission to the PROCESS Challenge
Dec 30, 2024



This work describes our group's submission to the PROCESS Challenge 2024, with the goal of assessing cognitive decline through spontaneous speech, using three guided clinical tasks. This joint effort followed a holistic approach, encompassing both knowledge-based acoustic and text-based feature sets, as well as LLM-based macrolinguistic descriptors, pause-based acoustic biomarkers, and multiple neural representations (e.g., LongFormer, ECAPA-TDNN, and Trillson embeddings). Combining these feature sets with different classifiers resulted in a large pool of models, from which we selected those that provided the best balance between train, development, and individual class performance. Our results show that our best performing systems correspond to combinations of models that are complementary to each other, relying on acoustic and textual information from all three clinical tasks.
Speech as a Biomarker for Disease Detection
Sep 16, 2024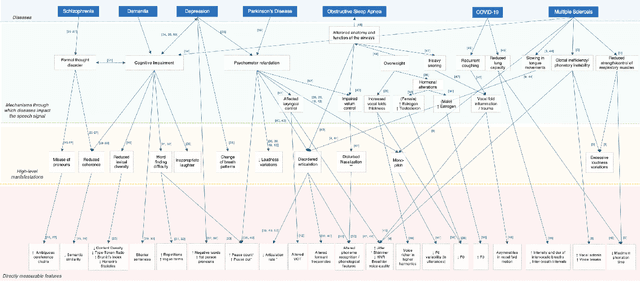
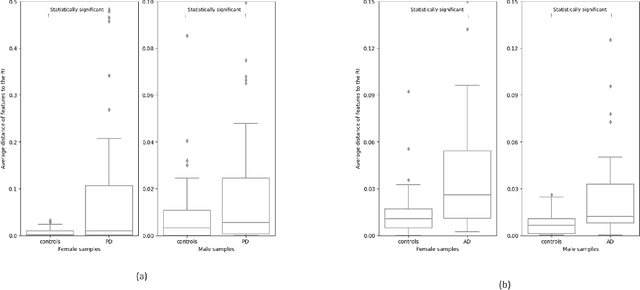

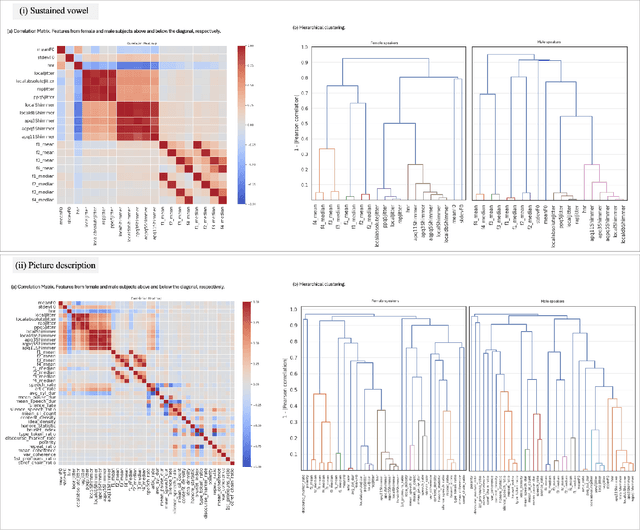
Speech is a rich biomarker that encodes substantial information about the health of a speaker, and thus it has been proposed for the detection of numerous diseases, achieving promising results. However, questions remain about what the models trained for the automatic detection of these diseases are actually learning and the basis for their predictions, which can significantly impact patients' lives. This work advocates for an interpretable health model, suitable for detecting several diseases, motivated by the observation that speech-affecting disorders often have overlapping effects on speech signals. A framework is presented that first defines "reference speech" and then leverages this definition for disease detection. Reference speech is characterized through reference intervals, i.e., the typical values of clinically meaningful acoustic and linguistic features derived from a reference population. This novel approach in the field of speech as a biomarker is inspired by the use of reference intervals in clinical laboratory science. Deviations of new speakers from this reference model are quantified and used as input to detect Alzheimer's and Parkinson's disease. The classification strategy explored is based on Neural Additive Models, a type of glass-box neural network, which enables interpretability. The proposed framework for reference speech characterization and disease detection is designed to support the medical community by providing clinically meaningful explanations that can serve as a valuable second opinion.
Soda-Eval: Open-Domain Dialogue Evaluation in the age of LLMs
Aug 20, 2024



Although human evaluation remains the gold standard for open-domain dialogue evaluation, the growing popularity of automated evaluation using Large Language Models (LLMs) has also extended to dialogue. However, most frameworks leverage benchmarks that assess older chatbots on aspects such as fluency and relevance, which are not reflective of the challenges associated with contemporary models. In fact, a qualitative analysis on Soda, a GPT-3.5 generated dialogue dataset, suggests that current chatbots may exhibit several recurring issues related to coherence and commonsense knowledge, but generally produce highly fluent and relevant responses. Noting the aforementioned limitations, this paper introduces Soda-Eval, an annotated dataset based on Soda that covers over 120K turn-level assessments across 10K dialogues, where the annotations were generated by GPT-4. Using Soda-Eval as a benchmark, we then study the performance of several open-access instruction-tuned LLMs, finding that dialogue evaluation remains challenging. Fine-tuning these models improves performance over few-shot inferences, both in terms of correlation and explanation.
ECoh: Turn-level Coherence Evaluation for Multilingual Dialogues
Jul 16, 2024Despite being heralded as the new standard for dialogue evaluation, the closed-source nature of GPT-4 poses challenges for the community. Motivated by the need for lightweight, open source, and multilingual dialogue evaluators, this paper introduces GenResCoh (Generated Responses targeting Coherence). GenResCoh is a novel LLM generated dataset comprising over 130k negative and positive responses and accompanying explanations seeded from XDailyDialog and XPersona covering English, French, German, Italian, and Chinese. Leveraging GenResCoh, we propose ECoh (Evaluation of Coherence), a family of evaluators trained to assess response coherence across multiple languages. Experimental results demonstrate that ECoh achieves multilingual detection capabilities superior to the teacher model (GPT-3.5-Turbo) on GenResCoh, despite being based on a much smaller architecture. Furthermore, the explanations provided by ECoh closely align in terms of quality with those generated by the teacher model.
On the Benchmarking of LLMs for Open-Domain Dialogue Evaluation
Jul 04, 2024
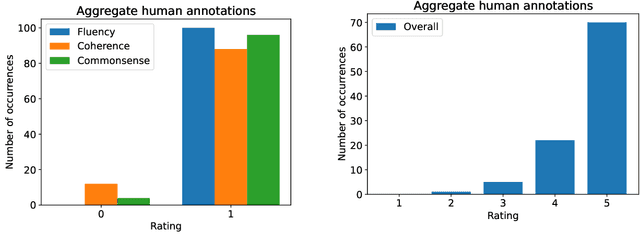
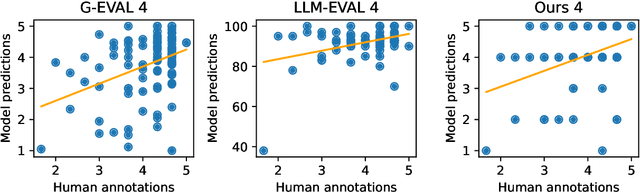
Large Language Models (LLMs) have showcased remarkable capabilities in various Natural Language Processing tasks. For automatic open-domain dialogue evaluation in particular, LLMs have been seamlessly integrated into evaluation frameworks, and together with human evaluation, compose the backbone of most evaluations. However, existing evaluation benchmarks often rely on outdated datasets and evaluate aspects like Fluency and Relevance, which fail to adequately capture the capabilities and limitations of state-of-the-art chatbot models. This paper critically examines current evaluation benchmarks, highlighting that the use of older response generators and quality aspects fail to accurately reflect modern chatbot capabilities. A small annotation experiment on a recent LLM-generated dataset (SODA) reveals that LLM evaluators such as GPT-4 struggle to detect actual deficiencies in dialogues generated by current LLM chatbots.
Improving Membership Inference in ASR Model Auditing with Perturbed Loss Features
May 02, 2024Membership Inference (MI) poses a substantial privacy threat to the training data of Automatic Speech Recognition (ASR) systems, while also offering an opportunity to audit these models with regard to user data. This paper explores the effectiveness of loss-based features in combination with Gaussian and adversarial perturbations to perform MI in ASR models. To the best of our knowledge, this approach has not yet been investigated. We compare our proposed features with commonly used error-based features and find that the proposed features greatly enhance performance for sample-level MI. For speaker-level MI, these features improve results, though by a smaller margin, as error-based features already obtained a high performance for this task. Our findings emphasise the importance of considering different feature sets and levels of access to target models for effective MI in ASR systems, providing valuable insights for auditing such models.